Dynamic document redaction: How to automate sensitive data removal with an SDK
In today’s data-driven world, protecting sensitive information is more critical than ever. Whether in legal documents, medical records, or financial reports, the need for effective redaction is paramount to ensure compliance with regulations like GDPR and HIPAA and to safeguard privacy. However, manual redaction can be error-prone and time-consuming. Enter Nutrient SDK — a powerful solution that automates redaction tasks dynamically and efficiently.
This blog post will explore how Nutrient simplifies document redaction, making it faster, more accurate, and scalable.
Understanding document redaction
Document redaction is the process of permanently removing sensitive information from documents to ensure privacy, security, and compliance with regulations. A robust PDF redaction library ensures that — unlike simple obscuration methods, such as blacking out text — redaction completely removes data, preventing it from being restored or accessed by unauthorized individuals. This distinction is crucial for protecting sensitive information and maintaining document integrity.
The primary goal of redaction is to protect privacy and ensure compliance with laws like the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA). These laws mandate the removal of personal data to avoid privacy violations. Industries such as healthcare, legal, financial, education, and government rely on redaction to safeguard sensitive data, including personally identifiable information (PII), financial details, and classified information.
Failure to follow proper redaction practices can lead to significant privacy breaches and legal consequences, including fines and penalties. Organizations must implement consistent and reliable redaction methods to avoid exposure of sensitive information. Traditional manual redaction methods are labor-intensive and prone to mistakes, but dynamic redaction powered by SDKs like Nutrient automates this process, offering more reliable, programmatic solutions.
By ensuring sensitive data is permanently removed from documents, organizations maintain the confidentiality of information and comply with data protection regulations. Redaction is critical for safeguarding sensitive details and avoiding unauthorized access, especially in legal and government documents.
Learn more about redaction in our introduction to redaction guide.
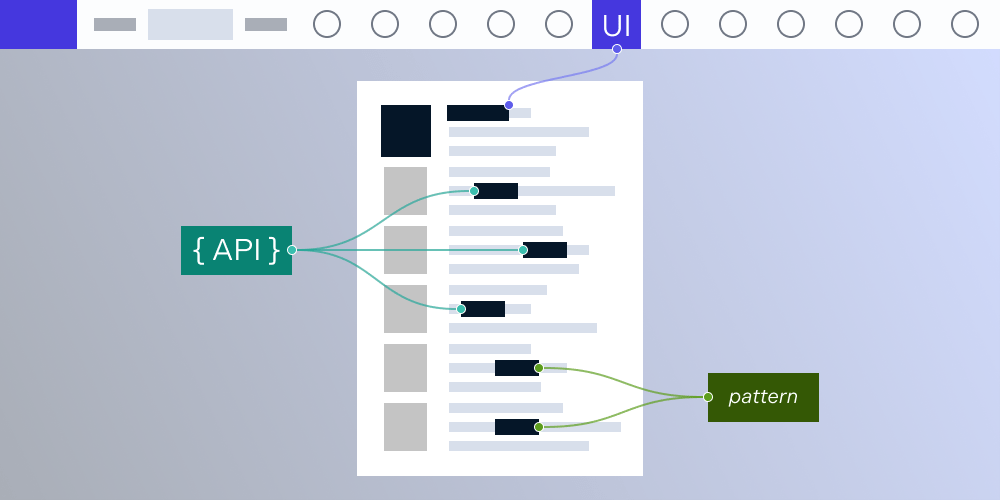
Steps to redact a PDF document with Nutrient
Nutrient makes redaction efficient by automating the two-step process:
-
Marking for redaction — Nutrient allows you to create redaction annotations that mark the areas to be redacted without yet removing content.
-
Applying the redaction — Once the annotations are set, Nutrient permanently removes the marked content, ensuring no sensitive data remains visible or accessible.
With Nutrient, you can automate the identification of sensitive information using custom regex patterns or preset redaction patterns, significantly speeding up the process.
Key features of Nutrient SDK for redaction
Programmatic redaction
Nutrient enables developers to automate redaction tasks through a programmatic approach. By leveraging APIs, you can efficiently redact sensitive data across multiple documents. This eliminates the need for manual intervention and ensures consistency.
For more information, refer to our programmatic redaction guide.
Search and redact
Targeted redaction is made easy with Nutrient’s search and redact functionality. This feature enables you to locate specific terms or patterns within documents and redact them dynamically.
