In this article, we will outline how to use the Aquaforest PDF Connector for the Power Automate Platform to Get Name-Value Pairs from a mixture of image-only and text-searchable PDFs & populate them into Custom Metadata fields.
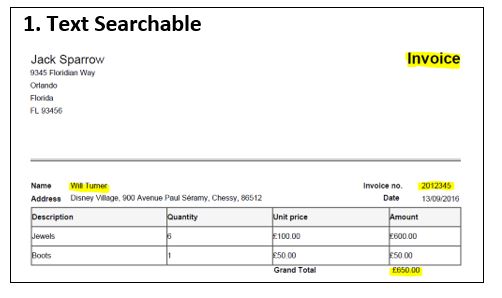
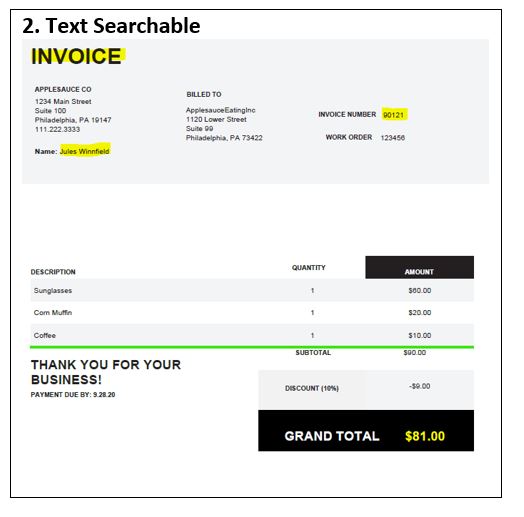

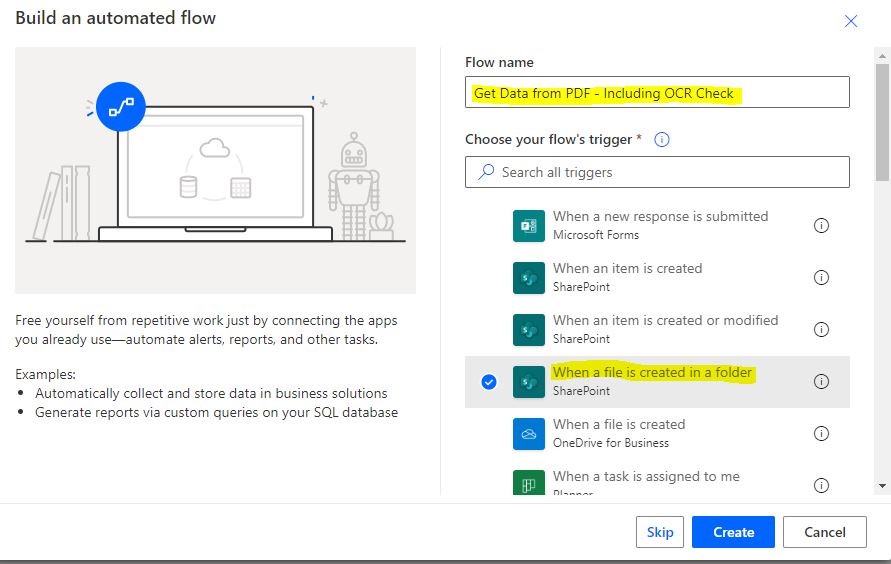
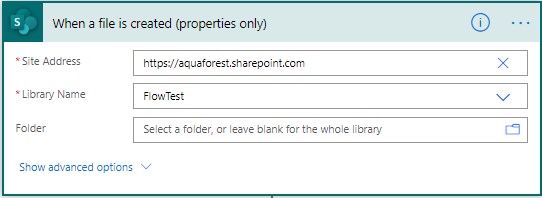
The first step is to define the trigger for our flow, in this example, we are going to Trigger the flow when an item gets created in Sharepoint & then using the Aquaforest “Get Data from PDF” to retrieve the Name-Value pairs before we populate into Custom Metadata Fields 1. Create a new Automated Flow, give it a name “Get data from PDF & including OCR Check & Select your Trigger “When a file is created in a folder”
-
Specify the Location,
-
-
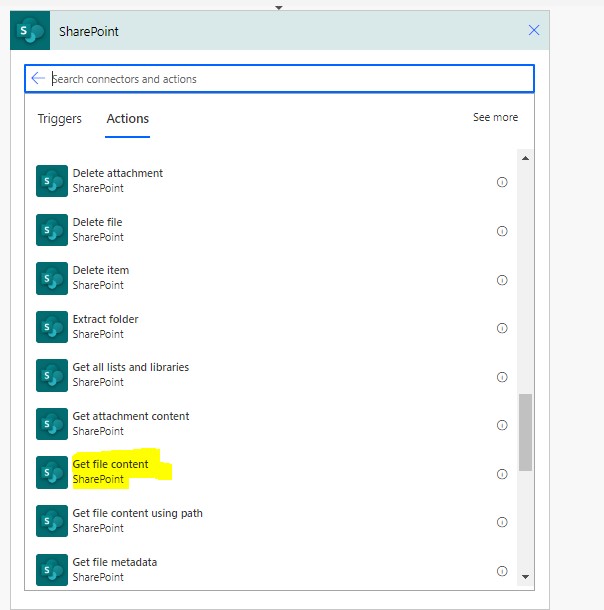
