This blog focuses on setting up Aquaforest Searchlight for processing large number of documents in SharePoint. Firstly, we have to understand how Searchlight works. There are 2 main stages when processing a Searchlight library: the Audit stage and the OCR stage. Before explaining these 2 stages, let’s first clarify what is a Searchlight library. A Searchlight library is an object in Aquaforest Searchlight that can consist of either:
-
one or more SharePoint site collections, SharePoint sites, SharePoint document libraries and/or SharePoint lists. OR
-
one or more File System paths All Searchlight libraries are displayed in the Dashboard as shown below:
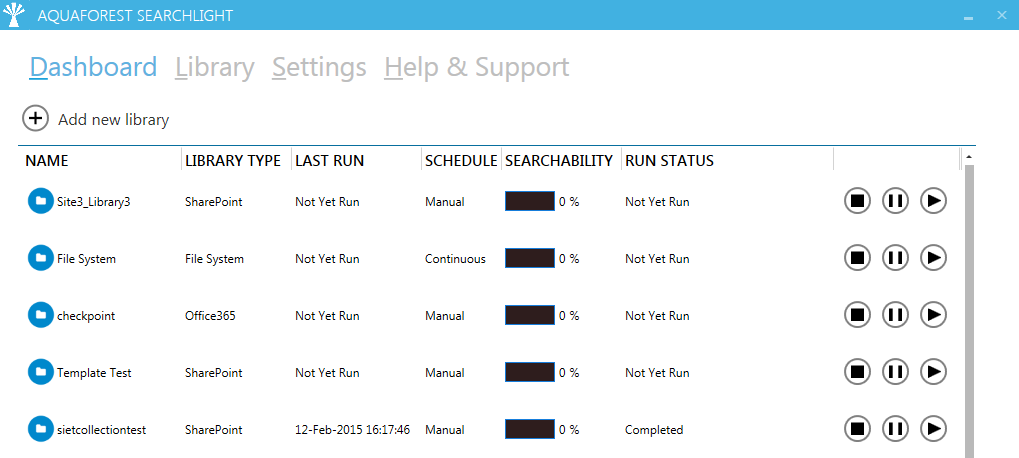
Figure 1: Searchlight libraries
A Searchlight library should not to be confused with a SharePoint library, which is a document library in SharePoint.
1. Audit and OCR stages
The Audit stage analyses each SharePoint site collection, site or document library/list in a Searchlight library and checks the searchability status (searchable, partially searchable and image-only) of each document in the library. See the following blog _for more explanation regarding different searchability statuses._The very first time a Searchlight library is run, Aquaforest Searchlight downloads each and every PDF document (and TIFF, if specified in the Document Selection rules) to a temp folder in the local machine where Searchlight is installed and checks their searchability status. The searchability status along with other information like modified date, created date, etc. of each document are stored in a SQLite database. After analysing all documents, Searchlight proceeds to select the documents whose searchability status match the Document Selection rules for the OCR stage.
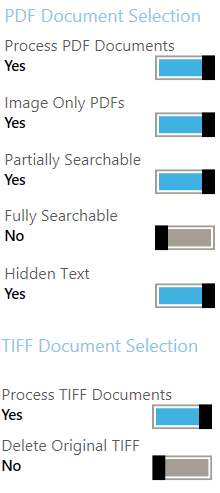
Figure 2: Document Selection rules
