Design and manage document workflows
Document Automation Server (DAS) enables the definition and editing of a job definition using a tree-list type model, coupled with a Visual Studio-style property list. The different step types are listed on the left under the Designer Task group box. The step types have been grouped into subcategories, and each step type will have its own icon. Drag and drop can be used to enable reordering of steps.
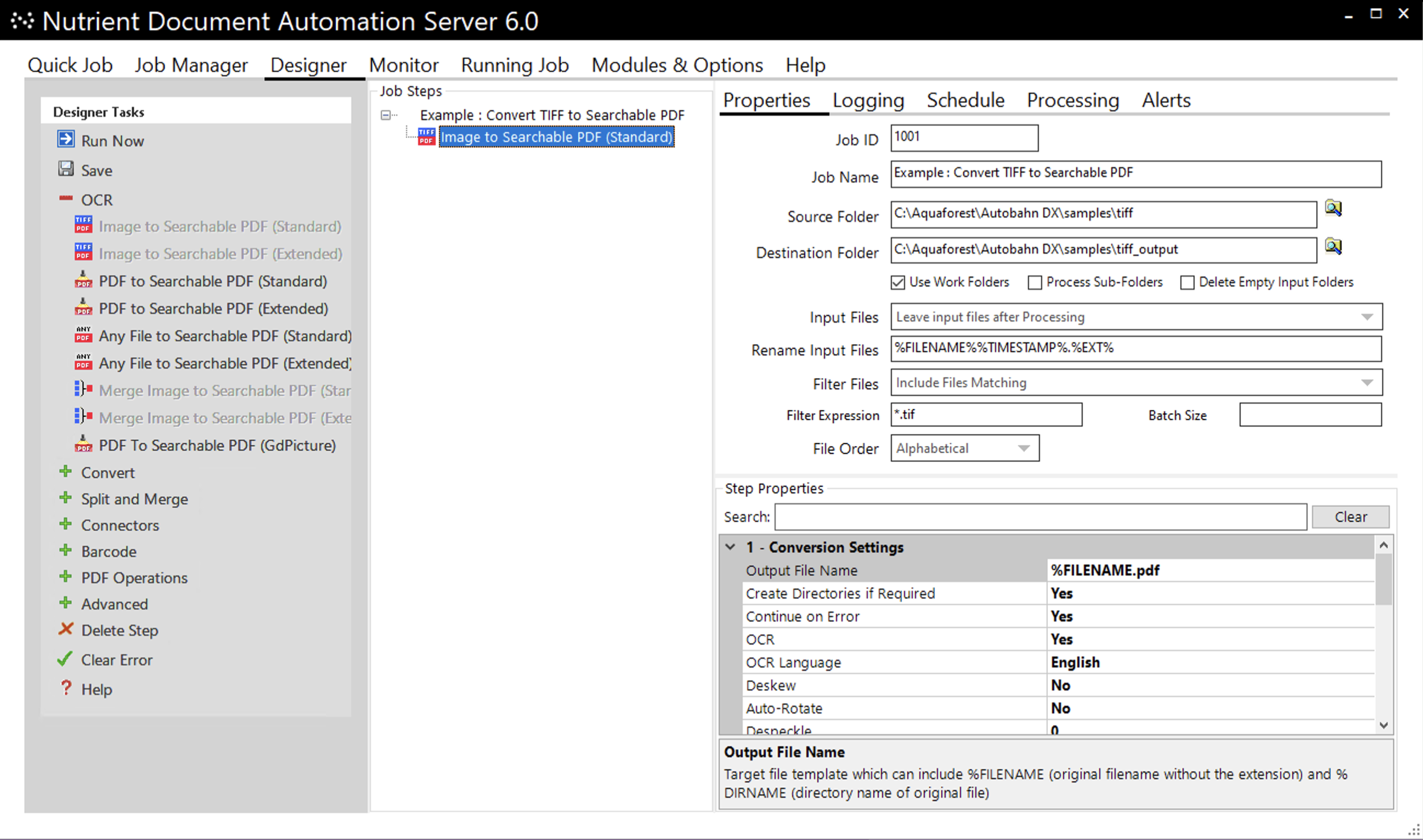
Menu items
| Menu items | Actions |
|---|---|
| Run Now | Executes the job that is being edited. The output is displayed in the Run tab. |
| Save | Validates the current job, and if valid, saves the current job definition to %JOBID%.xml in the %JOBDEFDIR% directory. |
| OCR | This expander contains the steps that perform OCR. Document Automation Server (DAS) will gray out the invalid steps. The step types in these groups are: - Image to Searchable PDF (Standard) - Image to Searchable PDF (Extended) - PDF to Searchable PDF (Standard) - PDF to Searchable PDF (Extended) - Any File to Searchable PDF (Standard) - Any File to Searchable PDF (Extended) - Merge Image to Searchable PDF (Standard) - Merge Image to Searchable PDF (Extended) - PDF to Searchable PDF (GdPicture) |
| Convert | - Convert PDF to TIFF - Convert Any File to PDF - Convert PDF to PDFA - Convert Any File to PDF (GdPicture) - Combine Any File to PDF - PDF to JPEG - PDF to PNG - PDF to TIFF - PDF to Text - Convert PDF to Office - Convert Any File to Office |
| Split and Merge | - Merge PDF - Split PDF - Merge TIFF - Split TIFF - Combine PDFs - Split PDF (GdPicture) |
| Connectors | - Read Mailbox - Send Documents - SharePoint Download - SharePoint Upload - Azure Storage Download - Azure Storage Upload |
| Barcode | - Barcode TIFF/PDF - Split PDF by Barcode |
| PDF Operations | - Set PDF Properties - Create XML Property File - Extract Text from PDF File - Optimize PDF - Stamp PDF Files - Modern Compress PDF - Validate PDFA - Linearize PDF - Create PDF Portfolio - Get Document Information |
| Advanced | - Custom Script Step - DAS Content Extraction (Kingfisher) Job - Distributed Polling - PDF Recognition to JSON - Image to Searchable PDF (Microsoft Cloud) - PDF to Searchable PDF (Microsoft Cloud) - Image to Searchable PDF (Google Cloud) - PDF to Searchable PDF (Google Cloud) - Detect Signatures - Smart Redaction - Key Value Pair Extraction - Pattern Redaction - Pattern Highlight - Pattern Enumeration - Zip Folders |
| Delete Step | Deletes the currently selected step node. |
| Clear Error | Click this before you can run a job that is in an error state. |
| Help | Takes you to the Help tab, which has links to many useful blogs, documents, and other resources. It also has contacts if you need help from our Support or Sales teams. |
Fields
| Menu item | Description |
|---|---|
| Job ID | A sequential job ID is allocated for the job by DAS. This cannot be changed. |
| Job Name | A descriptive title for the job. |
| Source Folder | The folder containing the documents to be processed. |
| Destination Folder | The folder where the processed files will be placed if Move input files to target folder after processing is selected. |
| Use Work Folders | By default, DAS processes job steps by using a separate folder for each step. Hence, files from the source folder are copied to a work folder, processed for each step to another work folder, and then finally moved to the target folder. This approach ensures integrity (e.g. correctly processing files that are added to the source folder after a job has started) but can slow down large jobs. |
| Process Sub-Folders | If checked, all subfolders will be recursively processed. |
| Delete Empty Input Folders | Checking this property will delete empty folders under the source folder after we move or delete your input files. |
| Input files | This option determines what happens to the input files once processing has been completed. The options are: - Leave input files after processing: Files are left in the source folder. - Move to archive after processing: Files are moved to the archive folder. - Copy to archive after processing: Files are copied to the archive folder. - Move input files to target folder after processing*: Input files are placed in the same folder as the output files. - Delete input files after successful processing: Input files are deleted. |
| Rename Input Files | This determines how input files will be renamed when moved to the target or archive folder. The default is:%FILENAME%%TIMESTAMP%.%EXT%You can also use %EMAILNAME% for files named in the email format. This will rename the file to its original name. |
| Filter Files | Refer to the filter file option table below for more details. Note: Work folders must be used to enable the use of filters. |
| Filter Expression | One or more search options used to determine the files in the source folder that should be processed. Multiple expressions, separated by spaces, may be used. Examples: - .pdf- .doc- .ppt- .xls |
| Batch Size | Limits the number of documents to be processed to the given size. To use this feature, you must use a Filter File Option with Document Count Limit. |
| File Order | The order that the files will be processed. There are UTC and local time variants of the date options, totaling nine options: - Alphabetically - Created Date (Ascending) - Created Date (Descending) - Modified Date (Ascending) Modified Date (Descending) Note: This setting does not work for Merge Image to PDF steps, as the merge and OCR must be done in two separate job steps. |
| Log File | Path of the job log file. This will include %DATESTAMP%, which is the date of the day the job started. A new log file will be created for each day. |
| CSV Log File | Path of the job log file. This will include %DATESTAMP%, which is the date of the day the job started. A new CSV file will be created for each day. The columns in the CSV file are:- Job Start – Time Job Started - Source Files – Full path to the source file - Target File – Full path to the target file - Job Stopped – Time Job Finished - Success – True or False; Files that could not be processed will have a value of false.- Page counts (not all steps generate page counts and dependent on configuration setting) |
| Retention Period | This is an integer value representing the number of days the log file will be kept before being deleted. Leaving it blank or setting it to a number less than 1 will keep the log files indefinitely. |
| Max Size | Set the maximum log file size. If a log file is created above this size, it will be split into smaller segments. |
| Stop Processing on Error | If checked, the job will stop if it returns an error, and will not run again until the error is cleared from the Monitor screen. |
| Skip Long File Names | Check this box to make DAS skip files with long filenames. If this box is not checked, DAS will throw an error if it encounters one of these files. |
| Skip Folders That Autobahn Can’t Access | Check this box to make DAS skip folders it has no permissions to access. If this box is not checked, DAS will throw an error if it encounters one of these folders. |
| Archive Folder | The folder where the processed files will be placed if Move to archive after processing is chosen. |
| Work Folder | The folder where files will be temporarily stored during conversion and processing. |
| Error Folder | Source documents that have errors during processing will be placed in the specified folder. |
| Temp Folder | Some job steps can require a significant amount of temporary storage, particularly those steps involving OCR. This folder defines the location of the temporary space. |
| Trigger File | You can find this setting under the Processing tab. If you provide a Trigger File value, DAS will not process a folder until the Trigger File is present, and the file will be deleted after each job run. |
Filter file option
| Filter file option | Description |
|---|---|
| Include Files Matching | Only files matching the filter expression are included. |
| Exclude | Files matching the filter expression are excluded. |
| Include with Document Count Limit | For example, .pdf; 3000 would limit the job to 3,000 PDF files. |
| Include Unprocessed PDFs Only | This would limit files selected to PDFs that have not been OCRed. A file is deemed to have been OCRed if: - It has a custom metadata tag AQUAFORESTOCROr it has one image per page and only has “invisible” text. This should be used in conjunction with a Non-Image PDF setting of Rasterize and OCR to ensure all PDF files are processed. |
| Include Unprocessed PDFs Only – with Document Count Limit | This is the same as above, but it’s limited to the number of files specified in the filter. |
Job scheduling
To use the Job Schedule, click the Schedule tab under the Designer tab.
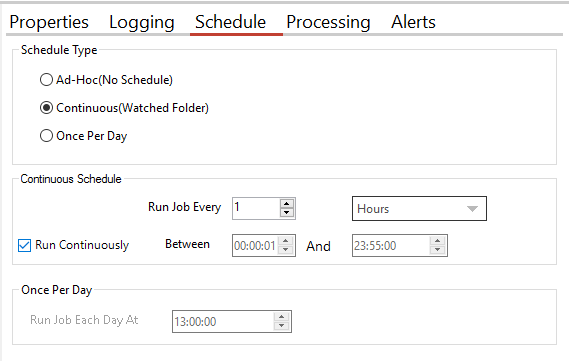
The product supports three types of scheduling, which are implemented via the DAS service and outlined below.
Ad hoc
This means that the job does not have any fixed schedule, but may be explicitly run via the management GUI or via one of the API methods.
Watched folder/continuous scheduling
This allows the job to be scheduled to run periodically between a start time and end time each day. The periods may be seconds, minutes, or hours. For example, a job may be specified to run every 30 seconds between 9:00 and 17:00.
If you select the Run Continuously checkbox, the job will run for 24 hours a day. This option is the default for all continuous jobs.
Daily scheduling
This allows the job to be scheduled to run at a specified time each day.
