




How We Make Our CI Fast
Table of contents

Last year, I wrote about how fast Continuous Integration (CI) execution is crucial for high-performing teams that care about software quality. Today’s post will be a deep dive into the details of how we make the CI pipeline for PSPDFKit API fast.
Overview of the CI Pipeline
To talk about the efficiency of the CI pipeline, it’s first necessary to understand what it consists of. The primary goal of our CI pipeline is to ensure high code quality and to produce build artifacts for PSPDFKit API. To be more specific, for each opened pull request, we do the following:
- Run unit tests in Elixir via ExUnit (
unit-tests). - Run end-to-end tests via browser automation (
e2e-tests). - Perform dialyzer type checks (
dialyzer). - Perform Credo linter checks (
credo). - Perform formatting checks, via Elixir Formatter and Prettier for JavaScript files (
formatter).
These are what we actually want our CI pipeline to run (I tagged each step with a handy label that I’ll use to refer to them for the rest of this post).
How can we make sure they run as quickly as possible?
Identifying Common Dependencies
In my experience, the first step in optimizing the execution speed of the pipeline is to identify common work that two or more steps do, extract it to a separate step, and make it a dependency for steps that previously performed that work.
In our case, all of unit-tests, e2e-tests, dialyzer, and credo compile the source code of the PSPDFKit API Elixir application. So we’ll introduce a compile step that will perform that work, and the aforementioned steps will depend on it.
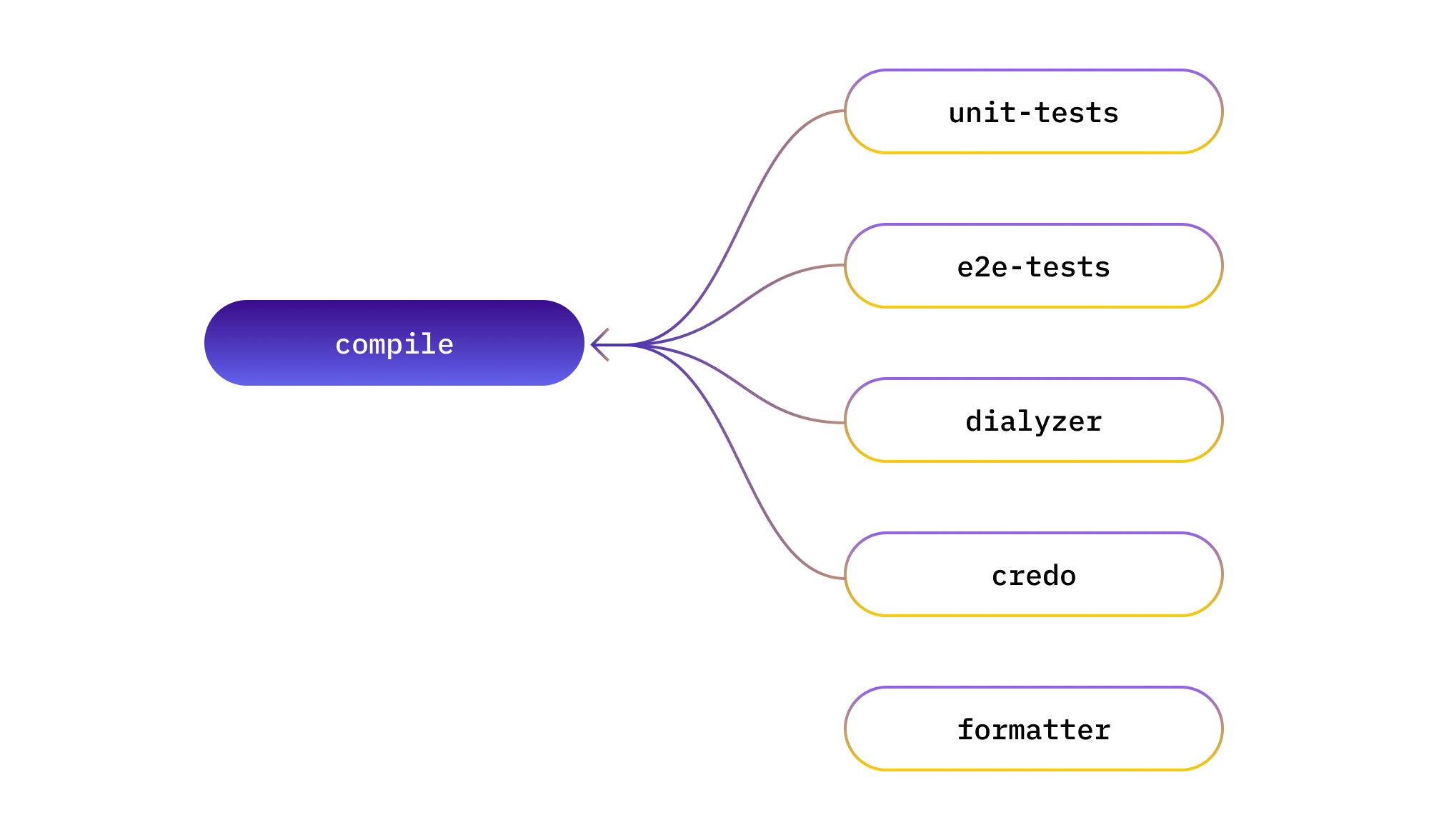
Great! Now we’ll compile the application only once, instead of four times. But… how do we implement this in practice?
