Extract PDF Form Fields to SharePoint
In this guide learn how to export PDF form data in SharePoint. It is now possible to take a typical PDF form, being it a government issued W9, or a form specific to your industry or organization, and use our existing conversion facilities to extract forms data in the FDF, XFDF and XML standards. You can use our standard sample code for the platform of your choice in combination with our Muhimbi Document Converter Services product.

To extract, you can use our existing conversion facilities, through API, Nintex Workflow, or SharePoint Designer and pass in a PDF file containing form data. You can select FDF, XFDF or XML as the output format and the form data is extracted in the desired format. Once you have the extracted data, you can use it in any way that it is required.
You can save it in a MS SharePoint column, insert it into a database, make a decision in your code based on the value of a field, and more.
Note: Muhimbi Document Converter version 10.1.2 and above supports the AcroForms standard, which has broad support across the PDF Market. Muhimbi Document Converter version 10.2 and above supports the XML Forms Architecture standard.
Using Nintex Workflow to Extract MS SharePoint Form
This example gives you a brief idea on how this can be used in the real world. This example uses Nintex Workflow. This is a very high-level example, which assumes you are familiar with how to create workflows and parse XML. Introduction to Nintex Workflows is beyond the scope of this article.
The Muhimbi Document Converter must be deployed in your environment, and the Nintex Workflow Integration should have been activated. To perform the extraction, you can add Muhimbi’s ‘Convert Document’ action to the workflow. You can fill in the fields and make sure you set the Output Format to something that is relatively easy to ‘parse’, in this example XFDF. In this particular case we capture the Output Item ID, which is the ID of the generated XFDF file. We need this so we can read the content of the generated file in the next step.
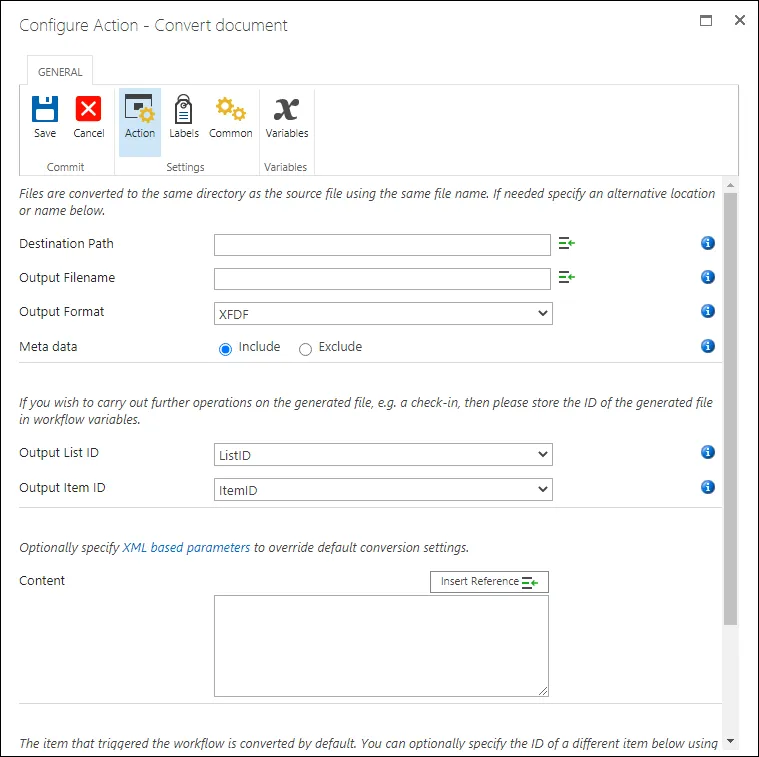
The ‘Convert Document’ action generates XFDF, an XML based format specific to the form fields defined in the source PDF file. An example can be found below:

In the next step we want to extract data from the generated XFDF file, so we can use it in the rest of our workflow. You can insert Nintex’ standard ‘Query XML’ action and specify the ItemURL, which is based on the Item ID captured in the previous step. Then use the XPath builder to generate a path to the field to extract.
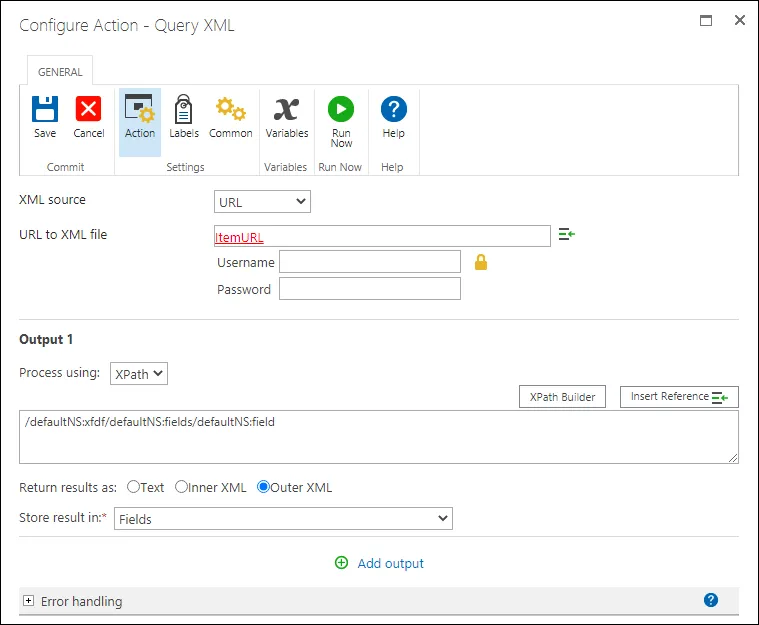
Note: Please ignore the XPath in the screenshot, as it is document specific and will be different for your particular scenario.
Additional Resources
- Automatically populate PDF Forms with SharePoint List Data(opens in a new tab)
- Extract PDF Forms Data (FDF, XFDF, XML) using SharePoint(opens in a new tab)