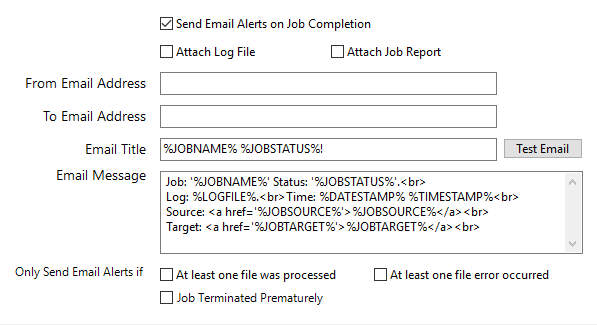
Alerts
This allows you to send emails to your mailbox when the job is successful or fails. To get to the Alerts tab, you will need to click the Alerts tab under the Designer tab.
Note: You will need to enter your SMTP setting in the Modules and Options tab before email alerts will work properly.
| Menu item | Action |
|---|---|
| Send Email Alerts on Job Completion | If checked, DAS will send an email if the job ends naturally or prematurely. This alert can be further tailored using the properties in the section below. |
| Only Send Email Alerts if: | |
| At least one file was processed | If you check this option, DAS will not send any email until it processes at least one file in the job. This is meant to reduce the number of irrelevant messages you get. |
| Job Terminated Prematurely | Check this if you only want to receive emails when an error occurs during the processing of a job. Note: Individual file errors will not put the job in error; a job error occurs in a more fatal circumstance. |
| At least one file error occurred | Check this option if you only want to receive emails when individual file errors occur. |
| Attach Log File | Check this option if you want DAS to attach the Log file of the job to the email alert. |
| Attach Job Report | Check this option if you want DAS to attach a report/summary of the job to the email alert. |
| From Email Address | The “from” email address that will be used for the message. |
| To Email Address | The email address that the message will be sent to. |
| Email Title | The title of the email. |
| Email Message | The body of the email, this can be HTML content. |
Alert variables
When sending emails, there are several variables that can be used to customize the alerts you send out. These variables are enclosed by two percent signs: %%. DAS will replace any occurrences of the variables with an appropriate value at run time. The table below shows the possible variables that can be used.
| Variable | Meaning |
|---|---|
%JOBID% | The job ID; this works with both the email title and email message. |
%JOBNAME% | The job name; this works with both the email title and email message. |
%JOBSTATUS% | The job status; this works with both the email title and email message. |
%LOGFILE% | The location of the log file; this works with both the email title and email message. |
%JOBSOURCE% | The source directory of the job; this works with the email message only. |
%JOBTARGET% | The destination directory of the job; this works with the email message only. |
%DATESTAMP% | The date that the alert was generated; this works with both the email title and email message. |
%TIMESTAMP% | The time the alert was generated; this works with both the email title and email message. |
Workflow processing vs. in-place processing
DAS is designed as a workflow product where there is an input folder and an output folder. At the end of the process, there are options to copy, delete, or move the input files that have been successfully processed.
With “in-place” processing, the input documents are turned into searchable PDFs and returned to the same location. It’s possible to replace the existing file if the output file format produces the same file name. The input files can be copied to an archive location if they need to be kept (this is recommended during the development process and during testing — if this isn’t set, the original file cannot be recovered).
DAS can be used for in-place processing, but we have an OCR product named Document Searchability that is designed specifically for in-place conversions to searchable PDFs, and it may handle this use case more effectively. It records all the files it processes, so it’s more efficient when there are a lot of files, as they don’t need to be opened to be identified as previously processed.
Example in-place job setup
The job shown below will convert PDFs under the C:\ADX Demo\Documents tree to searchable PDFs, processing up to five files each time the job is run.
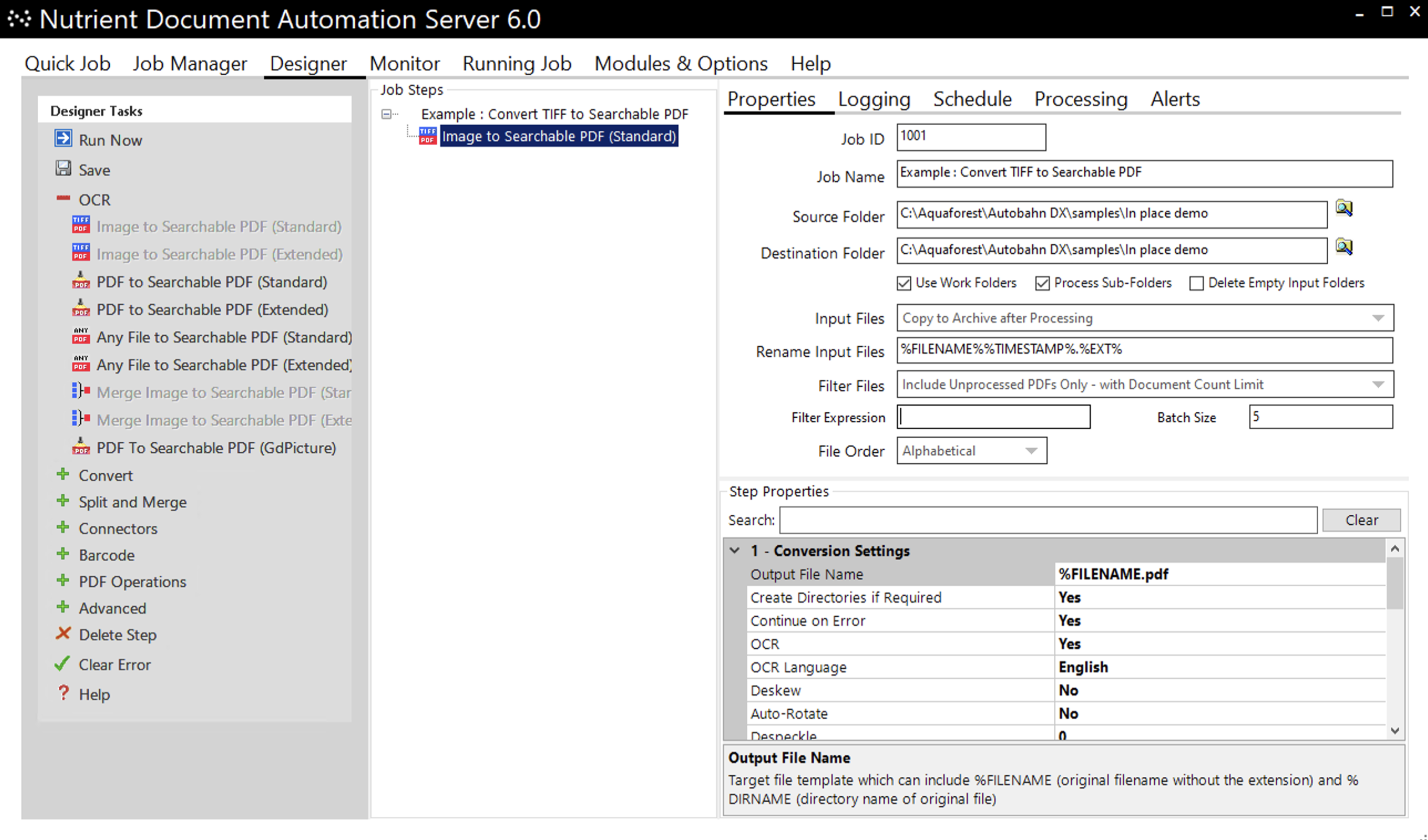
The Source Folder and the Target Folder must be the same.
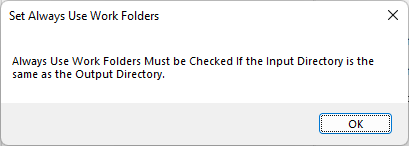
The Use Work Folders checkbox must be selected when processing in place. A message will be displayed when the folders are set to the same location in the UI and the checkbox will be automatically set.
Select the Process Sub-Folders checkbox.
For Audit Purposes, the Input Files option should be set to Copy to archive after Processing.
To avoid reprocessing files, select the Include Unprocessed PDFs Only – with Document Count Limit option in the Filter Files combo box.
Because the Filter Files option selected includes the document count limit, the Batch Size of the job can be set to five files per run (You can increase this to a suitable batch size).
The Output file Name is set in the conversion settings for the step and should be configured to **%FILENAME.pdf** so that it will replace the input file.
Step types
This section explains each of the step types.
DAS Server edition is licensed to use Standard and GdPicture steps. The Extended edition adds the Extended OCR steps.
| Step group | Step name |
|---|---|
| OCR | Image to Searchable PDF (Standard) |
| OCR | Image to Searchable PDF (Extended) |
| OCR | PDF to Searchable PDF (Standard) |
| OCR | PDF to Searchable PDF (Extended) |
| OCR | Any File to Searchable PDF (Standard) |
| OCR | Any File to Searchable PDF (Extended) |
| OCR | Merge Image to Searchable PDF (Standard) |
| OCR | Merge Image to Searchable PDF (Extended) |
| OCR | PDF To Searchable PDF (GdPicture) |
| Convert | Convert PDF to TIFF |
| Convert | Convert Any File to PDF |
| Convert | Convert PDF to PDFA |
| Convert | Convert Any File To PDF (GdPicture) |
| Convert | Combine Any File To PDF |
| Convert | PDF To JPEG |
| Convert | PDF To PNG |
| Convert | PDF To TIFF |
| Convert | PDF To Text |
| Convert | Convert PDF To Office |
| Convert | Convert Any File To Office |
| Split and Merge | Merge PDF |
| Split and Merge | Split PDF |
| Split and Merge | Merge TIFF, JPEG, BMP, PNG, GIF |
| Split and Merge | Split TIFF |
| Split and Merge | Combine PDFs |
| Split and Merge | Split PDF (GdPicture) |
| Connectors | Read Mailbox |
| Connectors | Send Documents |
| Connectors | SharePoint Download |
| Connectors | SharePoint Upload |
| Connectors | Azure Storage Download |
| Connectors | Azure Storage Upload |
| Barcode | Barcode TIFF/PDF |
| Barcode | Split PDF by Barcode |
| PDF Operations | Set PDF Properties |
| PDF Operations | Create XML Property File |
| PDF Operations | Extract Text from PDF File |
| PDF Operations | Optimize PDF |
| PDF Operations | Stamp PDF Files |
| PDF Operations | Modern Compress PDF |
| PDF Operations | Validate PDFA |
| PDF Operations | Linearize PDF |
| PDF Operations | Create Pdf Portfolio |
| PDF Operations | Get Document Information |
| Advanced | Custom Script Step |
| Advanced | DAS Content Extraction Job |
| Advanced | Distributed Polling |
| Advanced | PDF Recognition to JSON |
| Advanced | Image to Searchable PDF (Microsoft Cloud OCR) |
| Advanced | PDF to Searchable PDF (Microsoft Cloud OCR) |
| Advanced | Image to Searchable PDF (Google Cloud OCR) |
| Advanced | PDF to Searchable PDF (Google Cloud OCR) |
| Advanced | Detect Signatures |
| Advanced | Smart Redaction |
| Advanced | Key Value Pair Extraction |
| Advanced | Pattern Redaction |
| Advanced | Pattern Highlighting |
| Advanced | Pattern Enumeration |
| Advanced | Zip Folders |
Image to searchable PDF
This step can be found under the OCR Expander. It creates a searchable PDF file from input image types e.g. .png, .tiff, .jpg, .gif, .bmp.
Depending upon the Step Type Properties chosen, a separate text, HTML and Office files may be produced from the OCR process.