The selected documents are OCR’ed and those that were successfully OCR’ed are uploaded back to SharePoint. The new searchability status of each document is then updated in the SQLite database. Finally, all the downloaded and OCR’ed documents are deleted from the local machine. If new documents are added to a SharePoint document library that is contained in the Searchlight library and ran again, Aquaforest Searchlight will only download and process the new documents. The diagram below summarises how the Audit and OCR process works:
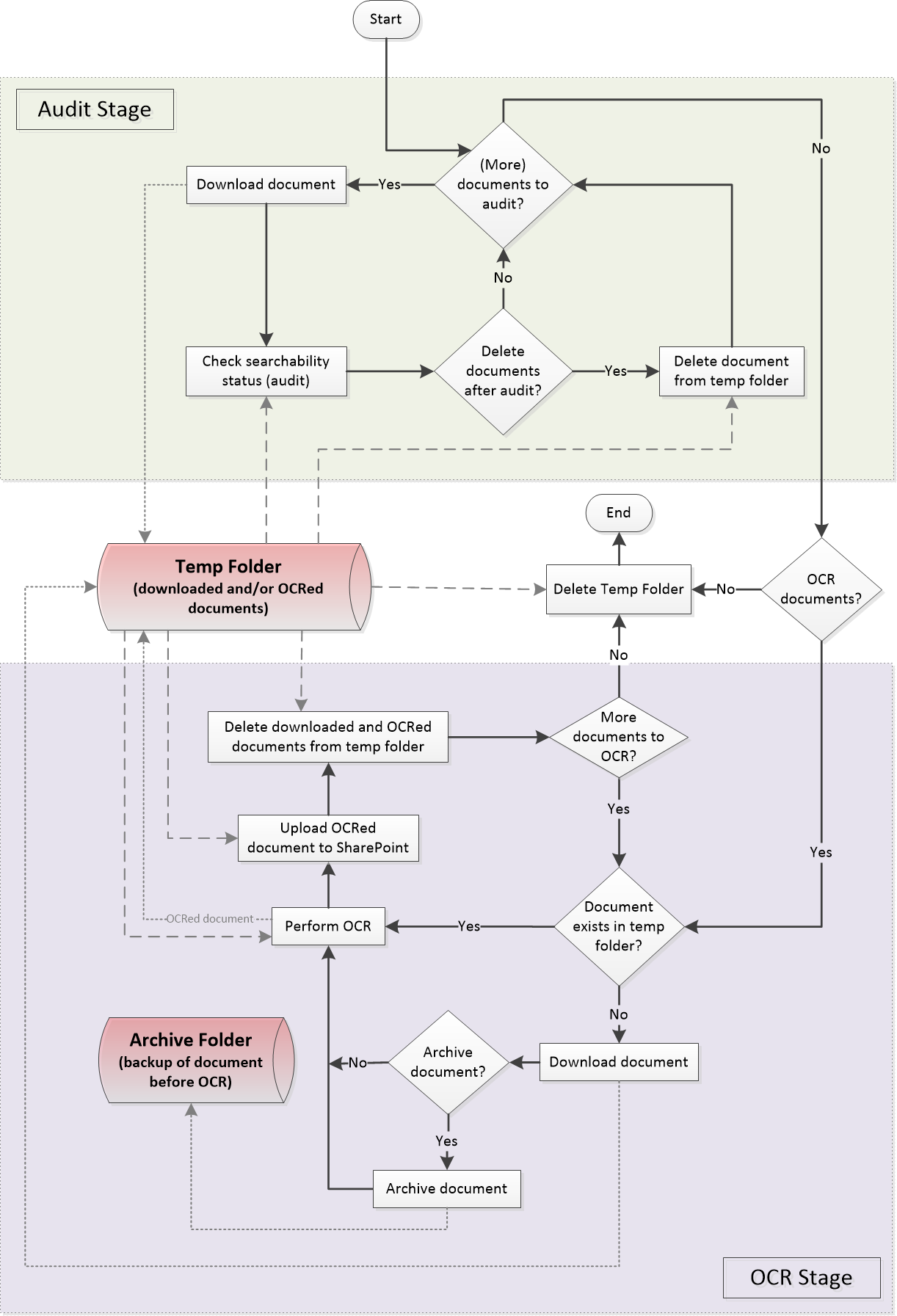
Figure 3: Audit and OCR Process
2. Processing large number of documents
Aquaforest Searchlight has to download the documents from SharePoint first before Auditing and/or OCRing them. However, if the Searchlight library being processed has a large number of documents, the local machine where Aquaforest Searchlight is installed needs to have enough hard-disk space to store the downloaded documents (both in the temp folder and the archive folder) and the OCR’ed documents and the records in the database; but what if storage space was an issue, especially when running the Searchlight library for the first time? The following sections describes the different options available to users to manage the processing of big libraries and improve performance.
2.1 Delete each document immediately after audit
From version 1.10 of Aquaforest Searchlight, documents are audited and/or OCRed as soon as they are downloaded. If the processing mode is set to “Audit and OCR” and there is enough space in the local computer, the same downloaded documents can be used for OCR after all documents have been audited. However, if space is an issue, each document can be deleted as soon as it has been audited and it will be downloaded again during the OCR process (see figure 3 above). To delete the documents after audit, the setting “deleteDocumentsAfterAudit” needs to be set to true in the Searchlight.config file.
