Optimize OCR with advanced preprocessing options
Properties file
The following are descriptions of those properties in the file Properties.xml that are most likely to be changed to improve engine performance. If you require further information regarding any properties in the file, contact our support team for assistance.
Binarize – This setting determines how the image will be converted into a bitonal one for OCR. The following are valid options:
-1: This utilizes a technique whereby those parts of the image that have certain characteristics indicative of characters are extracted from the underlying image. This approach can give the best results on pages such as magazine images, newsprint, etc and will handle light text on darker backgrounds. This approach can cause an increase in processing time with certain images.
0: This utilizes the binarization capabilities built into the OCR engine and whilst it can give good results in limited situations it is not generally recommended.
>0: A value greater than 0 (the recommended default is 200) will use a simple threshold technique comparing the intensity of the pixel to the threshold value to determine whether it should be set to black or white. This simple approach is the fastest option.
BoxSize – Setting a value above 0 will cause the removal of enclosing boxes from the image used for the OCR processing. The default value recommended is 100, for example, where the box edges are 100 pixels or greater.
BackgroundFactor - Sampling size for the background portion of the image. The higher the number, the larger the size of the image blocks used for averaging which will result in a reduction in size but also quality. The default value is 3.
DotMatrix - Set this to True to improve recognition of dot-matrix fonts. The default value is False. If set to true for non-dot-matrix fonts then the recognition can be poor.
ForegroundFactor - Sampling size for the foreground portion of the image. The higher the number, the larger the size of the image blocks used for averaging which will result in a reduction in size but also quality. The default value is 3.
Jbig2EncFlags – These are the flags that will be passed to the application used to generate JBIG2 versions of images used in PDF generation (assuming this compression is enabled). Options are as follows:
-b <basename>: output file root name when using symbol coding
-d –duplicate-line-removal: use TPGD in generic region coder
-p –pdf: produce PDF ready data
-s –symbol-mode: use text region, not generic coder
-t <threshold>: set classification threshold for symbol coder (def: 0.85)
-T <bw threshold>: set 1 bpp threshold (def: 188)
-r –refine: use refinement (requires -s: lossless)
-O <outfile>: dump thresholded image as PNG
-2: upsample 2x before thresholding
-4: upsample 4x before thresholding
-S: remove images from mixed input and save separately
-j –jpeg-output: write images from mixed input as JPEG
-v: be verbose
Language – The acceptable values are as follows:
- 0: English
- 1: German
- 2: French
- 3: Russian
- 4: Swedish
- 5: Spanish
- 6: Italian
- 7: Russian English
- 8: Ukrainian
- 9: Serbian
- 10: Croatian
- 11: Polish
- 12: Danish
- 13: Portuguese
- 14: Dutch
- 19: Czech
- 20: Roman
- 21: Hungarian
- 22: Bulgar
- 23: Slovenian
- 24: Latvian
- 25: Lithuanian
- 26: Estonian
- 27: Turkish
MaxDeskew – Maximum angle by which a page will be deskewed
Morph – Morphological options that will be applied to the binarized image before OCR. If left blank none is applied. Common options include those listed below but for more options, contact our support team:
- d2.2: 2x2 dilation applied to all black pixel areas, useful for faint prints.
- e2.2: 2x2 erosion applied to all black pixel areas, useful for heavy prints.
- c2.2: a closing process that performs a 2x2 dilation followed by a 2x2 erosion with the result that holes and gaps in the characters are filled.
NoPictures - By default, if an area of the document is identified as a graphic area, then no OCR processing is run on that area. However, certain documents may include areas or boxes that are identified as “graphics” or “picture” areas but actually do contain useful text. Setting NoPictures to True will cause it to ignore areas identified as pictures, whilst setting it to False will force OCR of areas identified as pictures.
OneColumn - The default value for this is true which improves the handling of single column text. Better handling of multi-column text such as a magazine or newsprint can be achieved by setting it to false.
PdfToImageIncludeText – When set to False, this will prevent the conversion of real text (for example, electronically generated as opposed to text that is part of a scanned image) from being rendered in the page images extracted from the PDF. This is because the text is already searchable and so generally does not require OCR. The value can be set to True however if the OCR is required on this real text.
Quality - JPEG quality setting (percentage value 1 - 100) for use in saving the background and foreground images. The default value is 75.
RemoveLines – The value used in Line removal. If blank, no line removal will occur. The normal value to use to enable line removal is 100.5 but if you are experiencing difficulties with this value or have any questions, contact our support team.
Advanced pre-processing
This option can be used to run each page OCR with 2 or more different settings and then chose the best set of results.
When the /optimiseocr is specified in the advanced flag field, the OCR and image processing engines will use the settings in the ImagePreProcessingDefaults section of the file Properties.xml modified by any properties set on the OCR and PreProcessing objects.