This step is not available for the GdPicture engine; however, it can be replicated by using a combination of the Convert Any File To PDF (GdPicture) and PDF To Searchable PDF (GdPicture) steps
Standard engine
| Parameter | Notes |
|---|---|
| Output File Name | Target file template which can include %FILENAME (original filename without the extension) and %DIRNAME (directory name of the original file) |
| Create Directories if Required | Force creation of any output directories if they don’t already exist. |
| Continue on Error | Continue processing TIFF files after an error occurs. |
| OCR | - Choose “No” to generate an image-only PDF. - Choose “Yes” to generate searchable PDF and/or text files. |
| OCR Language | Select the language the original file is written in. This will determine the dictionary that is used. |
| Deskew | Straighten the image. |
| Auto-Rotate | Automatically rotate pages so that text flows left to right. |
| Despeckle | Remove specks below the specified pixel size from the image. |
| OCR to Text File | Choose “Yes” to Generate text Output |
| Output File | - Plain Text (txt). - Plain Text (txt) No PDF - MS Word (rtf) - HTML |
| PDF/A Options | Select the output PDF/A compliant version you would like the output PDF to be. - PDF/A1-b - PDF/A2-b - PDF/A3-b |
| Validate PDF/A | Whether or not to validate the PDF/A document after conversion |
| JBIG2 Compression | This option will compress bitonal images in generated PDFs using JBIG2 compression rather than the default Group 4 compression scheme. This will result in smaller PDF file sizes, at a cost of increased processing time. |
| Box/Graphics Options | By default, if an area of the document is identified as a graphic area, then no OCR processing is run on that area. However, certain documents may include areas or boxes that are identified as “graphics” or “picture” areas but do contain useful text. To ensure that the OCR engine can be forced to process such areas there are two options: - Treat all Graphics Areas as Text: This option will ensure the entire document is processed as text. - Remove Box Lines in OCR Processing: This option is ideal for forms where sometimes boxes around text can cause an area to be identified as graphics. This option removes boxes from the temporary copy of the imaged used by the OCR engine. It does not remove boxes from the final image. Technically, this option removes connected elements with a minimum area (by default 100 pixels). |
| Line Removal in OCR Processing | This removes lines and boxes during OCR processing to improve recognition – particularly in cases where characters “touch” lines. |
| MRC | This enables Mixed Raster Compression which can dramatically reduce the output size of PDFs comprising Color scans. |
| Save Pre-Despeckle | This will use the original image (i.e., before applying pre-processing) in the output PDF. The default value is true. |
| StampName | This has been deprecated, use the Stamp PDF Files step. |
| StampValue | This has been deprecated, use the Stamp PDF Files step. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Maximum Cores | This specifies the number of parallel files you want to be processed at a given time. Note: This needs a multi-core license and the number of cores used will depend on the availability of cores. |
| Debug | Set this to true to execute the step in debug mode. |
Extended engine
| Parameter | Notes |
|---|---|
| Output File Name | The output filename excluding the extension (which will be added according to the output file type). |
| Output File Type | One or more of the following, separated by commas if more than one is required. - CSV* - DOCX - EPUB - EXCELML * - HTM - OPENTXT - RTF - TXT - WORDML - XLSX * - XPS *These output formats are suitable for table-oriented pages that can be mapped onto a spreadsheet format. |
| Create Folders If Required | Create an output folder if it does not exist. Default true. |
| OCR Engine | The OCR engine to use. This must be set to use the IRIS engine. |
| OCR Language 1-8 | You can set up to eight different languages for OCR recognition on one page, only if they are in the same character set. English is available as a language |
| Automatic language detection | Property that enables or disables the Auto Language Detection feature. The aim of this feature is to detect the most probable language of a single-language page. If at least one language has been detected, recognition will be performed in the first language candidate that has been detected, and not in the language(s) set through Language or Languages. If it fails to detect a language, recognition will be performed using the language(s) set through Language or Languages. |
| Auto rotate | Detect page orientation and correct if required |
| Deskew | Rotates the image to correct its skew angle. |
| Advanced Deskew | Set this to true to define advanced deskew properties. |
| Force Deskew | Under certain circumstances, rotating the image to correct its skew angle may decrease the OCR accuracy. The extended engine is able to analyze the image and detect from an OCR accuracy point of view whether it’s better to rotate the image or not. Because the skew angle may be visible in the output document (e.g. if KeepDeskew is set to true), you can choose to force the deskew to rotate the image, even if it affects the accuracy.If turned off, the image is analyzed before rotation and the engine may choose not to rotate the image depending on the analysis result. If turned on, the image is rotated to correct skew angle. |
| Adjustment Mode | Set the behavior regarding dimension adjustment for deskew operation. |
| Despeckle | Removes all the groups of connected pixels with a few pixels below the parameter. Suggested range: 1-20. |
| Advanced Despeckle | Set the advanced despeckle settings, advanced despeckle provides advanced image noise reduction features by the image despeckle filter. |
| Remove White Pixels | By default, Advanced Despeckle removes black pixels. If this setting is set to true, white pixels will be removed instead of black pixels. |
| Dilate | Despeckle removes all the groups of connected pixels with a few pixels below the SpeckleSize parameter. Those connected pixels are not removed if the distance to a larger connected component is below this parameter. As a result, only the isolated pixels get deleted. The maximum value for this property is 20 pixels. The default value is 0. |
| Layout | The layout for the docx or rtf document: - Standard - Flow |
| PDFVersion | This determines the PDF version of the generated PDF: - 1.4 - 1.5 - 1.6 - 1.7 - 1.7 Extension Level 3 - 1.7 Extension Level 5 - 1.7 Extension Level 8 - PDF/A-1a - PDF/A-1b - PDF/A-2a - PDF/A-2b - PDF/A-3a - PDF/A-3b |
| Remove Blank Page | Set this to true to remove blank pages from Tiff or PDF documents. Value needs to be set for sensitivity (see below). |
| Sensitivity | The sensitivity, from 1 to 100. With high sensitivity, fewer blank pages are detected. |
| Work Depth | This parameter (0 – 255) defines how deeply the OCR engine will analyze a page with 255 being the deepest. For poorer quality documents, higher values can give better recognition results. |
| JPEG Quality | This parameter (0 – 255) determines the compression/quality of color JPEG images in generated PDFs. 0 gives the smallest file size whilst 255 gives the best quality. The default value is 128. |
| JPEG2000 Compression | Enable/Disable JPEG2000 Compression. |
| JPEG2000 Compression Mode | The JPEG2000 Compression Mode to use. |
| JPEG2000 Compression Value | The Value to set for the selected Compression Mode. |
| IHQC Compression | Apply Intelligent High-Quality Compression |
| IHQC Compression Level | Level 1 is the basic compression level while level 3 is the most advanced Intelligent High-Quality Compression Mode. |
| IHQC Quality Factor | The quality Factor for IHQC |
| No OCR | Whether are not to perform OCR on the document (Yes to not perform OCR, No to perform OCR). |
| Binarization | Whether or not to perform binarization on the document. |
| Brightness | The brightness (higher values will make the result darker). |
| Contrast | The contrast (lower values will make the result darker). |
| Smoothing Level | Smoothing may be useful to binarize text with a colored background to avoid noisy pixels (0 disables smoothing, higher values smooth more). |
| Undithering | Whether or not to use automatic undithering while processing a page. Note: Automatic undithering will be applied only if smoothing is also activated (Smoothing Level). Dithering is a scanning technique which consists in representing a color or grayscale image using only a limited color palette. This allows reducing file size while maintaining the general aspect of the image. This technique is known to create images more difficult to handle for OCR technology; therefore specific image preprocessing is needed to detect and revert it. |
| Threshold | Sets the threshold for fixed threshold binarization (0 for automatic threshold computation). |
| Remove Lines | Whether or not to remove lines from an image (The image must be black and white). |
| Horizontal Clean X | The parameter for cleaning noisy pixels attached to the horizontal lines. |
| Horizontal Clean Y | The parameter for cleaning noisy pixels attached to the horizontal lines. |
| Vertical Clean X | The parameter for cleaning noisy pixels attached to the vertical lines. |
| Vertical Clean Y | The parameter for cleaning noisy pixels attached to the vertical lines. |
| Horizontal Dilate | The dilate parameter that helps the detection of horizontal lines. |
| Vertical Dilate | The dilate parameter that helps the detection of vertical lines. |
| Horizontal Max Gap | The maximum horizontal line gap to close. It is useful to remove broken lines. |
| Vertical Max Gap | The maximum vertical line gap to close. It is useful to remove broken lines. |
| Horizontal Max Thickness | The maximum thickness of the horizontal lines to remove. It is useful to keep vertical lines larger than this parameter. Can be also useful to keep vertical letter strokes. |
| Vertical Max Thickness | The maximum thickness of the vertical lines to remove. It is useful to keep horizontal lines larger than this parameter. Can be also useful to keep horizontal letter strokes. |
| Horizontal Min Length | The minimum length of the horizontal lines to remove. |
| Vertical Min Length | The minimum length of the vertical lines to remove. |
| Remove Dark Borders | Removes the dark surrounding from bitonal, grayscale or color images. The dark surrounding of the image is whitened (Note: The dark border should be touching the edge of the page for this to work). |
| Punch Hole Removal | Attempts to remove punch holes from pages. Note: The punch hole algorithm can be used on images with the following minimum dimensions width: 300px, height: 100px (computed for 300 DPI). The minimum height and width can vary with the image resolution. |
| Interpolation | Interpolates the source image to the given resolution. This value (the target resolution) must be greater than the source image’s resolution. |
| Interpolation Mode | Sets the interpolation mode. |
| Keep Original Image | Set this to true if you want to use the pre-processed image for OCR but keep the original image in the output document. The default value is true. |
| Keep Deskewed Image | Set this to true if you want to use the deskewed image in the output document. Note: This property only applies when Keep Original Image is set to No |
| Keep Despeckled Image | Set this to true if you want to use the despeckled image in the output document. This requires the source image to be black and white. Note: This property only applies when Keep Original Image is set to No |
| Keep Dark Border Removal | Set this to true if you want to use the image after dark borders have been removed, in the output document. Note: This property only applies when Keep Original Image is set to No |
| Keep Punch Hole Removal | Set this to true if you want to use the image after punch holes have been removed, in the output document. Note: This property only applies when Keep Original Image is set to No |
PDF to searchable PDF
Creates a searchable PDF file from the set of images from an image-only PDF file.
Depending upon the Step Type Properties chosen, a separate text, HTML and Office files may be produced from the OCR process.