2.2 Temp and archive folders
Another way to deal with hard-disk space issues is to change the temp location where all the documents are downloaded and OCR’ed to somewhere with more hard-disk space. The temp location can be modified by setting a new value to the “Temp Folder Location” in the Document Settings tab:
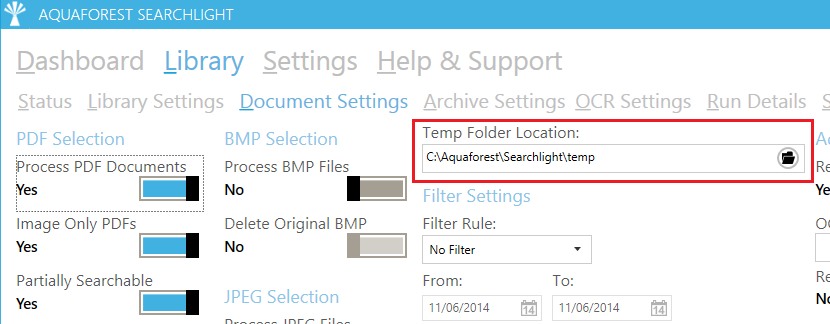
Figure 4: Temp Folder Location
Likewise, the archive location, where the original documents are backed up before they are OCR’ed, can be changed to somewhere with more space. The archive location can be modified through the Archive Settings tab:
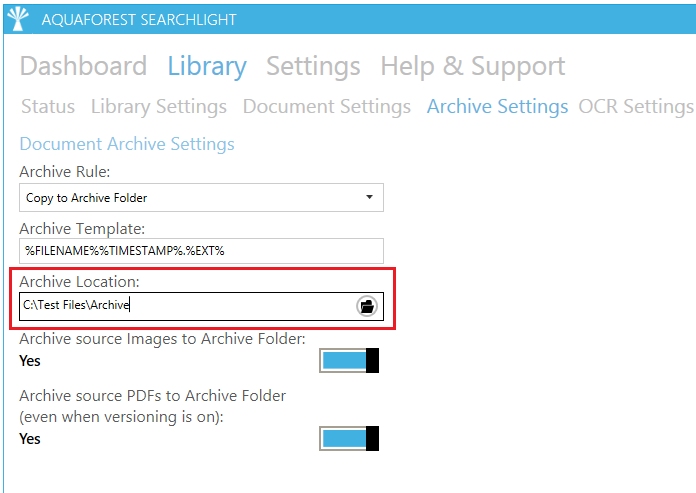
Figure 5: Archive Location
2.3 Fragmentation
However, other issues arise when processing a Searchlight library that has large number of documents (300, 000 +), such as download time and size of the library in the SQLite database, which can have a negative impact on the overall performance of Aquaforest Searchlight. In this scenario, the recommended approach is to fragment the library. For instance, consider the following site collection.
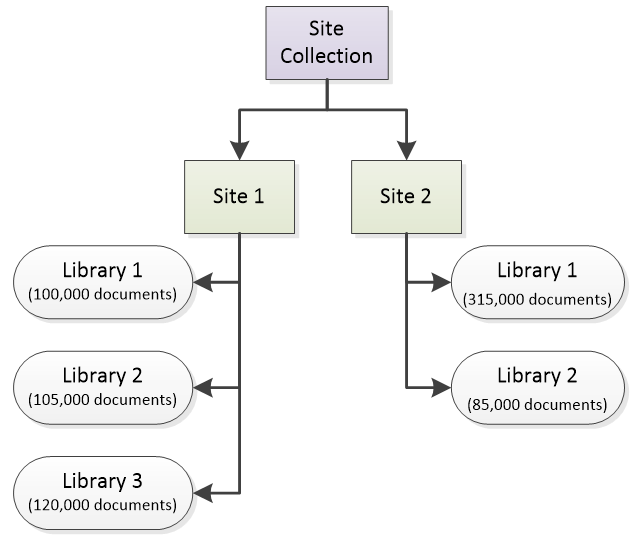
Figure 6: Site Collection Instead of adding the whole site collection (which has a total of 725,000 documents) to one Searchlight library as shown in Figure 7, fragment the library so that each one has approximately 300,000 documents each (Figure 8).
