Enhanced cloud OCR capabilities for text recognition
The optional Cloud OCR module extends Document Automation Server (DAS) with additional OCR engines from Microsoft and Google, the main advantages of these OCR engines is their Handwriting recognition capabilities. These OCR engines are available as a SAAS model provided by both vendors. Before you can start using these steps in DAS, you will need to have a subscription first.
We have added four step types to the Advanced section of the Job Designer tab of DAS, the steps are named:
- Image to Searchable PDF (Microsoft Cloud OCR)
- PDF to Searchable PDF (Microsoft Cloud OCR)
- Image to Searchable PDF (Google Cloud OCR)
- PDF to Searchable PDF (Google Cloud OCR)
The table below will explain the step properties of the Cloud OCR job steps.
| Step Property | Description |
|---|---|
| Output File Name | Target file template which can include %FILENAME (original filename without the extension) and %DIRNAME (directory name of the original file) |
| Create Directories if Required | Force creation of any output directories if they do not already exist. |
| Continue on Error | Continue processing files after an error occurs. |
| End Point (Microsoft Only) | The URL to the cognitive services endpoint where the OCR will be performed. |
| Subscription Key (Microsoft Only) | The subscription key to the above endpoint if you are using Microsoft. See Microsoft Computer Vision section for more information. |
| Google Key File Path (Google Only) | The path to the JSON subscription key file if you are using Google. See Google Cloud Vision section for more information. |
| Text Recognition Mode (Microsoft only) | Types of text to recognize - Handwritten - Printed Default is Printed |
| Handwritten Results Retries (Microsoft only) | The number of times to wait for the handwritten OCR results. |
| Handwritten Results Wait (Microsoft only) | The amount of time (in milliseconds) to wait between each retry. |
| OCR Language | Select the language to use for OCR processing. This will determine the dictionary that is used. Auto-Detect will automatically detect the language for each page. Printed text (see Text Recognition Mode) OCR supports 25 languages. Handwritten text OCR only supports English. Following are the different OCR language codes: - 0: Auto-Detect (default) - 1: Chinese (simplified) - 2: Chinese (traditional) - 3: Czech - 4: Danish - 5: Dutch - 6: English - 7: Finnish - 8: French - 9: German - 10: Greek - 11: Hungarian - 12: Italian - 13: Japanese - 14: Korean - 15: Norwegian - 16: Polish - 17: Portuguese - 18: Russian - 19: Spanish - 20: Swedish - 21: Turkish - 22: Arabic - 23: Romanian - 24: Serbian Cyrillic - 25: Serbian Latin - 26: Slovak |
| Autorotate (Microsoft Only) | Auto-rotate the image. This will ensure all text oriented normally. The default value is false (disabled). Note: When using a PDF source, auto-rotation will be disabled on any pages already containing text. |
| Deskew | Deskew (straighten) the image. The default value is No (disabled). |
| Despeckle | The method removes all disconnected elements within the image that have height or width in pixels less than the specified figure. The maximum value is 9 and the default value is 0. |
| Line Removal in OCR Processing | Removes lines during OCR for improved results |
| Save Pre-Despeckle | This will use the original image (i.e. before applying pre-processing) in the output PDF. The default value is true. |
| Output File | PDF and/or TXT (separated by commas) |
| PDF/A Options | Select the output PDF/A compliant version you would like the output PDF to be. - PDF/A1-b - PDF/A2-b - PDF/A3-b |
| Validate PDF/A | Whether or not to validate the PDF/A document after conversion |
| JBIG2 Compression | This option will compress bitonal images in generated PDFs using JBIG2 compression rather than the default Group 4 compression scheme. This will result in smaller PDF file sizes, at a cost of increased processing time. |
| MRC | This enables Mixed Raster Compression which can dramatically reduce the output size of PDFs comprising Color scans. |
| Remove Blank Pages | Set this to true to remove blank pages from Tiff or PDF documents. Value needs to be set for the Blank Page Threshold (see below). |
| Blank Page Threshold | Use this to set the minimum number of “On Pixels” that must be present in the image for a page not to be considered blank. A value of -1 will turn off blank page detection. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Maximum Cores | This specifies the number of parallel files you want to be processed at a given time. Note: You need the multi-core license for this. |
| Debug | Set this to true to execute the step in debug mode. |