Standard engine
| Parameter | Notes |
|---|---|
| Output File Name | Target file template which can include %FILENAME (original filename without the extension) and %DIRNAME (directory name of the original file). |
| Create Directories if Required | Force creation of any output directories if they don’t already exist. |
| Continue on Error | Continue processing TIFF files after an error occurs. |
| OCR | - Choose “No” to generate an image-only PDF. - Choose “Yes” to generate searchable PDF and/or text files. |
| OCR Language | Select the language the original file is written in. This will determine the dictionary that is used. |
| Deskew | Straighten the image. |
| Auto-Rotate | Automatically rotate pages so that text flows left to right. |
| Despeckle | Remove specks below the specified pixel size from the image. |
| OCR to Text File | Choose “Yes” to Generate text Output. |
| Output File | - Plain Text (txt) - Plain Text (txt) No PDF - MS Word (rtf) - HTML |
| Non-Image PDFs | This allows control over the treatment of non-image PDFs, i.e. PDFs that have some text in them as well as images. The options are: - OCR: The document will be OCRed using the image method defined by “Image Method”. - Raise Error: The task will terminate with an error. If “On Error Continue” is set, this then behaves as Skip. This is the default. - Skip: The document will not be processed. - Pass Through: The file will not be processed, but a copy of the document will be made and named as if the processing had occurred. |
| Remove Hidden Text | This applies only when a PDF is being used as the source for OCR. When set to true this will not include any searchable text layers that already exist from the source document. Such functionality might be useful if the source document was created by OCR of an image only PDF or other image file and the quality of the text from the previous OCR is poor. Note: There is no way to distinguish text added as a result of OCR from text added by other means and as a result, this option should be used with care. |
| Convert to TIFF | Choose the method for PDF image extraction: - No – (Native) - Yes – (Convert to TIFF) |
| DPI | When OCRing a PDF, the PDF is rasterized to produce a TIFF file which is then OCRed. By default, the TIFF image resolution is determined from the images embedded in the source PDF but this flag can be used to override default processing and specify the DPI of the TIFF that will be generated. |
| TIFF Compression | Sets the Compression for the TIFF file used if the “Convert To TIFF” Option above is used. - Auto (Selects Group 4 if the page is Black AND White else it uses LZW Compression) - Group 4 (Black and White) - LZW (Colored) |
| Retain Metadata | Copy metadata from the source PDF to the Searchable result PDF. |
| Retain Bookmarks | Copy bookmarks from the source PDF to the Searchable result PDF. |
| Retain Viewer Preferences | Retains any PDF Viewer Preferences, Page Mode and Page Layout from the source file in the output when using Convert To TIFF=’Yes’. |
| PDF/A Options | Select the output PDF/A compliant version you would like the output PDF to be: - PDF/A1-b - PDF/A2-b - PDF/A3-b |
| Validate PDF/A | Whether or not to validate the PDF/A document after conversion. |
| Box/Graphics Processing | By default, if an area of the document is identified as a graphic area then no OCR processing is run on that area. However, certain documents may include areas or boxes that are identified as “graphics” or “picture” areas but that actually do contain useful text. To ensure that the OCR engine can be forced to process such areas there are two options: - Treat all Graphics Areas as Text: This option will ensure the entire document is processed as text. - Remove Box Lines in OCR Processing: This option is ideal for forms where sometimes boxes around text can cause an area to be identified as graphics. This option removes boxes from the temporary copy of the imaged used by the OCR engine. It does not remove boxes from the final image. Technically, this option removes connected elements with a minimum area (by default 100 pixels). |
| Line Removal in OCR Processing | This removes lines and boxes during OCR processing to improve recognition – particularly in cases where characters “touch” lines. |
| JBIG2 Compression | This option will compress bitonal images in generated PDFs using JBIG2 compression rather than the default Group 4 compression scheme. This will result in smaller PDF file sizes, at a cost of increased processing time. |
| MRC Compression | Applies Mixed Raster Compression which can drastically reduce the size of PDF documents. |
| Save Pre-Despeckle | This will use the original image (i.e. before applying pre-processing) in the output PDF. The default value is true. |
| StampName | This has been deprecated, use the Stamp PDF Files step. |
| StampValue | This has been deprecated, use the Stamp PDF Files step. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Maximum Cores | This specifies the number of parallel files you want to be processed at a given time. Note: This needs a multi-core license and the number of cores used will depend on the availability of cores. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. The file will be copied to the password sub directory in the Error Folder: - Take no action. - Move to Error Folder - Copy to Error Folder |
| Debug | Set this to true to execute the step in debug mode. |
Extended engine
| Parameter | Notes |
|---|---|
| Output File Name | The output filename excluding the extension (which will be added according to the output file type). |
| Output File Type | One or more of the following, separated by commas if more than one is required: - CSV* - DOCX - EPUB - EXCELML* - HTM - OPENTXT - RTF - TXT - WORDML - XLSX* - XPS *These output formats are suitable for table-oriented pages that can be mapped onto a spreadsheet format. |
| OCR Engine | The OCR engine to use. This must be set to use the IRIS engine. |
| OCR Language 1-8 | You can set up to eight different languages for OCR recognition in one page as long as they are in the same character set. |
| Automatic Language Detection | Property that enables or disables the Auto Language Detection feature. The aim of this feature is to detect the most probable language of a single-language page. If at least one language has been detected, recognition will be performed in the first language candidate that has been detected, and not in the language(s) set through Language or Languages. If it fails to detect a language, recognition will be performed using the language(s) set through Language or Languages. |
| Auto Rotate | Detect page orientation and correct if required |
| Deskew | Rotates the image to correct its skew angle. |
| Advanced Deskew | Set this to true to define advanced deskew properties. |
| Force Deskew | Under certain circumstances, rotating the image to correct its skew angle may decrease the OCR accuracy. The extended engine is able to analyze the image and detect from an OCR accuracy point of view whether it’s better to rotate the image or not. Because the skew angle may be visible in the output document (e.g. if KeepDeskew is set to true), you can choose to force the deskew to rotate the image, even if it affects the accuracy.If turned off, the image is analyzed before rotation and the engine may choose not to rotate the image depending on the analysis result. If turned on, the image is rotated to correct skew angle. |
| Adjustment Mode | Set the behavior regarding dimension adjustment for deskew operation. |
| Despeckle | Removes all the groups of connected pixels with a number of pixels below the parameter. Suggested range: 1-20. |
| Advanced Despeckle | Set the advanced despeckle settings, advanced despeckle provides advanced image noise reduction features by the image despeckle filter. |
| Remove White Pixels | By default, Advanced Despeckle removes black pixels. If this setting is set to true, white pixels will be removed instead of black pixels. |
| Dilate | Despeckle removes all the groups of connected pixels with a few pixels below the SpeckleSize parameter. Those connected pixels are not removed if the distance to a larger connected component is below this parameter. As a result, only the isolated pixels get deleted. The maximum value for this property is 20 pixels. The default value is 0. |
| Retain Bookmark | This option allows you to retain the bookmarks in the new PDF if the old PDF was Converted to TIFF before it was OCRed. Note: This will only work if Extract Images Method = Convert to TIFF. |
| Retain Metadata | This option allows you to retain the metadata in the new PDF if the old PDF was Converted to TIFF before it was OCRed. Note: This will only work if Convert to TIFF = Yes. |
| Layout | The layout for the docx or rtf document: - Standard - Flow |
| PDFVersion | This determines the PDF version of the generated PDF: - 1.4 - 1.5 - 1.6 - 1.7 - 1.7 Extension Level 3 - 1.7 Extension Level 5 - 1.7 Extension Level 8 - PDF/A-1a - PDF/A-1b - PDF/A-2a - PDF/A-2b - PDF/A-3a - PDF/A-3b Note: This will only work if Extract Images Method = Convert to TIFF. |
| Extract Images Method | Whether to convert the images in a PDF document to TIFF or not: - Convert to TIFF: The pages in the PDF document are rasterized and saved as TIFF images - Native: This method places the OCRed text directly into a copy of the original PDF rather than creating an entirely new PDF. |
| Remove Blank Page | Set this to true to remove blank pages from Tiff or PDF documents. Value needs to be set for sensitivity (see below). |
| Sensitivity | The sensitivity, from 1 to 100. With high sensitivity, fewer blank pages are detected. |
| Work Depth | This parameter (0 – 255) defines how deeply the OCR engine will analyze a page with 255 being the deepest. For poorer quality documents, higher values can give better recognition results. |
| JPEG Quality | This parameter (0 – 255) determines the compression/quality of Color JPEG images in generated PDFs. 0 gives the smallest file size whilst 255 gives the best quality. The default value is 128. |
| JPEG2000 Compression | Enable/Disable JPEG2000 Compression. |
| JPEG2000 Compression Mode | The JPEG2000 Compression Mode to use. |
| JPEG2000 Compression Value | The Value to set for the selected Compression Mode. |
| IHQC Compression | Apply Intelligent High-Quality Compression |
| IHQC Compression Level | Level 1 is the basic compression level while level 3 is the most advanced Intelligent High-Quality Compression Mode. |
| IHQC Quality Factor | The quality Factor for IHQC |
| Binarization | Whether or not to perform binarization on the document. |
| Brightness | The brightness (higher values will make the result darker). |
| Contrast | The contrast (lower values will make the result darker). |
| Smoothing Level | Smoothing may be useful to binarize text with a colored background to avoid noisy pixels (0 disables smoothing, higher values smooth more). |
| Undithering | Whether or not to use automatic undithering while processing a page. NOTE: Automatic undithering will be applied only if smoothing is also activated (Smoothing Level). Dithering is a scanning technique which consists in representing a color or grayscale image using only a limited color palette. This allows reducing file size while maintaining the general aspect of the image. This technique is known to create images more difficult to handle for OCR technology; therefore specific image preprocessing is needed to detect and revert it. |
| Threshold | Sets the threshold for fixed threshold binarization (0 for automatic threshold computation). |
| Remove Lines | Whether or not to remove lines from an image (The image must be black and white). |
| Horizontal Clean X | The parameter for cleaning noisy pixels attached to the horizontal lines. |
| Horizontal Clean Y | The parameter for cleaning noisy pixels attached to the horizontal lines. |
| Vertical Clean X | The parameter for cleaning noisy pixels attached to the vertical lines. |
| Vertical Clean Y | The parameter for cleaning noisy pixels attached to the vertical lines. |
| Horizontal Dilate | The dilate parameter that helps the detection of horizontal lines. |
| Vertical Dilate | The dilate parameter that helps the detection of vertical lines. |
| Horizontal Max Gap | The maximum horizontal line gap to close. It is useful to remove broken lines. |
| Vertical Max Gap | The maximum vertical line gap to close. It is useful to remove broken lines. |
| Horizontal Max Thickness | The maximum thickness of the horizontal lines to remove. It is useful to keep vertical lines larger than this parameter. Can be also useful to keep vertical letter strokes. |
| Vertical Max Thickness | The maximum thickness of the vertical lines to remove. It is useful to keep horizontal lines larger than this parameter. Can be also useful to keep horizontal letter strokes. |
| Horizontal Min Length | The minimum length of the horizontal lines to remove. |
| Vertical Min Length | The minimum length of the vertical lines to remove. |
| Remove Dark Borders | Removes the dark surrounding from bitonal, grayscale or color images. The dark surrounding of the image is whitened (Note: The dark border should be touching the edge of the page for this to work). |
| Punch Hole Removal | Attempts to remove punch holes from pages. Note: The punch hole algorithm can be used on images with the following minimum dimensions width: 300px, height: 100px (computed for 300 DPI). The minimum height and width can vary with the image resolution. |
| Interpolation | Interpolates the source image to the given resolution. This value (the target resolution) must be greater than the source image’s resolution. |
| Interpolation Mode | Sets the interpolation mode. |
| Keep Original Image | Set this to true if you want to use the pre-processed image for OCR but keep the original image in the output document. The default value is true.Note: This property only applies when processing PDF files with the Convert To TIFF set to Yes. |
| Keep Deskewed Image | Set this to true if you want to use the deskewed image in the output document. Note: This property only applies when Keep Original Image is set to No. |
| Keep Despeckled Image | Set this to true if you want to use the despeckled image in the output document. This requires the source image to be black and white. Note: This property only applies when Keep Original Image is set to No. |
| Keep Dark Border Removal | Set this to true if you want to use the image after dark borders have been removed, in the output document. Note: This property only applies when Keep Original Image is set to No. |
| Keep Punch Hole Removal | Set this to true if you want to use the image after punch holes have been removed, in the output document. Note: This property only applies when Keep Original Image is set to No. |
Merge TIFFs to PDF
This step first merges the input images in a folder into a multi-page PDF file, then performs an OCR on the file. Depending upon the Step Type Properties chosen, a separate text, HTML and Office files may be produced from the OCR process.
Standard engine
| Parameter | Notes |
|---|---|
| Output File Name | Target file template which can include %DIRNAME (directory name of the original file). |
| Create Directories if Required | Force creation of any output directories if they don’t already exist. |
| OCR Options | Choose “No OCR” to generate an image-only PDF. Choose “OCR” to generate searchable PDF and/or text files. |
| Continue on Error | Continue processing TIFF files after an error occurs. |
| OCR Language | Select the language the original file is written in. This will determine the dictionary that is used. |
| Deskew | Straighten the image. |
| Auto-Rotate | Automatically rotate pages so that text flows left to right. |
| Despeckle | Remove specks below the specified pixel size from the image. |
| Save Pre-Despeckle | This will use the original image (i.e. before applying pre-processing) in the output PDF. The default value is true. |
| Output PDF | Choose “Yes” to Generate a PDF file. |
| Output TXT | Choose “Yes” to generate a .txt file (only applicable if OCR is specified). |
| Output RTF | Choose “Yes” to generate a .rtf file (only applicable if OCR is specified). |
| Output HTML | Choose “Yes” to generate a .htm file (only applicable if OCR is specified). |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| PDF/A Options | Select the output PDF/A compliant version you would like the output PDF to be: - PDF/A1-b - PDF/A2-b - PDF/A3-b |
| Validate PDF/A | Whether or not to validate the PDF/A document after conversion. |
Convert any file to PDF
This converts any printable document to PDF, such as Microsoft Word, Excel, PowerPoint, HTML, etc. subject to the native application being available on the server. See ToPDF (BCL easyPDF) for more details.