Leveraging Docker and Buildkite
We use Docker heavily at PSPDFKit, especially for CI purposes. In the case of the PSPDFKit API CI pipeline, we’re using it to optimize the compilation itself, deliver the compiled application available to all steps that require it, and run the actual CI steps.
The Compilation Step
In essence, the compile step takes the source code, compiles it when building the Docker image, and pushes it to our internal Docker registry. Later, any step that requires the compiled application pulls the Docker image and runs the required commands inside that Docker image. We use Buildkite for running CI pipelines across PSPDFKit, and the whole process is straightforward to implement using the fantastic Docker Compose plugin(opens in a new tab). Here’s how the compile step definition looks:
label: ':docker: Build compiled application image'plugins: - docker-compose#v3.5.0: build: app config: api/ci/build/docker-compose.yml cache-from: - app:internal-docker-registry/api-compiled:<current-branch-name> - app:internal-docker-registry/api-compiled:latest image-name: <current-branch-name> image-repository: internal-docker-registryWe apply a few tricks to speed up the compilation step itself, outlined below.
- Each CI run for a pull request builds this Docker image and tags it with the current branch name.
- Each CI run for the main branch (run after every merge) builds the same image and tags it with the
latesttag. - During CI runs, we try to reuse the Docker cache(opens in a new tab) for the already built images using the
cache-fromdirective:- If the image for the current branch was built in the past (e.g. for a previous commit in the same PR), the Docker build cache from that image is reused.
- If not, the build cache for the latest build from the main branch is reused.
This small change ensures compilation is snappy if there were few changes compared to previous builds. For example, for builds where only the source code for our application changed, the compilation takes 5–10 seconds.
The Dockerfile
To make sure that as much of the build cache is reused as possible, the directives in the Dockerfile need to be written in the correct order. For all our Elixir applications, we follow pretty much the same recipe:
# 1. Fetch dependenciesCOPY mix.exs mix.lock ./COPY config/* config/RUN mix deps.get
# 2. Compile dependenciesRUN export MIX_ENV=dev && \ mix deps.compile && \ unset MIX_ENV
RUN export MIX_ENV=test && \ mix deps.compile && \ unset MIX_ENV
# 3. Compile the applicationCOPY . .
RUN export MIX_ENV=dev && \ mix compile --warnings-as-errors && \ unset MIX_ENV
RUN export MIX_ENV=test && \ mix compile --warnings-as-errors && \ unset MIX_ENVThis ordering ensures that:
- If the dependencies change, we fetch them again and recompile them along with the whole application.
- Recompilation of the application is necessary in cases where the application has a compile-time dependency on any of the dependencies it uses.
- If the static configuration changes, we fetch the dependencies and recompile them along with the whole application.
- Recompilation of dependencies and the application is necessary, because the configuration files may impact the compilation process itself (e.g. via compile-time configuration options).
- If the source code changes, we recompile only the application itself.
As you can imagine, in most cases, our pull requests update the source code and not our dependencies, which means that pretty much every CI build leverages the cache and compiles only the application itself.
You might have noticed that we compile the dependencies of the application twice — once for MIX_ENV=dev, and once for MIX_ENV=test. This is because different dependent CI steps in either of the two environments and building a separate image for each environment would balloon our Docker image storage costs.
The Final CI Steps
Now, for the actual steps we want to run on CI (remember those?), we leverage the Docker Compose Buildkite plugin once again. For example, the unit-tests step looks like this:
key: elixir-unit-tests label: ":elixir: Elixir unit tests" retry: automatic: true depends_on: - compile plugins: - docker-compose#v3.5.0: run: test pull: - test config: api/ci/configurations/unit-tests.ymlWe specify that this step depends on the compile step we looked at previously, and that when this step is run, the latest available Docker image for this branch is pulled (that’s the function of the pull field).
The Docker Compose configuration file this step refers to looks like this:
version: '3.8'
services: test: image: app:internal-docker-registry/api-compiled:<current-branch-name> entrypoint: ['/bin/bash', '-c'] command: ['mix test']It defines a test service that we run in a step above. This service uses the Docker image we built in the compile step, and it runs the mix test command inside. Since the application is already compiled for the test environment in that image, we don’t spend any extra time on compilation! 🎉 Every other CI step that requires the compiled application image looks very very similar to this configuration.
The bonus of keeping your CI configuration mostly contained within Docker Compose files is that it’s much easier to reproduce whatever CI is running locally. Here, running the tests via Docker would be as simple as docker compose run test. This is especially useful if your application requires third-party dependencies to run (e.g. a database or an external cache).
Speeding Up Your CI
The strategy described in this post might seem specific to Elixir programming, Docker, and Buildkite. However, while these are our tools of choice, you can speed up your CI by using the exact same principles we applied:
- Identify common work and perform it only once.
- Cache intermediate build artifacts and scope them to branches of your source code for better reuse.
- Order the commands in your build process in a way that invalidates the cache as rarely as possible.
And that’s it! While some tools and languages make it easier to apply one principle more than the other, we’ve been using this system for the past year with great success. And if you haven’t seen it yet, check out our post on continuous deployment and how we make our deployments snappy!