This will enable the use of these default settings first (without modification by the properties set on the OCR and PreProcessing objects) followed by the same defaults modified by the values in the ImagePreProcessing sections from ID=“1” to ID=“n” where n is the last consecutive set defined in Properties.xml.
Using heuristics and dictionary lookup, the quality of the OCR output is then compared in order to determine the optimum set to output. In this way, it is possible to define different sets of OCR and pre-processing conditions that are suited to different types of source documents. This approach can also improve the handling of documents that contain different types of pages, e.g. scanned at different qualities, containing different languages, containing standard and dot matrix prints, etc.
Sample Section of Properties.xml
<ImagePreProcessing ID="1"> <Binarize>-1</Binarize> <Morph>c2.2</Morph> </ImagePreProcessing> <ImagePreProcessingDefaults> <RemoveLines></RemoveLines> <Binarize>200</Binarize> <BlackPixelLimit>0.65</BlackPixelLimit> <BoxSize>0</BoxSize> <GrayscaleQuality>0</GrayscaleQuality> <Jbig2EncFlags>-s</Jbig2EncFlags> <Language>0</Language> <MaxDeskew>10</MaxDeskew> <MinDeskewConfidence>3.0</MinDeskewConfidence> <Morph></Morph> <Mrc> <ForegroundFactor>3</ForegroundFactor> <BackgroundFactor>3</BackgroundFactor> <Quality>75</Quality> </Mrc> <Ocr> <DotMatrix>False</DotMatrix> <OneColumn>False</OneColumn> <NoPictures>False</NoPictures> <Tables>False</Tables> </Ocr> <PdfImageExtraction> <PdfToImage>0</PdfToImage> <PdfToImageMinRes>200</PdfToImageMinRes> <PdfToImageMaxRes>300</PdfToImageMaxRes> <PdfToImageIncludeText>False</PdfToImageIncludeText> </PdfImageExtraction> <RemoveLines></RemoveLines> <SavePredespeckle>False</SavePredespeckle> <TextLayerExtraction> <MaxBoxes>0</MaxBoxes> <FilterWidth>130</FilterWidth> <FilterHeight>130</FilterHeight> <FilterRatio>1</FilterRatio> <FilterPercentage>0.6</FilterPercentage> <FilterWidthInverted>40</FilterWidthInverted> <FilterHeightInverted>40</FilterHeightInverted> <FilterRatioInverted>0.95</FilterRatioInverted> <FilterPercentageInverted>0.5</FilterPercentageInverted> </TextLayerExtraction> </ImagePreProcessingDefaults>Upgrade job definitions
As new versions of Document Automation Server (DAS) are released, the way that specific jobs are defined may change to incorporate new options or remove obsolete properties. This may require any job definitions files that were created on previous DAS versions to be upgraded to fit the new definitions that current DAS can recognize.
Automatic upgrades
In the latest version of DAS, jobs are upgraded automatically upon opening the UI. A window will show the progress of the upgrades, but it will be very quick if there are no jobs that need upgrading. The previous job definitions are archived in the “...Aquaforest\Autobahn DX\jobdef_copy” location, and are upgraded in place. The upgrade only occurs on jobs with an internal adxversion value that does not match the current version of DAS running. Jobs matching this version will be ignored.
Upgrading manually
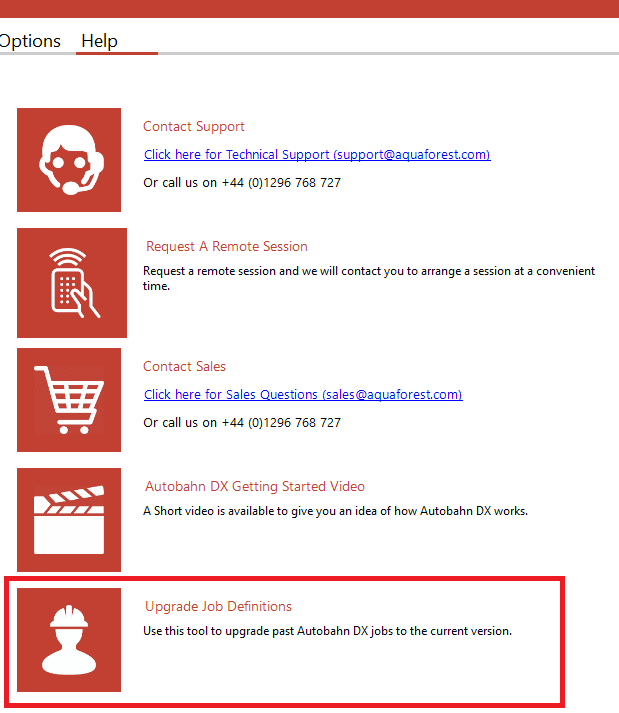
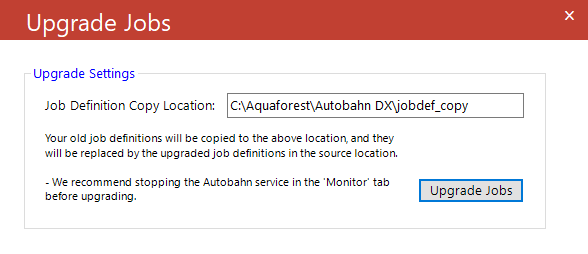
In the Help tab, there is a button displayed with the text Upgrade Job Definitions. Clicking this opens a tool to carry out the job definition upgrades. This tool will create a copy of the old job definitions, and then upgrade the files into up-to-date job definitions that match the current DAS version’s steps. We recommend checking that the settings of the job match your requirements after upgrading, as some fields may have been set to their default value. The picture below shows the location of the Job Upgrader, and the window of the application. Files in the “...Aquaforest\Autobahn DX\jobdef” folder will be the jobdef file to be upgraded. You can manually set the location where the original job definition files are copied to.