| Parameter | Notes |
|---|---|
| Output File Name | Target file template which can include %FILENAME (original filename without the extension) and %DIRNAME (directory name of the original file). |
| Continue on Error | Continue processing files after an error occurs. |
| Conversion Timeout (ms) | Limits the amount of time in milliseconds that can be spent on conversion. A value of zero means there is no time limit. |
| Convert Bookmarks | For MS Word, convert bookmarks. |
| Bookmark Depth | This property will take effect only when the Convert Bookmarks property is set to True. Numbers defining bookmark levels must be equal to or larger than one. Word style names must not repeat in the string. The string must not start or end with the delimiter. When this property is empty, the default style mapping (Heading one through nine will be mapped to level one through nine) will be used. Therefore, an empty string is functionally equivalent to Heading 1 mapped to 1, Heading 2 mapped to 2, Heading 3 mapped to 3, Heading 4 mapped to 4, Heading 5 mapped to 5, Heading 6 mapped to 6, Heading 7 mapped to 7, Heading 8 mapped to 8, Heading 9 mapped to 9. Note: If you use a non-English version of Microsoft Word, then you may need to replace the word “Heading” with its localized version. |
| Convert Hyperlinks | Sets the flag to indicate whether to convert Word hyperlinks to PDF hyperlinks. |
| Print All Sheets (Excel) | The flag that indicates whether to print all Excel worksheets or not. |
| Print Background Color (IE) | For files printed via IE Sets the flag that indicates whether to print background color or not when printing. |
| Print Scale % (Visio) | For Visio files, sets the print scale. |
| Header (IE) | This property modifies Internet Explorer’s header setting. |
| Footer (IE) | This property modifies Internet Explorer’s footer setting. |
| Image Compression | If you want a lossless image compression, use PRN_IMAGE_COMPRESS_ZIP (ZIP compression). |
| Image Downsizing | If this property is set to Yes, then the resolution of images is reduced to the DPI value specified in the Downsize Resolution DPI property. |
| Downsize Resolution DPI | If the Image Downsizing property is set to True, then the resolution of images is reduced to the DPI value specified in this property. |
| Image JPEG Quality | The allowed value range is from 5 to 100 with 100 being the highest quality. |
| Font Embedding | The option PRN_FONT_EMBED_FULLSET (embedding a full set of fonts) will cause a significant increase in PDF file size, especially for CJK font, and therefore not recommended. If you need to embed the font, PRN_FONT_EMBED_SUBSET (embed subset of fonts) will be a better choice. |
| Font Substitution | For the PRN_FONT_SUBST_TABLE (use font substitution table) option, you need to configure the substitution table. The table is stored under the “Device Setting” section of the printer driver properties (can be accessed from the Control Panel). |
| Embed Fonts as Type 0 | This option is recommended if you have non-standard fonts like barcode font. |
| Top Margin | Sets top margin. (Inches) |
| Bottom Margin | Sets bottom margin. (Inches) |
| Left Margin | Sets left a margin. (Inches) |
| Right Margin | Sets right margin. (Inches) |
| Page Width | Sets a custom page width. (Inches) |
| Page Height | Sets a custom page height. (Inches) |
| Paper Orientation | Sets paper orientation to: - Default (Maintain Source Orientation) - Landscape - Portrait |
| PDF Compliance | Allows the User To choose PDF/A or PDF/X Compliant files - None (No PDF/A Output) - PDF/A-1b (PDF/A-1b compliant) - PDF/X-1a (PDF/X-1a compliant) - PDF/X-3 (PDF/X-3 compliant) |
| Convert MSG Attachments | If you set this to true, DAS will convert both MSG files and their Attachments to a single PDF file. |
| Attach MSG Attachments to PDF | If set to true, DAS will Attach Msg Attachments that are converted as PDF Attachments. If set to false, DAS will merge Msg Attachments that are converted to the PDF file generated by the body. |
| Preserve Word Attachments | Determines whether embedded and linked files will be preserved during conversion. Default value: False (disabled). Note: This will work with WordExtensionEX only. |
| Convert PDF Attachments (PDF) | Convert PDF Attachments to create a combined PDF file. |
| Merge PDF Attachments (PDF) | Set this flag to true if you want to convert pdf attachments and merge them into the output pdf file. Otherwise, the converted files will be merged back to the pdf. |
| Retain PDF Attachment (PDF) | Switch this on to retain the original PDF attachments if you set Merge PDF Attachments to true. |
| Retain Properties (Office) | Set this flag if you want the MS Office properties to be transferred to the target pdf document. |
| Color Type (PowerPoint) | Use this property to set PowerPoint to print with either color, grayscale, or black and white. |
| Handout Order (PowerPoint) | Sets the handout order, this flag only applies to PowerPoint jobs. The possible values are: - Vertical First - Horizontal First |
| Output Type (PowerPoint) | Sets the output type, it only works with the PowerPoint files. The possible values are: - Slides - Build slides - Two slides handouts - Three slides handouts - Four slides handouts - Six slides handouts - Nine slides handouts - Notes - Outline |
| Print Graphics (Publisher) | Sets the graphics setting for printing: - Print Full Resolution - Print Low Resolution - Print Graphics |
| Frame Slides (PowerPoint) | Indicate whether to draw a frame around the border of the slides. |
| Zoom (Excel) | Sets printing zoom of the worksheet. The allowed value range is from 10 to 400. |
| Fit to Pages Wide (Excel) | Sets number of pages wide the worksheet will be scaled to. This property is ignored if the Zoom property is set. |
| Fit to Pages Tall (Excel) | Sets number of pages tall the worksheet will be scaled to. This property is ignored if the Zoom property is set. |
| Include Document Markups | Determines whether document markups are retained. When this property is false (the default), document markups are omitted.When this property is True, markups are included. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. The file will be copied to the password sub directory in the Error Folder. - Take no action. - Move to Error Folder - Copy to Error Folder |
| Debug | Set this to true to execute the step in debug mode. |
Set PDF properties
This is used to set PDF Metadata properties (such as Author, Title, etc.), Security settings and Document Display properties.
| Parameter | Notes |
|---|---|
| Output File Name | Target file template which can include %FILENAME (original filename without the extension), %DIRNAME (directory name of the original file), %UNIQUEn (e.g. %UNIQUE4 for 4 digits), %BOOKMARK and %PAGEn (e.g. %PAGE4 for 4 digits). |
| Encryption Strength | Must be set to 128 bits if security attributes are to be set. |
| User Password | A password that will be required to open the document. |
| Owner Password | A password that will be required to change the document permissions. |
| Allow Printing | Allow high-quality printing. |
| Allow Modify Contents | Allow assembly and other document modifications. |
| Allow Copy | Allow text and graphics copying and extraction. |
| Allow Modify Annotations | Allow modification of annotations. |
| Allow Filling | Allow filling of form fields. |
| Allow Screen Readers | Allow extraction of text and graphics in support of accessibility. |
| Allow Assembly | Allow rotation, insertion or deletion of pages. |
| Allow Degraded Printing | Allow low-quality printing. |
| Author | Sets the Author property. |
| Title | Sets the Title property. |
| Subject | Sets the Subject property. |
| Keywords | Sets the Keywords property. |
| Creator | Sets the Creator property. |
| Page Layout | The setting for the initial document page display. |
| Page Mode | The setting for initial viewer mode. |
| Non-Full Screen Mode | Only applicable where Page Mode=Full Screen. The setting for document page display when exiting Full-Screen mode. |
| Hide Menu Bar | The viewer’s menu bar will be hidden. |
| Hide Window UI | The viewer’s UI elements (scrollbars etc.) will be hidden. |
| Hide Tool Bar | The viewer’s toolbar will be hidden. |
| Fit Window | The viewer will resize the document’s window to fit the size of the first displayed page. |
| Center Window | The document window will be positioned in the center of the screen. |
Custom script
This can be used to support a custom scripted step in the process. See Scripting Custom Steps for more details.
| Parameter | Notes |
|---|---|
| Custom Script File | Name of the custom script file to be run located in the DAS custom folder. |
| Job ID | (Optional) Will send an additional flag with the jobdef file location. For example, a value of 1024 will give the flag “/jobdef:C:\Aquaforest\Autobahn DX/jobdef/1024.xml” given that DAS is installed on the default C drive location. |
Stamp PDF files
This step can be used to add stamps to PDF pages, we have given the user the ability to customize these stamps extensively in a very simple manner. See the step properties below.
| Parameter | Notes |
|---|---|
| Output File Name | Target file template which can include %FILENAME (original filename without the extension), %DIRNAME (directory name of the original file). |
| Stamp Operation | DAS has different ways to apply stamps to a page, this gives the user some level of flexibility. - StampTextAsString: When this operation has selected the text passed as the StampObject will be stamped on the PDF document as text. - StampPDFText: When this operation is selected the text passed as the StampObject will be stamped on the PDF document as an image. - StampPageNumber: When this operation is selected, every page in the PDF file will be stamped with a page number, starting from the start number. For example, if StartNumber = 6 the first-page number will start from 6. - StampPageNumberBates: When this operation is selected, every page in the PDF file will be stamped with a bate number, starting from the start number. For example, if StartNumber = 6 the first-page number will start from 000006. - StampVariable: This option allows a user to specify a variable like a date, filename or time. The variable specified by the StampObject will be stamped on the document. Check the table below for different Stamp variables provided. - StampPDFImage: When this operation is selected the text passed as the StampObject is the address of the image to be stamped on the PDF document. |
| Stamp Placement | The property specifies the location in a page a stamp can be placed. Below is a list of options available. - Bottom Center - Bottom Left - Bottom Right - Center - Center Left - Center Right - Top Center - Top Left - Top Right |
| Stamp Direction | This represents the direction of the stamp on the output PDF. - Normal - Diagonal Up - Diagonal Down |
| Stamp Text | Enter any static text to be stamped on a PDF page, this works with the StampPDFText stamp operation. |
| Stamp Variable | Enter a stamp variable to be stamped on a PDF page, this works with the StampVariable stamp operation. See “Stamp Variables” table below for more details. |
| Image Path | The path to the image if you are using the StampPDFImage operation. |
| Page Range | Set of page ranges separated by commas that define which pages from the original should be stamped. Using * or leaving it blank will process all pages. |
| Start Number | The number that the page numbering will start with, works with StampPageNumber and StampPageNumberBates. |
| Start Page | Specifies the page that the stamping should start. |
| End Page | Specifies the page that the stamping should stop. |
| Bates Prefix | Specifies the prefix of the Bates stamp. |
| Bates Suffix | Specifies the suffix of the Bates stamp. |
| Bates Length | Specifies the length of the Bates stamp. |
| Stamp Color | The color of non-image stamps. Enter a valid color name or black will be used. |
| Stamp Opacity | The opacity of non-image stamps. Enter a valid color name or black will be used. |
| Font Name | The font name of non-image stamps. Choose the font you want from a drop-down list of different fonts. |
| Font Size | The font size of non-image stamps, default value = 20. |
| Stamp Text as Image | Set this to Yes if you want DAS to convert text-based stamps to images before applying it to the PDF page. |
| Image Background Color | When you set Stamp Text as Image to yes, use this property to set the background color of the image(rectangle) that the text is converted to. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. The file will be copied to the password sub directory in the Error Folder. - Take no action - Move to Error Folder - Copy to Error Folder |
| Debug | Set this to true to execute the step in debug mode. |
Stamp variables
The table below shows different Stamp variables supported by DAS. The idea is that DAS will replace an occurrence of the variable with the appropriate value in a text string before applying the stamp. For example, to Stamp Today is Monday on a PDF page, use the following Stamp variable “Today is %A”.
| Variable | Stamp | | -------- | ------------------------------------------------------ | ------------------ | | %a | Short Day (Mon) | | %A | Long Day (Monday) | | %b | Short Month (Jan) | | %B | Long Month (January) | | %c | Date and time (30 October 2013 17:21) | | %C | Date and Time with seconds (30 October 2013 17:21:50) | | %d | Month and Year (October 2013) | | %D | Day and Month (30 October) | | %e | Short Year (13) | | %E | Long Year (2013) | | %f | Short Time of Day (17:21) | | %F | Time of Day with Seconds (17:21:20) | | %G | Full Date and time (Wed, 30 October 2013 17:21:50 GMT) | | %Y | File Name | |
Merge PDF
Merges a folder of PDF files into a single file.
| Parameter | Notes |
|---|---|
| Output File Name | Target file template which can include %DIRNAME (directory name of the original file). |
| Create Directories if Required | Force creation of any output directories if they don’t already exist. |
| Retain Bookmarks | Generated files will include bookmarks from the original file. |
| Retain Metadata | Generated files will include metadata (such as Author and Title) from the original file. |
| File Names as Bookmarks | Generate bookmarks in the output PDF using filenames of source PDF files. |
| Continue on Error | Continue processing if an error occurs. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. - Take no action. - Move to Error Folder - Copy to Error Folder |
| Debug | Set this to true to execute the step in debug mode. |
Split PDF
Splits each input PDF file into a set of files, either a single page per file or by page ranges.
| Parameter | Notes |
|---|---|
| Output File Name | The target file template which can include %UNIQUEn (a unique number starting at 1, zero padded to n digits) %FILENAME (original filename without the extension) and %DIRNAME (directory name of the original file). |
| Create Directories if Required | Force creation of any output directories if they don’t already exist. |
| Retain Bookmarks | Generated files will include bookmarks from the original file. |
| Retain Metadata | Generated files will include metadata (such as Author and Title) from the original file. |
| Split Type | - Single Pages: Splits the file into single pages. - Page Ranges: Splits the file based on the range - Repeated Ranges: Splits the file based on the range and the repeated range. - Bookmarks: Splits the file based on the original bookmarks. |
| Ranges (e.g. 1,3-10) | Set of page ranges separated by commas that define which pages from the original should be extracted. |
| Repeat Every (Pages) | Apply the page range to each set of Page Ranges within the document. For example, if 2-4 is specified for page ranges, and 4 is specified as the repeating range, then the range is re-applied every 4 pages. |
| Continue on Error | Continue processing if an error occurs. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. The file will be copied to the password sub directory in the Error Folder. - Take no action. - Move to Error Folder - Copy to Error Folder |
| Debug | Set this to true to execute the step in debug mode. |
Merge TIFFs
Merges a folder of TIFF files into a single file.
| Parameters | Notes |
|---|---|
| Output File Name | Target file template which can include %DIRNAME (directory name of the original file) |
| Create Directories if Required | Force creation of any output directories if they don’t already exist. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Continue on Error | Continue processing if an error occurs. |
| Debug | Set this to true to execute the step in debug mode. |
Split TIFF
Splits each input TIFF file into a set of files, either a single page per file or by page ranges.
| Parameters | Notes |
|---|---|
| Output File Name | The target file template which can include %UNIQUEn (a unique number starting at 1, zero padded to n digits) %FILENAME (original filename without the extension) and %DIRNAME (directory name of the original file). |
| Create Directories if Required | Force creation of any output directories if they don’t already exist. |
| Split Type | - Single Pages: Splits the file into single pages - Page Ranges: Splits the file based on the range - Repeated Ranges: Splits the file based on the range and the repeated range |
| Ranges (e.g. 1,3-10) | Set of page ranges separated by commas that define which pages from the original should be extracted. |
| Repeat Every (Pages) | Apply the page range to each set of Page Ranges within the document. For example, if 2-4 is specified for page ranges, and 4 is specified as the repeating range, then the range is re-applied every 4 pages. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Continue on Error | Continue processing if an error occurs. |
| Debug | Set this to true to execute the step in debug mode. |
Read inbox
This can read mailboxes and extract attachments using IMAP4 or OAuth2 (Modern) Authentication, in accordance with the parameters specified below. Use of this step type requires a Server License.
