Unlocking PDF processing with content extraction
Nutrient Document Automation Server (DAS) Content Extraction (formerly known as Kingfisher) provides a set of operations for processing PDF files. It includes splitting, extracting pages, extracting text, and renaming files based on the content of the files. DAS Content Extraction also provides the ability to set the security, metadata, and other attributes of a PDF document.
What makes DAS Content Extraction stand out is the ability to perform split, extract, and rename operations based on text or barcodes found in zones or coordinates in a PDF page. DAS Content Extraction can use optical character recognition (OCR) to extract text data from image PDF files or pages.
System requirements
| Requirement | Value |
|---|---|
| Supported operating systems | Windows 10 (64bit) Windows 11 Windows Server 2012 (64bit) Windows Server 2016 Windows Server 2019 Windows Server 2022 |
| Supported SharePoint versions | SharePoint Online (Office 365) SharePoint Server 2019 SharePoint Server 2016 SharePoint Server 2013 SharePoint Server 2010 |
| Disk space | 450 Mb |
| .NET framework | 4.7.2 |
Installation
DAS Content Extraction requires installation by a user with administrator privileges.
The installer will guide you through the process of setting up DAS Content Extraction.
User permissions
The logged-in user for the user interface (UI) and the service user require full control of the following folders under the Kingfisher installation folder:
- Conditions
- License
- Logfiles
- Status
- Temp
In addition, the user(s) will require full control of the following files in the bin folder:
Kingfisher.ConfigKingfisher.Service.exe.config
Service user
When DAS Content Extraction is installed, its service logs on as the local system account. This is generally suitable for installations where the files being processed are present on the installation machine or are stored in SharePoint (online or on-premises).
Windows Server 2019 machines have slightly more restrictive permissions; ensure the service user can access the locations listed under the User permissions section above.
If the files are to be referenced via Universal Naming Convention (UNC) paths, an account with the required permissions on those paths will need to be created.
Log on to the computer as a user with administrator permissions.
Start the Services app from the Control Panel, or search from the Windows task bar for Services and launch the Services app.
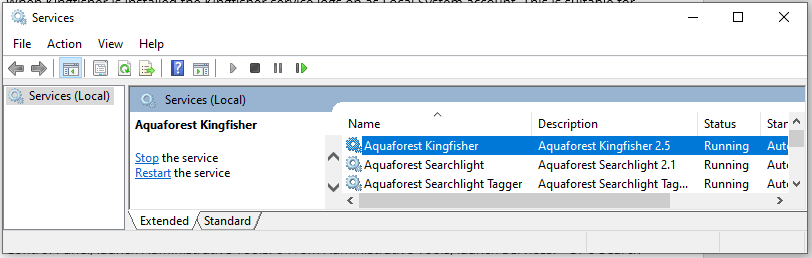
Find the DAS Content Extraction service, and right-click and select the Properties option.
Select the Log On tab.
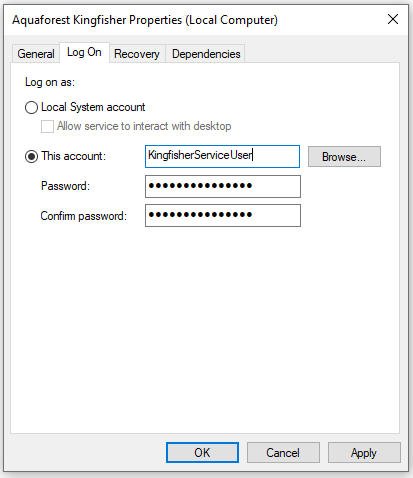
Enter the username and password and click OK.
For the service to use the new credentials, it must be restarted. Right-click the DAS Content Extraction service and select Restart.
Licensing and purchasing
From 31 March 2022, DAS Content Extraction (Kingfisher) is only available as a subscription product.
A subscription license will need to be renewed annually and comes with support and maintenance coverage (SMC) for the duration of the subscription.
When a license is purchased, the relevant subscription license key will be issued for use with the product. This can be entered using the Options tab of the graphical user interface (GUI). There’s no need to download another version of the software.
The SMC includes support by email, telephone, or remote session, and it includes free upgrades for its duration.
Existing permanent DAS Content Extraction 2.5 licenses will remain valid and continue to function as permanent licenses.
Additional SMC for existing permanent licenses will continue to be available for version 2.5.
Trial licenses are fully functional, but all generated PDF files will have the Low-Code Solutions trial stamps on them, and text extraction is limited to the first three pages.
Version breakdown
| Available features | Standard | Professional | Server |
|---|---|---|---|
| Use cases | Smart PDF splitting and renaming | Smart PDF page extraction, splitting, and renaming. | Automated smart PDF page extraction, splitting, and renaming. |
| Split PDF by content, barcode, or page ranges | ✔ | ✔ | ✔ |
| Rename PDF by content or barcode | ✔ | ✔ | ✔ |
| Extract PDF pages by content or barcode | ✔ | ✔ | ✔ |
| Includes optical recognition for processing image PDF files | ✔ | ✔ | ✔ |
| Graphical user interface | ✔ | ✔ | ✔ |
| Process files in SharePoint | ✔ | ✔ | ✔ |
| Extract PDF text and data to CSV, Excel, or text files | ✔ | ✔ | |
| Command-line interface | ✔ | ||
| Automated scheduling | ✔ | ||
| Number of cores supported | 1 | 1 | 4 |