Extended OCR module
The optional Extended OCR module extends DAS with an additional OCR engine and has the following benefits over and above the standard Nutrient OCR engine:
- IRIS OCR Engine providing enhanced recognition
- New PDF Rasterizer component
- DOCX Output option
- Improved RTF Output
- CSV and SpreadsheetML output options
- Additional Western Language Support (see Extended OCR Languages for more details)
- Optional Asian Language Support: Support for multiple languages within a single document from the same alphabet. For example, French + German + Italian
Job manager steps
The Extended OCR Job steps can be found under the OCR group of the Job designer tab, the job step section gives you more details of the steps highlighted below.
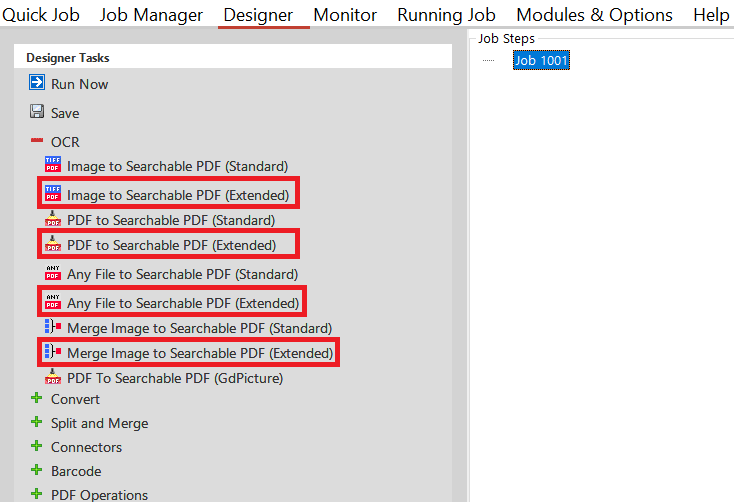
These job steps mirror the default equivalents (for example, Convert TIFF to PDF) but will have some different options (for example, different language and output formats) as shown below:
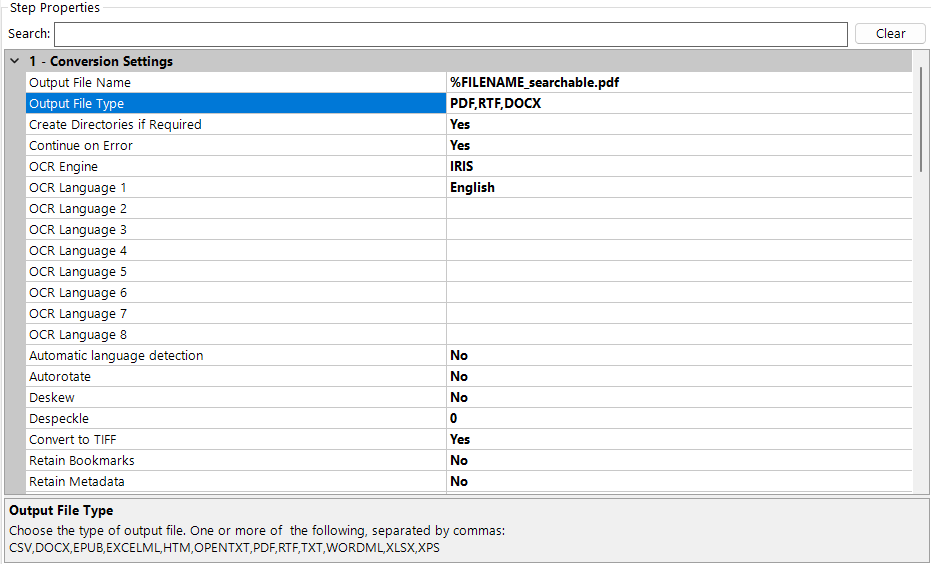
- Different output file formats are supported.