Check with your System Administrator and ensure the following for IMAP4:
- IMAP4 is enabled for the mail server and your account.
- You have the IMAP address of the mail server.
For OAuth2, you require an access token from the Microsoft Identity Platform, which will supply you with the credentials to use our email steps with Modern Authentication.
Note: The files will be downloaded in the following format, name@timestamp@email@.ext where:
- name = Filename
- timestamp= Date of the email
- email= ‘From’ address
Example: file1@20210330@john.smith@nutrient.io@.pdf
| Parameter | Notes |
|---|---|
| Authentication Mode | Choose between IMAP and Modern Authentication |
| IMAP Server | The IMAP server address e.g. imap.company.co.uk |
| Require Authentication | If anonymous authentication is set up on your server, a username and password is not needed when setting this option to ‘No’ |
| Username | The username for the account to access the IMAP server |
| Password | Password for the account. This is held encrypted |
| Azure Client ID | The Client ID for OAuth2 Authentication |
| Azure Tenant | The Tenant for OAuth2 Authentication |
| Azure AD Instance | The address of the Azure AD Instance. For example, https://login.microsoftonline.com |
| Credential Type | Select the credential type for OAuth2 Authentication. The options are Client Secret or Certification. |
| Client Secret | The client secret generated by Azure |
| Certificate Path | The path to the certificate generated by Azure |
| Certificate Password | The password of the certificate generated by Azure |
| Source Email Account | The email account to be read. For example, pdf@company.com |
| Mailbox | Mailbox to read. For example, Inbox |
| Processed Mailbox | Mailbox to move processed email to. For example, Deleted Items. If left blank, the emails will be left in the inbox which can be useful for testing |
| Output Template | The template for the name of the output file. This can include %FILENAME% for the original filename, %TIMESTAMP% for the job timestamp, and %FROMADDRESS% for the ‘From’ email address |
| Include | Regular expression. If specified, only files matching the expression will be processed. For example, *.tif. This allows alternate jobs to be created for different file types |
| Exclude | Regular expression. If specified, files matching the expression will not be processed. For example, *.pdf |
| Subject Filter | DAS will only download attachments from email with the subject filter in their subject |
| Debug | Set this to true to execute the step in debug mode |
Send documents
Use of this step type requires a Server License. Attachment limit is 50MB but email provider’s limits are normally lower.
Note: The input file of this step must be in the format of name@timestamp@email@.ext
where:
- name = Filename
- timestamp= date of the email
- email= the address where we will send the output files
Example: file1@20210330@john.smith@nutrient.io@.pdf
| Parameter | Notes |
|---|---|
| Authentication Mode | Choose between SMTP and Modern Authentication |
| Domain | The sending domain. For example, nutrient.io |
| SMTP Server | SMTP Server address. For example, smtp.nutrient.io |
| Require Authentication | If anonymous authentication is set up on your server, a username and password is not needed when setting this option to ‘No’ |
| Username | The username for the account to access the SMTP server |
| Password | Password for the account. This is held encrypted |
| Azure Client ID | The Client ID for OAuth2 Authentication |
| Azure Tenant | The Tenant for OAuth2 Authentication |
| Azure AD Instance | The address of the Azure AD Instance. For example, https://login.microsoftonline.com |
| Credential Type | Select the credential type for OAuth2 Authentication. The options are Client Secret or Certification |
| Client Secret | The Client secret generated by Azure |
| Certificate Path | The path to the certificate generated by Azure |
| Certificate Password | The password of the certificate generated by Azure |
| Sender Name | Name of the sending user. For example, John |
| From Email Address | Sending user. For example, admin@nutrient.io |
| CC Addresses | Email list of CC’d email addresses. Separate addresses with a comma. For example, admin@nutrient.io, admin2@nutrient.io |
| BCC Addresses | Email list of Bcc’d email addresses. Separate addresses with a comma. For example, admin@nutrient.io, admin2@nutrient.io |
| Email Title | The title of the Email |
| Email Body | The body of the Email |
| Allow Multiple Attachments | By default, DAS sends files as individual emails. If set to ‘Yes’ DAS will try to group files by destination and send multiple files in one email |
| Attachment Number Limit | Setting this number limits the number of files that can be attached to one email sent by Autobahn |
| Attachment Total Size Limit | In MB. This value limits the total size of all the files sent in each individual email by Autobahn |
| Use Original Filename | Input filenames must fit a specific format. Select true if you want the final attachment to revert to its original name |
| Debug | Set this to true to execute the step in debug mode |
Convert PDF to TIFF
Rasterizes a PDF file, converting into a multi-page TIFF file.
| Parameter | Notes |
|---|---|
| Output File Name | Target file template which can include %FILENAME (original filename without the extension) |
| Compression | Group 4 (For bitonal images) or LZW (for color). |
| Resolution | The DPI of the resulting TIFF File. |
| Continue on Error | Continue processing if an error occurs. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. The file will be copied to the password sub directory in the Error Folder. - Take no action - Move to Error Folder - Copy to Error Folder |
| Debug | Set this to true to execute the step in debug mode. |
Extract text from PDF
Extracts the raw text from a searchable PDF.
Note:
- This does not perform an OCR process, it just extracts the existing text from the PDF file.
- There is a GdPicture-based step (PDF to Text).
| Parameter | Notes |
|---|---|
| Output File Name | Target file template which can include %FILENAME (original filename without the extension). |
| Continue on Error | Continue processing if an error occurs. |
| Page From | The start of the range of pages from which to extract text. If not specified, a start page of 1 is assumed. |
| Page To | The end of the range of pages from which to extract text. If not specified, the last page is assumed. |
| Page Separator | This allows the definition of an optional page separator string in the output text file. |
| Page Separator Placement | Specifies whether the Page Separator will appear at the beginning or the end of the page. |
| Extract Text Engine | The Extract Text Engine to use: - 0 = PDFBox with Formatting - 1 = BCL - 2 = PDFBox |
| Copy Input PDF to Target Folder | Set to true if you want DAS to copy the input PDF file to the target folder. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. The file will be copied to the password sub directory in the Error Folder. - Take no action - Move to Error Folder - Copy to Error Folder |
| Debug | Set this to true to execute the step in debug mode. |
SharePoint download
This step downloads documents from the specified SharePoint document library ready for processing.
| Parameter | Notes |
|---|---|
| SharePoint Site URL | Site, the URL of the SharePoint site that you want to access. For example, http://localhost/testsite |
| SharePoint Online (Office 365) | Whether or not the upload location is in SharePoint Online (Office 365). |
| Use ADFS | Switch this on if you use Active Directory for your SharePoint User Management. |
| Username | The username used to connect to the SharePoint site. Leave empty to use Windows Credentials (for local SharePoint only). |
| Password | The password used to connect to the SharePoint site. Leave empty to use Windows Credentials (for local SharePoint only). |
| ADFS Host | Provide the name of the Active Directory server. |
| ADFS Relying Party Identifier | Provide the Relying Party Trust identifier for your SharePoint. |
| SharePoint Library | Library, the name of the library that you want to access. For example, “Test Library” |
| SharePoint Sub Folder | Download documents from the specified subfolder in the SharePoint library only. |
| Extension Filter | An optional extension mask that limits those files to manipulate. For example, “pdf,tiff” |
| Recurse SharePoint Library | If set to “Yes” sub-folders of the SharePoint Library are handled. |
| Include Pattern | DAS will only include the files that match this pattern. |
| Exclude Pattern | Any file that matches this pattern will be excluded. |
| Debug | Set to “Yes” to see more processing information on the console. |
| Continue on Error | Continue processing if an error occurs. |
SharePoint upload
This step uploads documents to the specified SharePoint document library.
| Parameter | Notes |
|---|---|
| SharePoint Site URL | The URL of the SharePoint site that you want to access. For example, http://localhost/testsite |
| SharePoint Online (Office 365) | Whether or not the upload location is in SharePoint Online (Office 365). |
| Use ADFS | Switch this on if you use Active Directory for your SharePoint User Management. |
| Username | The username used to connect to the SharePoint site. |
| Password | The password used to connect to the SharePoint site. |
| ADFS Host | Provide the name of the Active Directory server. |
| ADFS Relying Party Identifier | Provide the Relying Party Trust identifier for your SharePoint. |
| SharePoint Library | The name of the library that you want to access. For example, “Test Library” |
| SharePoint Sub Folder | The subfolder inside the SharePoint library to upload the files into. The subfolder should be present in the library or else the following message will be displayed: “The remote server returned an error: (409) Conflict.” |
| Extension Filter | An optional extension mask that limits those files to manipulate. For example, “pdf,tiff” |
| Recurse Source Folder | Recurse the source folder and its subfolders for files to upload and create the folders in SharePoint if they don’t already exist. Note: If “Use Work Folders” is checked, then “Process Sub-Folders” must also be checked for this to work. |
| Create Directories if Required | Force creation of any output directories if they don’t already exist. |
| Include Pattern | Only files that match this pattern will be included. |
| Exclude Pattern | Any file that matches this pattern will be excluded. |
| Debug | If set to “Yes” the user will see more processing information on the console. |
| Continue on Error | Continue processing if an error occurs. |
Azure storage download
This step will download files to your local machine from an Azure storage Container.
| Parameter | Notes |
|---|---|
| Storage Account Name | The name of the Azure storage account you want to download files from. |
| Azure Account Key | Key 1 under the accesskeys section of the storage account in the portal. |
| Container Name | The name of the Azure blob container you want to download files from. |
| Extension Filter | File extension filters separated by commas. For example, .tif,.pdf |
| Recurse Azure Storage | Download documents from folders and subfolders in the SharePoint Library |
| Debug | If set to “Yes” the user will see more processing information on the console. |
Azure storage upload
This step will upload files from your local machine to an Azure storage Container.
| Parameter | Notes |
|---|---|
| Storage Account Name | The name of the Azure storage account you want to upload files to. |
| Azure Account Key | Key 1 under the accesskeys section of the storage account in the portal. |
| Container Name | The name of the Azure blob container you want to upload files to. |
| Extension Filter | File extension filters separated by commas. For example, .tif,.pdf |
| Recurse Local Folder | Upload documents from folders and subfolders of the local folder. |
| Replace Invalid Characters With | A pattern to replace any invalid character Windows File Storage in the file name before downloading. Invalid characters are: ” * : \ < > ? |
| Debug | If set to “Yes” the user will see more processing information on the console. |
Create XML property file
This step takes a PDF input file and generates an XML output file.
| Parameter | Notes |
|---|---|
| Copy the Source PDF to Target Folder | Set to true if you want DAS to copy the input PDF file to the target folder. |
| Continue on Error | Continue processing files after an error occurs. |
| Debug | Set this to true to execute the step in debug mode. |
Optimize PDF
This allows the creation of Web Optimized (Linearize) PDFs.
| Parameter | Notes |
|---|---|
| Linearize – Fast Web View | Set to true to Linearize a PDF file. |
| Continue on Error | Continue processing files after an error occurs. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. The file will be copied to the password sub directory in the Error Folder. - Take no action - Move to Error Folder - Copy to Error Folder |
| Debug | Set this to true to execute the step in debug mode. |
OCR any file to PDF
This step attempts to convert all files to searchable PDFs, DAS may have the following OCR engines.