We then need to add a step to get the contents of the file
-
Specify the Site Address & also “Identifier”
-
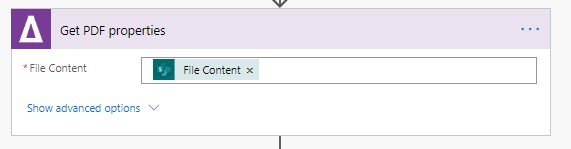
a. Add an “Aquaforest Get PDF Properties” Step
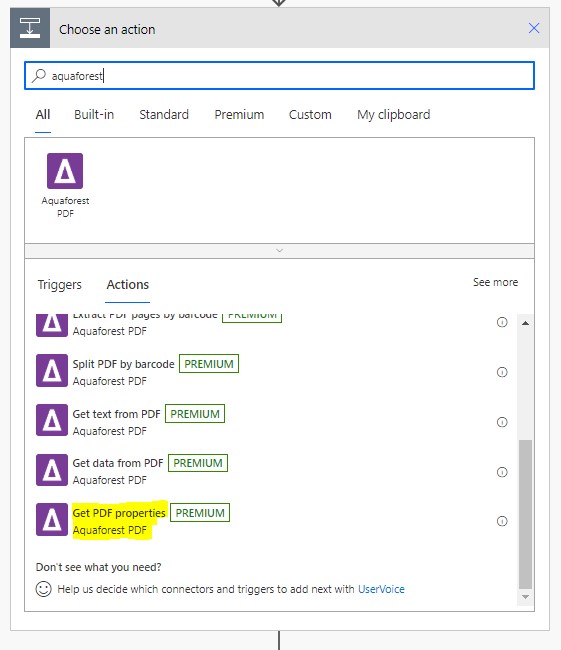
b.Select “File Content”
-
Add a “Condition” Step, “Is Searchable Is equal to True”
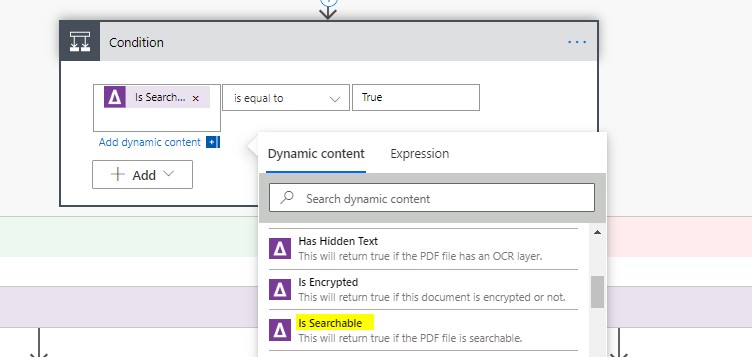
-
On the “No” Branch, add “Aquaforest OCR PDF or Images” step

-
In the Aquaforest OCR PDF or Images, add the following parameter a. “Source File Content” as “File Content” b. “Source Filename with Extension” as “Filename with Extention”
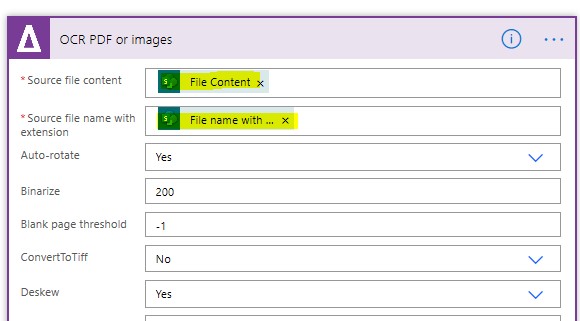
-
Then add a “Get Data from PDF Step” with the following Expected Keys
-
We then specify the following parameters, a. File Content: Aquaforest Processed file Contents (from the OCR Step) b. Expected Keys: Title, Name, Invoice Number & Grand Total