- Supports new IRIS OCR engine.
- You can select up to 8 different languages.
IHQC module
The IHQC Module is a module included with the Extended OCR. It enables the use of IRIS’ new Intelligent High-Quality Compression technology for powerful PDF compression without compromising visual quality, text resolution and legibility of documents.
IHQC properties
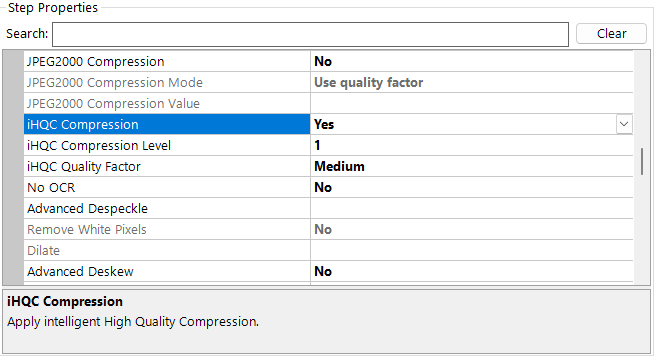
Command line interface
autobahndx.exe /operation=[operation name] /source=[tiff file or folder] /output=[output file] /target=[target folder] /mrc=[true or false] /ihqclevel=[1 to 4] /ihqcqf=[1 to 9] [/option=value]…
Example
Generate a compressed searchable PDF file from a folder of TIFF and JPEG files using intelligent high-quality compression.
autobahndx.exe /source=c:\in\folder /sourcetype=folder /target=c:\out /output=outfilef /outputtype=pdf operation=mergetifftopdf /mrc=true /ihqclevel=4 /ihqcqf=5 /ocrengine=1The following parameters are needed to use IHQC:
| Parameter | Notes |
|---|---|
/mrc | Apply intelligent High-Quality Compression. True or False |
/IHQCLevel | The compression level to be used. Level 1 is the basic compression level. Level 3 is the most advanced intelligent High-Quality Compression mode. Following are the different compression levels and their associated codes: - Compression Level 3: Code 4 - Compression Level 2b: Code 3 - Compression Level 2a: Code 2 - Compression Level 1: Code 1 |
/IHQCQF | The IHQC quality factor. Following are the different quality factors and their associated codes: - Maximal quality: 9 - Very high quality: 8 - High quality: 7 - Favor quality over size: 6 - Medium: 5 - Favor size over quality: 4 - Small size: 3 - Very Small Size: 2 - Minimal size: 1 |
Image requirements
Extended OCR has the following image limits:
• Max Height = 32,768 pixels
• Max Width = 32,768 pixels
• Max Size = 75,000,000 pixels
These limitations are also valid when working with image preprocessing: image resize, rotate, etc. The following table displays the image sizes at maximum resolutions:
| Paper standard | Size | Maximum resolution | Image at maximum resolution |
|---|---|---|---|
| A0 | 33.11 x 46.81 in 841 x 1189 mm | 219 | 7251 x 10251 |
| A1 | 23.39 x 33.11 in 594 x 841 mm | 311 | 7274 x 10297 |
| A2 | 16.54 x 23.39 in 420 x 594 mm | 440 | 7277 x 10291 |
| A3 | 11.69 x 16.54 in 297 x 420 mm | 622 | 7271 x 10287 |
| A4 | 8.27 x 11.69 in 210 x 297 mm | 880 | 7277 x 10287 |
| A5 | 5.83 x 8.27 in 148 x 210 mm | 1200 | 7270 x 10312 |
| A6 | 4.13 x 5.83 in 105 x 148 mm | 1200 | 7285 x 10284 |
| Letter | 8.5 x 11 in 216 x 279 mm | 895 | 7607 x 9845 |
| Legal | 8.5 x 14 in 216 x 356 mm | 793 | 6740 x 11102 |
| Junior legal | 8.0 x 5.0 in 203 x 127 mm | 1200 | 10952 x 6845 |
| Ledger | 17 x 11 in 432 x 279 mm | 633 | 10761 x 6963 |
| Tabloid | 11 x 17 in 279 x 432 mm | 633 | 6963 x 10761 |
There are various workarounds that you can try if you experience an image size issue.
- Reduce the DPI
- Try using the Standard OCR engine
- Consider exporting to PDF from the CAD application. The exported PDF files are more and more searchable, even for polygonised and SHX text (depending on CAD application). Try the following applications:
- How to create selectable and searchable text in a PDF from AutoCAD(opens in a new tab)
- Searchable Text [AutoCAD to PDF](opens in a new tab)