- Standard Engine
- GdPicture Engine
- Extended Engine
See Standard OCR vs Extended OCR(opens in a new tab) for the differences.
Standard engine
| Parameter | Notes |
|---|---|
| General Settings | |
| Output File Name | Target file template which can include %FILENAME (original filename without the extension) and %DIRNAME (directory name of the original file). |
| Create Directories if Required | Force creation of any output directories if they don’t already exist. |
| Continue on Error | Continue processing TIFF files after an error occurs. |
| Overwrite Existing | Overwrites the target document if it exists. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. The file will be copied to the password sub directory in the Error Folder. - Take no action. - Move to Error Folder - Copy to Error Folder |
| Maximum Cores | This specifies the number of parallel files you want to be processed at a given time. Note: You need the Multicore license for this. |
| Debug | Set this to true to execute the step in debug mode. |
| Standard OCR Settings | |
| OCR Language | Select the language the original file is written in. This will determine the dictionary that is used. |
| Deskew | Straighten the image. |
| Auto-Rotate | Automatically rotate pages so that text flows left to right. |
| Despeckle | Remove specks below the specified pixel size from the image. |
| OCR to Text File | Choose “Yes” to Generate text Output. |
| Output File | - Plain Text (txt) - Plain Text (txt) No PDF - MS Word (rtf) - HTML |
| Non-Image PDFs | This allows control over the treatment of non-image PDFs. For example, PDFs that have some text in them as well as images. The options are: - OCR: The document will be OCRed using the image method defined by “Image Method”. - Raise Error: The task will terminate with an error. If “On Error Continue” is set this then behaves as Skip. This is the default. - Skip: The document will not be processed. - Pass Through: The file will not be processed, but a copy of the document will be made and named as if the processing had occurred. |
| Remove Hidden Text | This applies only when a PDF is being used as the source for OCR. When set to true this will not include any searchable text layers that already exist from the source document. Such functionality might be useful if the source document was created by OCR of an image only PDF or other image file and the quality of the text from the previous OCR is poor. Note: There is no way to distinguish text added as a result of OCR from text added by other means and as a result, this option should be used with care. |
| Convert to TIFF | Choose the method for PDF image extraction. - No: (Native) - Yes: (Convert to TIFF) |
| DPI | When OCRing a PDF, the PDF is rasterized to produce a TIFF file which is then OCRed. By default, the TIFF image resolution is determined from the images embedded in the source PDF but this flag can be used to override default processing and specify the DPI of the TIFF that will be generated. |
| TIFF Compression | Sets the Compression for the TIFF file used if the “Convert To TIFF” Option above is used. - Auto (Selects Group 4 if the page is Black AND White else it uses LZW Compression) - Group 4 (Black and White) - LZW (Colored) |
| Retain Metadata | Copy metadata from the source PDF to the Searchable result PDF. |
| Retain Bookmarks | Copy bookmarks from the source PDF to the Searchable result PDF. |
| Retain Viewer Preferences | Retains any PDF Viewer Preferences, Page Mode and Page Layout from the source file in the output when using Convert To TIFF=‘Yes’. |
| PDF/A Options | Select the output PDF/A compliant version you would like the output PDF to be. - PDF/A1-b - PDF/A2-b - PDF/A3-b |
| Validate PDF/A | Whether or not to validate the PDF/A document after conversion. |
| Box/Graphics Processing | By default, if an area of the document is identified as a graphic area then no OCR processing is run on that area. However, certain documents may include areas or boxes that are identified as “graphics” or “picture” areas but that actually do contain useful text. To ensure that the OCR engine can be forced to process such areas there are two options: - Treat all Graphics Areas as Text: This option will ensure the entire document is processed as text. - Remove Box Lines in OCR Processing: This option is ideal for forms where sometimes boxes around text can cause an area to be identified as graphics. This option removes boxes from the temporary copy of the imaged used by the OCR engine. It does not remove boxes from the final image. Technically, this option removes connected elements with a minimum area (by default 100 pixels). |
| Line Removal in OCR Processing | This removes lines and boxes during OCR processing to improve recognition – particularly in cases where characters “touch” lines. |
| JBIG2 Compression | This option will compress bitonal images in generated PDFs using JBIG2 compression rather than the default Group 4 compression scheme. This will result in smaller PDF file sizes, at a cost of increased processing time. |
| MRC Compression | Applies Mixed Raster Compression which can drastically reduce the size of PDF documents. |
| Save Pre-Despeckle | This will use the original image (i.e. before applying pre-processing) in the output PDF. The default value is true. |
| StampName | This has been deprecated, use the Stamp PDF Files step. |
| StampValue | This has been deprecated, use the Stamp PDF Files step. |
| Any File To PDF Conversion Settings | |
| Conversion Timeout (ms) | Limits the amount of time in milliseconds that can be spent on conversion. A value of zero means waits indefinitely. |
| Convert Bookmarks | For MS Word, convert bookmarks |
| Bookmark Depth | This property will take effect only when the Convert Bookmarks property is set to True. Numbers defining bookmark levels must be equal to or larger than one. Word style names must not repeat in the string. The string must not start or end with the delimiter. When this property is empty, the default style mapping (Heading one through nine will be mapped to level one through nine) will be used. Therefore, an empty string is functionally equivalent to Heading 1 mapped to 1, Heading 2 mapped to 2, Heading 3 mapped to 3, Heading 4 mapped to 4, Heading 5 mapped to 5, Heading 6 mapped to 6, Heading 7 mapped to 7, Heading 8 mapped to 8, Heading 9 mapped to 9. Note: If you use a non-English version of Microsoft Word, then you may need to replace the word “Heading” with its localized version. |
| Convert Hyperlinks | Sets the flag to indicate whether to convert Word hyperlinks to PDF hyperlinks. |
| Print All Sheets (Excel) | The flag that indicates whether to print all Excel worksheets or not. |
| Print Background Color (IE) | For files printed via IE Sets the flag that indicates whether to print background color or not when printing. |
| Print Scale % (Visio) | For Visio files, sets the print scale. |
| Header (IE) | This property modifies Internet Explorer’s header setting. |
| Footer (IE) | This property modifies Internet Explorer’s footer setting. |
| Image Compression | If you want a lossless image compression, use PRN_IMAGE_COMPRESS_ZIP (ZIP compression). |
| Image Downsizing | If this property is set to Yes, then the resolution of images is reduced to the DPI value specified in the Downsize Resolution DPI property. |
| Downsize Resolution DPI | If the Image Downsizing property is set to True, then the resolution of images is reduced to the DPI value specified in this property. |
| Image JPEG Quality | The allowed value range is from 5 to 100 with 100 being the highest quality. |
| Font Embedding | The option PRN_FONT_EMBED_FULLSET (embedding a full set of fonts) will cause a significant increase in PDF file size, especially for CJK font, and therefore not recommended. If you need to embed the font, PRN_FONT_EMBED_SUBSET (embed subset of fonts) will be a better choice. |
| Font Substitution | For the PRN_FONT_SUBST_TABLE (use font substitution table) option, you need to configure the substitution table. The table is stored under the “Device Setting” section of the printer driver properties (can be accessed from the Control Panel). |
| Embed Fonts as Type 0 | This option is recommended if you have non-standard fonts like barcode font. |
| Top Margin | Sets top margin. (Inches) |
| Bottom Margin | Sets bottom margin. (Inches) |
| Left Margin | Sets left margin. (Inches) |
| Right Margin | Sets right margin. (Inches) |
| Page Width | Sets a custom page width. (Inches) |
| Page Height | Sets a custom page height. (Inches) |
| Paper Orientation | Sets paper orientation to - Default (Maintain Source Orientation) - Landscape - Portrait |
| PDF Compliance | Allows the User To choose PDF/A or PDF/X Compliant files: - None (No PDF/A Output) - PDF/A-1b (PDF/A-1b compliant) - PDF/X-1a (PDF/X-1a compliant) - PDF/X-3 (PDF/X-3 compliant) |
| Convert MSG Attachments | If you set this to true, DAS will convert both MSG files and their Attachments to a single PDF file. |
| Attach MSG Attachments to PDF | If set to true, DAS will Attach Msg Attachments that are converted as PDF Attachments. If set to false, DAS will merge Msg Attachments that are converted to the PDF file generated by the body. |
| Preserve Word Attachments | Determines whether embedded and linked files will be preserved during conversion. Default value: False (disabled). Note: This will work with WordExtensionEX only |
| Convert PDF Attachments (PDF) | Convert PDF Attachments to create a combined PDF file. |
| Merge PDF Attachments (PDF) | Set this flag to true if you want to convert pdf attachments and merge them into the output pdf file. Otherwise, the converted files will be merged back to the pdf. |
| Retain PDF Attachment (PDF) | Switch this on to Retain the Original PDF attachments if you set Merge PDF Attachments to true. |
| Retain Properties (Office) | Set this flag if you want the MS Office properties to be transferred to the target pdf document. |
| Color Type (PowerPoint) | Use this property to set PowerPoint to print with either color, grayscale, or black and white. |
| Handout Order (PowerPoint) | Sets the handout order, this flag only applies to PowerPoint jobs. The possible values are: - Vertical First - Horizontal First |
| Output Type (PowerPoint) | Sets the output type, it only works with the PowerPoint files. The possible values are: - Slides - Build slides - Two slides handouts - Three slides handouts - Four slides handouts - Six slides handouts - Nine slides handouts - Notes - Outline |
| Print Graphics (Publisher) | Sets the graphics setting for printing. - Print Full Resolution - Print Low Resolution - Print Graphics |
| Frame Slides (PowerPoint) | Indicate whether to draw a frame around the border of the slides. |
| Zoom (Excel) | Sets printing zoom of the worksheet. The allowed value range is from 10 to 400. |
| Fit to Pages Wide (Excel) | Sets number of pages wide the worksheet will be scaled to. This property is ignored if the Zoom property is set. |
| Fit to Pages Tall (Excel) | Sets number of pages tall the worksheet will be scaled to. This property is ignored if the Zoom property is set. |
| Include Document Markups | Determines whether document markups are retained. When this property is false (the default), document markups are omitted.When this property is True, markups are included. |
Extended engine
| Parameter | Notes |
|---|---|
| General Settings | |
| Output File Name | Target file template which can include %FILENAME (original filename without the extension) and %DIRNAME (directory name of the original file) |
| Create Directories if Required | Force creation of any output directories if they don’tdon’t already exist. |
| Continue on Error | Continue processing TIFF files after an error occurs. |
| Overwrite Existing | Overwrites the target document if it exists. |
| Advanced Flags | Command line flags to be passed through to the underlying executable. |
| Password Files | This option specifies what DAS does when it encounters a password protected PDF file. The file will be copied to the password sub directory in the Error Folder. - Take no action. - Move to Error Folder - Copy to Error Folder |
| Maximum Cores | This specifies the number of parallel files you want to be processed at a given time. Note: You need the multi-core license for this. |
| Debug | Set this to true to execute the step in debug mode. |
| Extended OCR Settings | |
| Output File Type | One or more of the following, separated by commas if more than one is required. - CSV _ - DOCX - EPUB - EXCELML _ - HTM - OPENTXT - RTF - TXT - WORDML - XLSX * - XPS *These output formats are suitable for table-oriented pages that can be mapped onto a spreadsheet format. |
| OCR Engine | The OCR engine to use. This must be set to use the IRIS engine. |
| OCR Language 1-8 | You can set up to eight different languages for OCR recognition in one page, as long as they are in the same character set. |
| Automatic language detection | Property that enables or disables the Auto Language Detection feature. The aim of this feature is to detect the most probable language of a single-language page. If at least one language has been detected, recognition will be performed in the first language candidate that has been detected, and not in the language(s) set through Language or Languages. If it fails to detect a language, recognition will be performed using the language(s) set through Language or Languages. |
| Auto rotate | Detect page orientation and correct if required |
| Deskew | Rotates the image to correct its skew angle. |
| Advanced Deskew | Set this to true to define advanced deskew properties. |