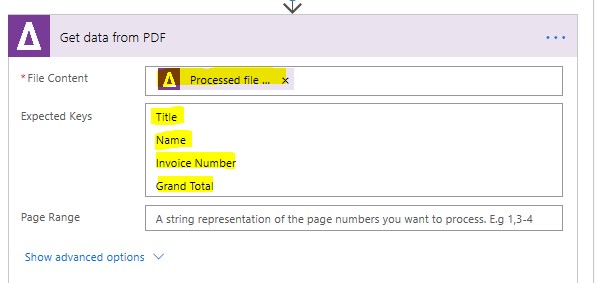
-
Then add a new step “Update File Properties” a. Enter the site Address & Library Name b. Add “ID” to identify the file you wish to update c. Fill in the 4 fields as per the screenshot below (Title, Full Name, Total & Invoice Number) from the Get Data from PDF Step.
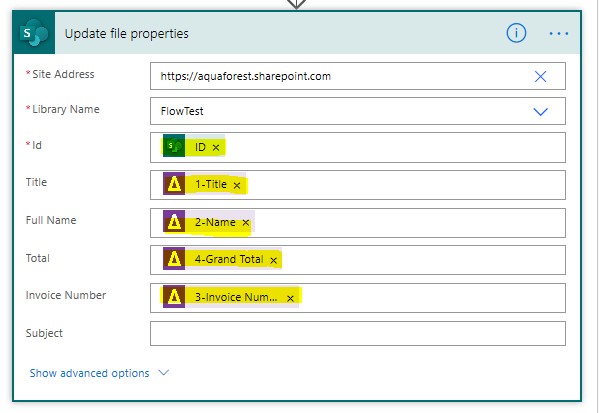
-
On the “Yes”; Branch add a “Get Data from PDF Step” with the following Expected Keys - We then specify the following parameters, a. File Content: Sharepoint File Content Step b. Expected Keys: Title, Name, Invoice Number & Grand Total
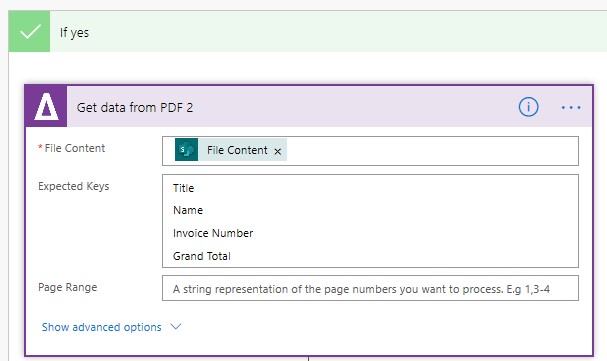
-
Then add a new step “Update File Properties” a. Enter the site Address & Library Name b. Add “ID” to identify the file you wish to update c. Fill in the 4 fields as per the screenshot below (Title, Full Name, Total & Invoice Number) from the Get Data from PDF Step.
