




PDF syntax 101: Understanding PDF Object Types
Table of contents

In this article, we’ll cover some aspects of how a PDF is structured internally and provide an overview of some of the building blocks the PDF format consists of. The PDF format is composed of various objects organized and indexed within the file, enabling efficient data retrieval and display in PDF viewers.
Everything about the structure of a PDF is covered in the PDF Specification, although sometimes the PDF spec might be a bit vague, or the actual behavior, even in Adobe’s products, might differ slightly in the actual implementation. So when parsing a PDF, you’ll need to adjust for some edge cases and parse some things loosely, so as to not strictly reject everything that varies from the spec.
Since Nutrient already handles parsing and interpreting PDF files, even in the weirdest of edge cases, you don’t have to manually handle PDFs. But if you’re still interested in how a PDF looks under the hood and how the visual page representations are created, (be my guest and) read on.
Introduction to PDF File Format
The Portable Document Format (PDF) is a versatile file format developed by Adobe in the 1990s. Designed to represent documents in a manner independent of application software, hardware, and operating systems, PDF files have become a staple for sharing and archiving information. The PDF file format ensures that documents appear the same on any device, preserving the layout, fonts, and graphics. This fixed-layout format is ideal for presenting information consistently, making it a popular choice for everything from official reports to eBooks. The structure and content representation of PDF files are governed by a set of rules and conventions, ensuring uniformity and reliability across different platforms.
File structure
This is what a simple PDF with one page and the text “Hello PSPDFKit” looks like when shown in raw text:
%PDF-1.71 0 obj<< /Type /Catalog /Pages 2 0 R >>endobj2 0 obj<< /Type /Pages /Kids [ 3 0 R ] /Count 1 >>endobj3 0 obj<< /Type /Page /Parent 2 0 R /MediaBox [ 0 0 595 842 ] /Resources 4 0 R /Contents 5 0 R >>endobj4 0 obj<< /ProcSet[ /PDF /Text ] /Font <</Font1 << /Type /Font /Subtype /TrueType /BaseFont /Helvetica >> >> >>endobj5 0 obj<< /Length 55 >>streamBT /Font1 35 Tf 1 0 0 1 170 450 Tm (Hello PSPDFKit) TjETendstreamendobj
xref0 60000000000 65535 f0000000009 00000 n0000000062 00000 n0000000125 00000 n0000000239 00000 n0000000343 00000 ntrailer<< /Root 1 0 R /Size 14 >>startxref382%%EOF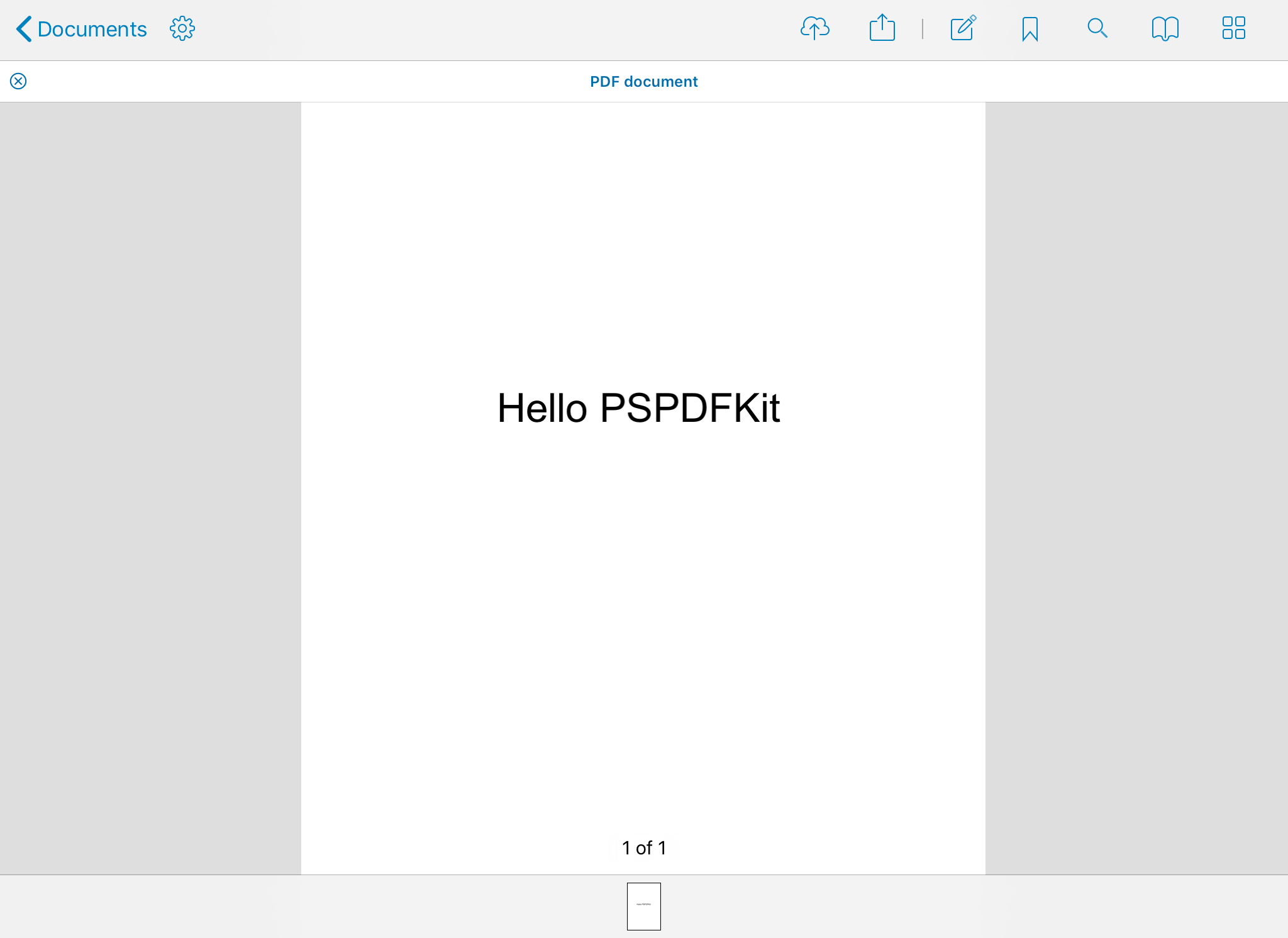
While this example might look like PDFs are text-based documents, this impression is false, since PDFs are binary documents.