Figure 7: Normal library
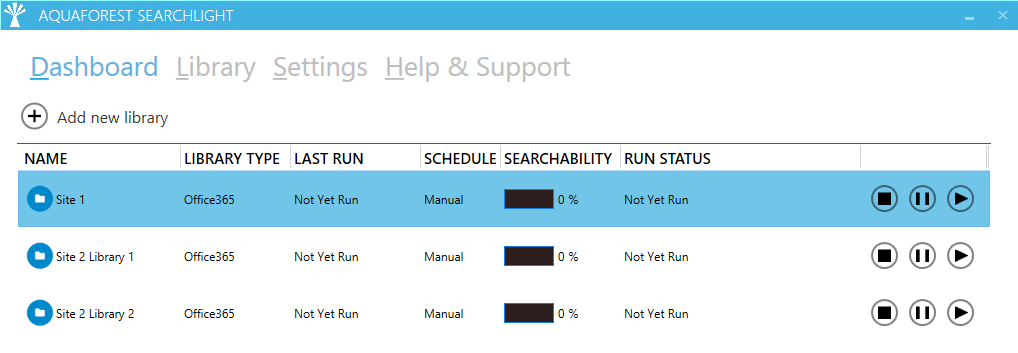
Figure 8: Fragmented libraries Each library can then be run at different times, either manually or by setting up a schedule. Contact support for more information and advice regarding fragmenting site collections.
2.4 Batch processing
Aquaforest Searchlight also has an option for processing documents in batches. However, this only affects the OCR stage. For batch processing, the library needs to be scheduled to run periodically between a start time and end time using the scheduler.
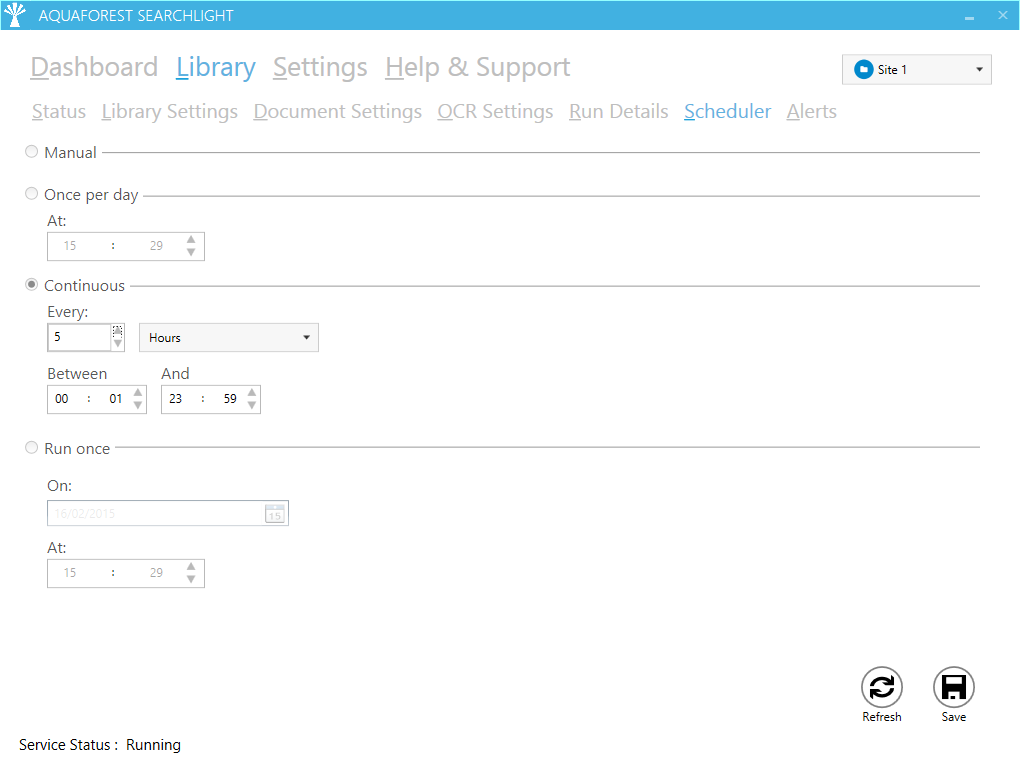
Figure 9: Scheduler
The number of documents to OCR per batch, i.e. during each scheduled run, is controlled by the “OCR Document Limit” setting.