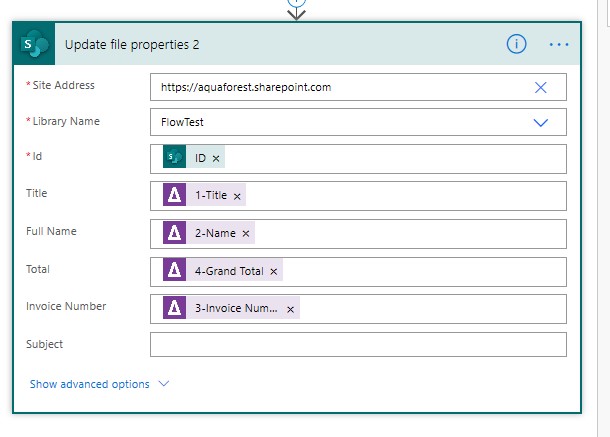
-
The whole flow should look something like this,
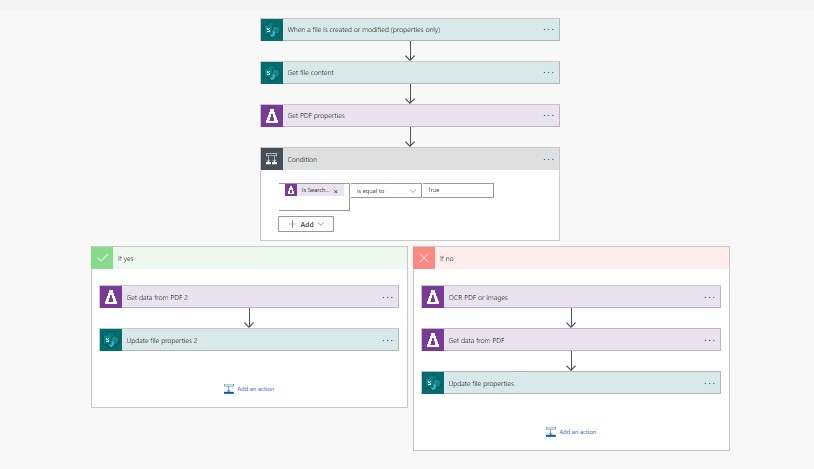
-
Once the flow runs you should see that all the named value pairs have been populated into custom Metadata fields as per the screenshot below.
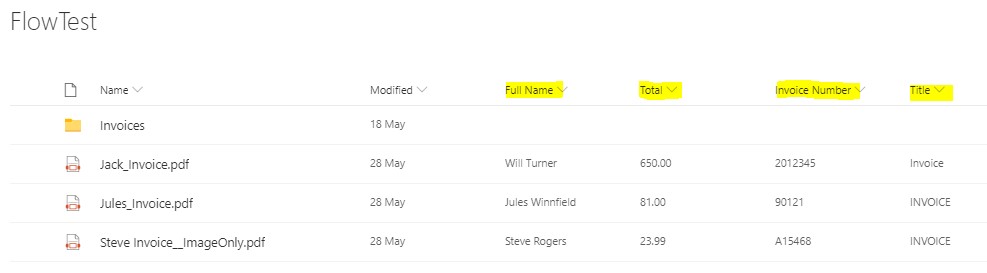

Neil established Aquaforest (later acquired by Nutrient) in 2001 to provide high-performance PDF, OCR, and SharePoint products to a worldwide market.