| PDF to Searchable PDF Only Properties | |
| Non-Image PDFs | This allows control over the treatment of non-image only PDFs, for example , PDFs that have some text in them as well as images. The following list displays the controls you have over the Non-Image PDFs: - OCR: The document will be OCRed using the image extraction method defined by ExtractImageMethod.- Raise Error: The task will terminate with an error. - Skip: The document will not be processed. - Pass Through: The file will not be processed, but a copy of the document will be made and named as if the processing had occurred. |
| Remove Hidden Text | This applies only when a PDF is being used as the source for OCR. When set to true this will not include any searchable text that already exists from the source document. Such functionality might be useful if the source document was created by OCR of an image only PDF or other image file and the quality of the text from the previous OCR is poor. Note: There is no way to distinguish text added as a result of OCR from text added by other means and as a result this option should be used with care. |
| Convert to TIFF | This allows control over the method used to extract images from PDF files for OCR processing. The default value is ‘No’ for native processing. - No: (Native) - Yes: (Convert to TIFF) |
| DPI | The DPI to set to the images rasterized from each page of the source PDF file. These images are then OCRed to create the searchable PDF. The default value for this property is taken from each page in the source PDF file. |
| TIFF Compression | The compression to set to the images extracted or rasterized from each page of the source PDF file. These images are then OCRed to create the searchable PDF. The default value for this property is taken from each page in the source PDF file. Valid values are CCITT4 or LZW. |
| Retain Bookmark* | Retains any bookmarks from the source file in the output. |
| Retain Metadata* | Retains any metadata from the source file in the output when using. |
| Retain Viewer Preferences | Retains any PDF Viewer Preferences, Page Mode and Page Layout from source file in the output when using. |
Convert To TIFF must be set to ‘Yes’ for this to work.
Microsoft Computer Vision
Azure’s Computer Vision service(opens in a new tab) provides developers with access to advanced algorithms that process images and return information. The image processing algorithms can analyze content in several different ways, depending on the visual features you’re interested in. Computer Vision provides several services that recognize printed or handwritten text that appears in images.
To use this service, you will need:
- Microsoft Azure account(opens in a new tab).
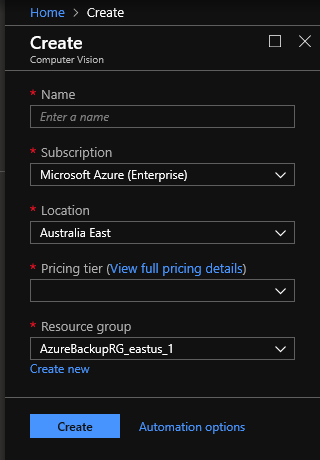
- Microsoft Computer Vision API endpoint. You can add(opens in a new tab) this to the azure account you created.
- Enter a suitable name for the endpoint.
- Choose your preferred azure subscription.
- Choose any location (Using a location that is closer to your files should give better performance).
- Select a suitable pricing tier depending on your work load.
- Select or create a new resource group.
Pricing
The table below gives you an estimate of the costs involved in using the Microsoft Computer Vision API to perform OCR operations.
You will consume one transaction per page.
To have a more accurate estimate, see the Pricing Calculator(opens in a new tab).
| Price | Transactions per month |
|---|---|
| Price | |
| Free | 0 - 5000 |
| $1 per 1,000 transactions | 0 – 5M |
| $0.80 per 1,000 transactions | 1M – 5M |
| $0.65 per 1,000 transactions | 5M+ |
Google Cloud Vision
Cloud Vision API(opens in a new tab) allows developers to easily integrate vision detection features within applications, including image labeling, face, and landmark detection, optical character recognition (OCR), and tagging of explicit content. We only use the OCR and Handwriting recognition features in DAS.
To use the Cloud Vision API in DAS, you will need a:
- Google account(opens in a new tab).
- Subscription key for the Google Cloud Platform(opens in a new tab). You can start your free trial(opens in a new tab), register for the trial and download your subscription key as a JSON file. Use the location of this JSON file as the value for the Subscription Key step property in DAS.
Pricing
The table below gives you an estimate of the costs involved in using the Google Cloud Vision API to perform OCR operations.
You will consume 1 unit for each page.
To have a more accurate estimate, you can use the Pricing Calculator(opens in a new tab).
| Price | Units per month |
|---|---|
| Free | 0-1000 |
| $1.50 per 1000 units | 1001 – 5M |
| $0.60 per 1000 units | 5M – 20M |