Learn more in our search and redact guide.
Check out the Nutrient demo to see search and redact in action.
Built-in redaction UI
Nutrient also offers a customizable built-in redaction UI for those who prefer a visual approach. This feature allows users to manually select and redact data while maintaining the flexibility to integrate with automated workflows.
Learn more in our built-in redaction UI guide.
Smart redaction
Nutrient’s smart redaction takes automation to the next level by intelligently identifying and redacting sensitive data based on its context. Using AI-driven analysis and preset patterns, this feature eliminates the need for manually locating sensitive information, saving time while ensuring accuracy.
-
Contextual recognition — Automatically detects sensitive data, such as names, credit card numbers, or custom patterns, even when context varies.
-
Preset and customizable rules — Leverage built-in patterns or define your own custom rules for tailored redaction.
-
Batch redaction — Efficiently handle large volumes of documents without compromising precision.
Learn more about smart redaction in our corresponding guide.
Advanced techniques for redacting sensitive information
For organizations handling large volumes of sensitive data, advanced redaction techniques are essential for improving both efficiency and accuracy. Tools like regular expressions (regex), preset patterns, and automated redaction with SDKs provide powerful solutions to streamline the process.
Automating redaction with SDKs
Automating redaction with SDKs offers significant advantages, especially for organizations that need to redact large volumes of documents regularly. SDKs like Nutrient can quickly identify patterns and remove sensitive content, enhancing both the speed and accuracy of the redaction process.
The Nutrient SDK provides robust redaction functionalities that seamlessly integrate into existing workflows. It helps organizations consistently and accurately redact sensitive information across all documents, reducing human error and improving efficiency. Automated redaction is crucial for handling large amounts of sensitive data while ensuring compliance and privacy.
Using regular expressions for redaction
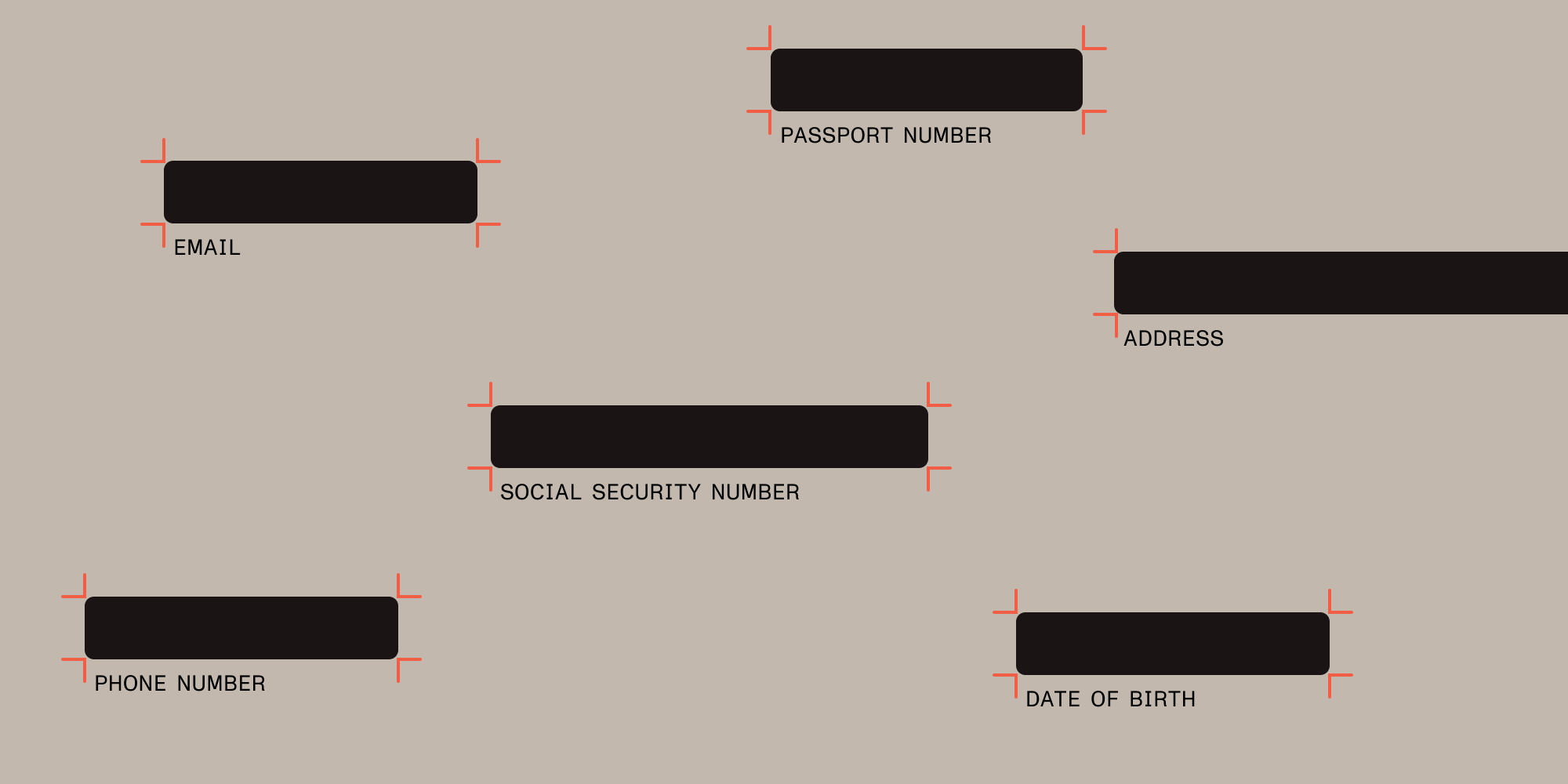
Regular expressions (regex) are powerful for identifying specific patterns within text, such as phone numbers, email addresses, and Social Security numbers. By configuring regex patterns, the redaction process can be automated, ensuring sensitive information is accurately located and redacted without human error.
SDKs like Nutrient enable users to automatically create redaction annotations based on custom regex patterns, facilitating quick and precise identification of sensitive data. This feature enhances the redaction process and overall efficiency. Built-in regex patterns can expedite identifying and removing commonly sensitive information, such as personal identifiers.
Refer to our redact regex patterns guide to learn how to use regex.
Preset patterns