Header and Trailer
A PDF file is composed of several key components: the header, body, cross-reference table, and trailer. The header, located at the beginning of the file, contains essential information about the PDF version and the document’s creator. This sets the stage for the rest of the file’s structure. At the opposite end, the trailer plays a crucial role in organizing the document. It includes the location of the cross-reference table and the root object, which is pivotal for the document’s structure. The cross-reference table itself is a vital part of the PDF file format, mapping object numbers to their specific locations within the file. This mapping allows for random access to objects, enabling quick retrieval and efficient navigation within the document.
PDF objects
A PDF consists of so-called objects that can have varying types, like null, Boolean, integer, real, name, string, array, dictionary, and stream.
These objects can be referenced either directly or indirectly in the file. Direct objects are placed inline where they are used, while indirect objects are referenced and placed somewhere else inside the document.
Direct object reference
Direct objects are constructed inline, directly in the place where they are used.
This snippet shows how to use a font as a direct object:
<< /ProcSet[ /PDF /Text ] /Font <</Font1<</BaseFont/Helvetica/Subtype/TrueType/Type/Font>> >> >>Indirect object reference
Indirect objects are referenced and placed somewhere else inside the document. This requires PDF viewers to look the actual object up.
Indirect objects are defined in the PDF starting with their unique ID, an incrementing positive number, followed by a generative number, which is usually 0, along with the obj and endobj keywords.
This snippet shows how to define and use a font as an indirect object:
3 0 obj<</Name/Font1/BaseFont/Helvetica/Subtype/TrueType/Type/Font>>endobj
4 0 obj<< /ProcSet[ /PDF /Text ] /Font <</Font1 3 0 R >> >>endobjDocument Catalog and Page Tree
At the heart of a PDF file lies the document catalog, the root object that serves as the gateway to the document’s contents. The document catalog contains references to other objects that define the structure and content of the PDF. One of the most important structures referenced by the document catalog is the page tree. The page tree is a hierarchical structure that organizes the pages of the document. Each page in the PDF is represented by a page object, a dictionary that includes references to the page’s contents, such as text, images, and annotations. The page tree is typically implemented as a balanced tree, ensuring efficient access and navigation, but it can also be a simple array of pages in smaller documents.
Cross reference
Now the question arises: How does a PDF viewer look up where an indirect object is referenced? This is done via the cross reference table.
You might have noticed that at the bottom of the PDF is the startxref keyword. Since PDFs are read backward, from the bottom to the top, this keyword is defined at the bottom of the PDF rather than the top. The number after startxref states at which byte the cross reference (xref) table starts:
startxref382The actual cross reference table defines the location for every object in the PDF:
xref0 60000000000 65535 f0000000009 00000 n0000000062 00000 n0000000125 00000 n0000000239 00000 n0000000343 00000 nThe first line shows that the table contains the declaration for six objects. In addition to the location of every object in the document, it’s necessary to have an empty 0 object at the top. Since our example PDF has five objects, the cross reference table lists the location of six objects (including the empty 0 section). This makes it easy for PDF viewers to directly jump to the defined object without having to parse the entire document.
Learn more
In this article, we outlined some of the basic principles of how a PDF is structured internally, along with discussing how content that is rendered on a document page is defined and specified. To learn more about rendering in Nutrient or PDFs in general, head over to our guide about document rendering.
FAQ
A PDF consists of objects like null, Boolean, integer, real, name, string, array, dictionary, and stream, which form the building blocks of the document structure. The document structure of a PDF includes these objects and highlights how they collectively form the logical outline and physical layout of the document.
Indirect objects are referenced and placed elsewhere in a PDF document and require PDF viewers to look them up.
PDF viewers use a cross-reference table, which lists the locations of objects, enabling the viewer to jump directly to the object.
The cross-reference table maps object locations in the PDF, making it easy for the viewer to access them without parsing the whole file.
PDFs are typically read backward, from bottom to top, with the startxref keyword located at the bottom, indicating the starting point of the cross-reference table.