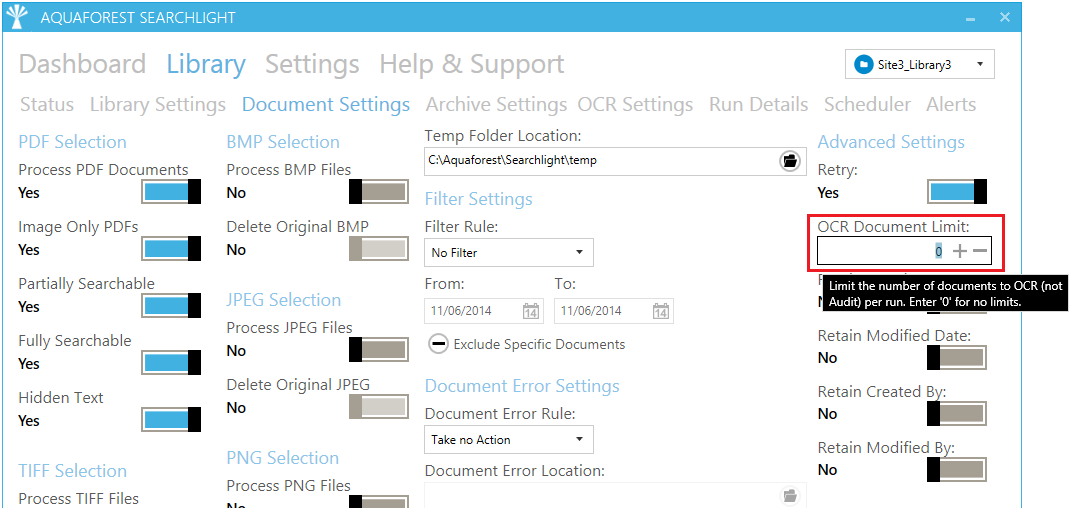
Figure 10: Batch Processing - OCR Document Limit
2.4 Parallel processing
Performance can also be improved using the multi-core option by allowing Aquaforest Searchlight to make full use of all processors available in computer. The current version (1.10) supports a maximum of 64 cores. In other words, 64 files can be processed (downloaded, analysed and OCR’ed) simultaneously, thus reducing processing time considerably. The number of cores available through the user interface is limited by the number of cores the computer running Aquaforest Searchlight has. For instance, if your license supports 64 cores and you only have 8 cores in your computer, you will only be able to process 8 documents simultaneously.
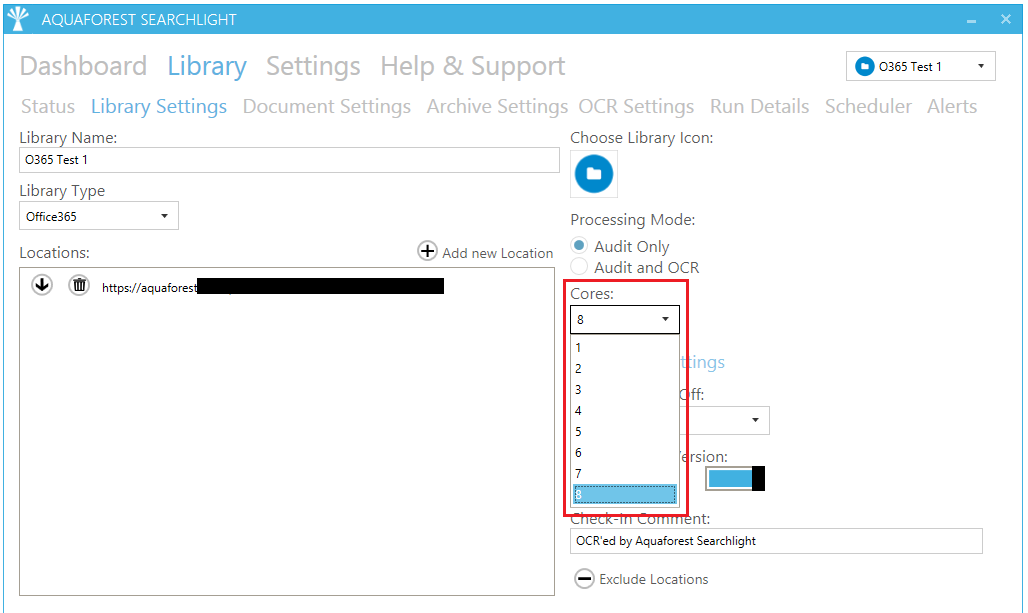
Figure 11: Parallel processing

Shrevin is a software engineer with a focus on Microsoft technologies and solutions, including SharePoint, Power Automate, and Azure. In his spare time, he enjoys hiking, trail biking, and watching movies.