Nutrient also offers built-in preset patterns for detecting and redacting common types of sensitive information, such as:
-
Credit card numbers
-
Email addresses
-
Social Security numbers (SSNs)
These preset patterns simplify the redaction process for frequently encountered data types, enabling faster and more reliable redaction without the need for custom configurations.
Explore preset patterns in our redact preset patterns guide.
Security and comprehensive redaction
Redaction isn’t merely a process of obscuring sensitive information; it involves permanently removing visible text, graphical content, annotations, comments, and markup intersecting the redacted areas. This ensures sensitive data is completely removed from a document, leaving no trace behind.
However, redaction doesn’t address certain aspects, such as metadata (PDF title, author), embedded content and attached files (like XMP), and hidden layers or text. Without addressing these elements, documents may still contain sensitive information that can pose a security risk.
To ensure comprehensive security, redaction should be combined with sanitization. Sanitizing a document eliminates hidden data, metadata, and other potentially sensitive elements that redaction alone might miss. By adopting both redaction and sanitization, organizations can ensure documents are fully secure before sharing or distributing them, mitigating the risk of data breaches, and ensuring privacy.
Conclusion
In conclusion, document redaction is essential for protecting sensitive information and ensuring compliance with privacy regulations. Combining redaction with sanitization further enhances data security.
Discover how Nutrient SDK can streamline your workflow — try the demo today, or contact our Sales team for tailored solutions. Start protecting your sensitive information with Nutrient SDK now.
FAQ
What is document redaction?
Document redaction is the process of permanently removing sensitive information from documents to ensure privacy and compliance with regulations like GDPR and HIPAA.How does Nutrient SDK simplify redaction?
Nutrient SDK automates redaction tasks, allowing you to mark and permanently remove sensitive data efficiently, using APIs, regex patterns, and built-in tools.Can I customize redaction rules in Nutrient SDK?
Yes. Nutrient SDK supports both preset patterns and custom rules, allowing users to tailor the redaction process to specific needs.What are the benefits of using automated redaction?
Automated redaction saves time, reduces errors, and ensures consistent removal of sensitive data across large volumes of documents.Is redaction alone enough to secure documents?
No. Redaction removes visible sensitive data, but sanitization is also needed to eliminate hidden metadata, annotations, and embedded content for full security.
Hulya is a frontend web developer and technical writer at Nutrient who enjoys creating responsive, scalable, and maintainable web experiences. She’s passionate about open source, web accessibility, cybersecurity privacy, and blockchain.