| Force Deskew | Under certain circumstances, rotating the image to correct its skew angle may decrease the OCR accuracy. The extended engine is able to analyze the image and detect from an OCR accuracy point of view whether it’s better to rotate the image or not. Because the skew angle may be visible in the output document (For example, if KeepDeskew is set to true), you can choose to force the deskew to rotate the image, even if it affects the accuracy.If turned off, the image is analyzed before rotation and the engine may choose not to rotate the image depending on the analysis result. If turned on, the image is rotated to correct skew angle. |
| Adjustment Mode | Set the behavior regarding dimension adjustment for deskew operation. |
| Despeckle | Removes all the groups of connected pixels with a few pixels below the parameter. Suggested range: 1-20. |
| Advanced Despeckle | Set the advanced despeckle settings, advanced despeckle provides advanced image noise reduction features by the image despeckle filter. |
| Remove White Pixels | By default, Advanced Despeckle removes black pixels. If this setting is set to true, white pixels will be removed instead of black pixels. |
| Dilate | Despeckle removes all the groups of connected pixels with a few pixels below the SpeckleSize parameter. Those connected pixels are not removed if the distance to a larger connected component is below this parameter. As a result, only the isolated pixels get deleted. The maximum value for this property is 20 pixels. The default value is 0. |
| Layout | The layout for the docx or rtf document: - Standard - Flow |
| PDF Version | This determines the PDF version of the generated PDF: - 1.4 - 1.5 - 1.6 - 1.7 - 1.7 Extension Level 3 - 1.7 Extension Level 5 - 1.7 Extension Level 8 - PDF/A-1a - PDF/A-1b - PDF/A-2a - PDF/A-2b - PDF/A-3a - PDF/A-3b |
| Remove Blank Page | Set this to true to remove blank pages from Tiff or PDF documents. Value needs to be set for sensitivity (see below). |
| Sensitivity | The sensitivity, from 1 to 100. With high sensitivity, fewer blank pages are detected. |
| Work Depth | This parameter (0 – 255) defines how deeply the OCR engine will analyze a page with 255 being the deepest. For poorer quality documents, higher values can give better recognition results. |
| JPEG Quality | This parameter (0–255) determines the compression/quality of color JPEG images in generated PDFs. 0 gives the smallest file size whilst 255 gives the best quality. The default value is 128. |
| JPEG2000 Compression | Enable/Disable JPEG2000 Compression. |
| JPEG2000 Compression Mode | The JPEG2000 Compression Mode to use. |
| JPEG2000 Compression Value | The Value to set for the selected Compression Mode. |
| IHQC Compression | Apply Intelligent High-Quality Compression. |
| IHQC Compression Level | Level 1 is the basic compression level while level 3 is the most advanced Intelligent High-Quality Compression Mode. |
| IHQC Quality Factor | The quality Factor for IHQC. |
| No OCR | Whether are not to perform OCR on the document (Yes to not perform OCR, No to perform OCR). |
| Binarization | Whether or not to perform binarization on the document. |
| Brightness | The brightness (higher values will make the result darker). |
| Contrast | The contrast (lower values will make the result darker). |
| Smoothing Level | Smoothing may be useful to binarize text with a colored background to avoid noisy pixels (0 disables smoothing, higher values smooth more). |
| Undithering | Whether or not to use automatic undithering while processing a page. Note: Automatic undithering will be applied only if smoothing is also activated (Smoothing Level). Dithering is a scanning technique which consists in representing a color or grayscale image using only a limited color palette. This allows reducing file size while maintaining the general aspect of the image. This technique is known to create images more difficult to handle for OCR technology; therefore specific image preprocessing is needed to detect and revert it. |
| Threshold | Sets the threshold for fixed threshold binarization (0 for automatic threshold computation). |
| Remove Lines | Whether or not to remove lines from an image (The image must be black and white). |
| Horizontal Clean X | The parameter for cleaning noisy pixels attached to the horizontal lines. |
| Horizontal Clean Y | The parameter for cleaning noisy pixels attached to the horizontal lines. |
| Vertical Clean X | The parameter for cleaning noisy pixels attached to the vertical lines. |
| Vertical Clean Y | The parameter for cleaning noisy pixels attached to the vertical lines. |
| Horizontal Dilate | The dilate parameter that helps the detection of horizontal lines. |
| Vertical Dilate | The dilate parameter that helps the detection of vertical lines. |
| Horizontal Max Gap | The maximum horizontal line gap to close. It is useful to remove broken lines. |
| Vertical Max Gap | The maximum vertical line gap to close. It is useful to remove broken lines. |
| Horizontal Max Thickness | The maximum thickness of the horizontal lines to remove. It is useful to keep vertical lines larger than this parameter. Can be also useful to keep vertical letter strokes. |
| Vertical Max Thickness | The maximum thickness of the vertical lines to remove. It is useful to keep horizontal lines larger than this parameter. Can be also useful to keep horizontal letter strokes. |
| Horizontal Min Length | The minimum length of the horizontal lines to remove. |
| Vertical Min Length | The minimum length of the vertical lines to remove. |
| Remove Dark Borders | Removes the dark surrounding from bitonal, grayscale or color images. The dark surrounding of the image is whitened (Note: The dark border should be touching the edge of the page for this to work). |
| Punch Hole Removal | Attempts to remove punch holes from pages. Note: The punch hole algorithm can be used on images with the following minimum dimensions width: 300px, height: 100px (computed for 300 DPI). The minimum height and width can vary with the image resolution. |
| Interpolation | Interpolates the source image to the given resolution. This value (the target resolution) must be greater than the source image’s resolution. |
| Interpolation Mode | Sets the interpolation mode. |
| Keep Original Image | Set this to true if you want to use the pre-processed image for OCR but keep the original image in the output document. The default value is true.Note: This property only applies when processing image files or PDF files with the Convert To TIFF set to Yes. |
| Keep Deskewed Image | Set this to true if you want to use the deskewed image in the output document. Note: This property only applies when Keep Original Image is set to No. |
| Keep Despeckled Image | Set this to true if you want to use the despeckled image in the output document. This requires the source image to be black and white. Note: This property only applies when Keep Original Image is set to No. |
| Keep Dark Border Removal | Set this to true if you want to use the image after dark borders have been removed, in the output document. Note: This property only applies when Keep Original Image is set to No. |
| Keep Punch Hole Removal | Set this to true if you want to use the image after punch holes have been removed, in the output document. Note: This property only applies when Keep Original Image is set to No. |
| Any File To PDF Conversion Settings | |
| Conversion Timeout (ms) | Limits the amount of time in milliseconds that can be spent on conversion. A value of zero means waits indefinitely. |
| Convert Bookmarks | For MS Word, convert bookmarks. |
| Bookmark Depth | This property will take effect only when the Convert Bookmarks property is set to True. Numbers defining bookmark levels must be equal to or larger than one. Word style names must not repeat in the string. The string must not start or end with the delimiter. When this property is empty, the default style mapping (Heading one through nine will be mapped to level one through nine) will be used. Therefore, an empty string is functionally equivalent to: Heading 1 mapped to 1, Heading 2 mapped to 2, Heading 3 mapped to 3, Heading 4 mapped to 4, Heading 5 mapped to 5, Heading 6 mapped to 6, Heading 7 mapped to 7, Heading 8 mapped to 8, Heading 9 mapped to 9. Note: If you use a non-English version of Microsoft Word, then you may need to replace the word “Heading” with its localized version. |
| Convert Hyperlinks | Sets the flag to indicate whether to convert Word hyperlinks to PDF hyperlinks. |
| Print All Sheets (Excel) | The flag that indicates whether to print all Excel worksheets or not. |
| Print Background Color (IE) | For files printed via IE Sets the flag that indicates whether to print background color or not when printing. |
| Print Scale % (Visio) | For Visio files, sets the print scale. |
| Header (IE) | This property modifies Internet Explorer’s header setting. |
| Footer (IE) | This property modifies Internet Explorer’s footer setting. |
| Image Compression | If you want a lossless image compression, use PRN_IMAGE_COMPRESS_ZIP (ZIP compression). |
| Image Downsizing | If this property is set to Yes, then the resolution of images is reduced to the DPI value specified in the Downsize Resolution DPI property. |
| Downsize Resolution DPI | If the Image Downsizing property is set to True, then the resolution of images is reduced to the DPI value specified in this property. |
| Image JPEG Quality | The allowed value range is from 5 to 100 with 100 being the highest quality. |
| Font Embedding | The option PRN_FONT_EMBED_FULLSET (embedding a full set of fonts) will cause a significant increase in PDF file size, especially for CJK font, and therefore not recommended. If you need to embed the font, PRN_FONT_EMBED_SUBSET (embed subset of fonts) will be a better choice. |
| Font Substitution | For the PRN_FONT_SUBST_TABLE (use font substitution table) option, you need to configure the substitution table. The table is stored under the “Device Setting” section of the printer driver properties (can be accessed from the Control Panel). |
| Embed Fonts as Type 0 | This option is recommended if you have non-standard fonts like barcode font. |
| Top Margin | Sets top margin. (Inches) |
| Bottom Margin | Sets bottom margin. (Inches) |
| Left Margin | Sets left margin. (Inches) |
| Right Margin | Sets right margin. (Inches) |
| Page Width | Sets a custom page width. (Inches) |
| Page Height | Sets a custom page height. (Inches) |
| Paper Orientation | Sets paper orientation to: - Default (Maintain Source Orientation) - Landscape - Portrait |
| PDF Compliance | Allows the User To choose PDF/A or PDF/X Compliant files: - None (No PDF/A Output) - PDF/A-1b (PDF/A-1b compliant) - PDF/X-1a (PDF/X-1a compliant) - PDF/X-3 (PDF/X-3 compliant) |
| Convert MSG Attachments | If you set this to true, DAS will convert both MSG files and their Attachments to a single PDF file. |
| Attach MSG Attachments to PDF | If set to true, DAS will Attach Msg Attachments that are converted as PDF Attachments. If set to false, DAS will merge Msg Attachments that are converted to the PDF file generated by the body. |
| Preserve Word Attachments | Determines whether embedded and linked files will be preserved during conversion. Default value: False (disabled). Note: This will work with WordExtensionEX only. |
| Convert PDF Attachments (PDF) | Convert PDF Attachments to create a combined PDF file. |
| Merge PDF Attachments (PDF) | Set this flag to true if you want to convert pdf attachments and merge them into the output pdf file. Otherwise, the converted files will be merged back to the pdf. |
| Retain PDF Attachment (PDF) | Switch this on to Retain the Original PDF attachments if you set Merge PDF Attachments to true. |
| Retain Properties (Office) | Set this flag if you want the MS Office properties to be transferred to the target pdf document. |
| Color Type (PowerPoint) | Use this property to set PowerPoint to print with either color, grayscale, or black and white. |
| Handout Order (PowerPoint) | Sets the handout order, this flag only applies to PowerPoint jobs. The possible values are: - Vertical First - Horizontal First |
| Output Type (PowerPoint) | Sets the output type, it only works with the PowerPoint files. The possible values are: - Slides - Build slides - Two slides handouts - Three slides handouts - Four slides handouts - Six slides handouts - Nine slides handouts - Notes - Outline |
| Print Graphics (Publisher) | Sets the graphics setting for printing. - Print Full Resolution - Print Low Resolution - Print Graphics |
| Frame Slides (PowerPoint) | Indicate whether to draw a frame around the border of the slides. |
| Zoom (Excel) | Sets printing zoom of the worksheet. The allowed value range is from 10 to 400. |
| Fit to Pages Wide (Excel) | Sets number of pages wide the worksheet will be scaled to. This property is ignored if the Zoom property is set. |
| Fit to Pages Tall (Excel) | Sets number of pages tall the worksheet will be scaled to. This property is ignored if the Zoom property is set. |
| Include Document Markups | Determines whether document markups are retained. When this property is false (the default), document markups are omitted.When this property is True, markups are included. |
Barcode TIFF/PDF
This step can detect barcodes in TIFF/PDF files and either Split/Rename the file based on the barcodes detected.
| Screen field/button | Description |
|---|---|
| Output File Name | The output file path template where the split files will be saved. - %VALUE%: Replaced by the barcode value found.- %INDEX%: Replaced by the current split index.- %FILENAME%: Replaced by the file name |
| Output File Name (No Barcode) | The renaming template to use for page ranges where no barcodes were identified. Allowed templates: - %INDEX%: Replaced by the current split index.- %FILENAME%: Replaced by the filename of the source file. |
| Barcode Operation | Select between Split by Barcode or Rename by Barcode. - Split by Barcode: Choose this option to split the TIFF/ PDF file by Barcode. - Rename by Barcode: Choose this option to rename the TIFF/PDF file based on Barcode. |
| Split Mode | Various Options for splitting Files by Barcode: - Barcode on First Page - Barcode on Last Page - Remove Barcode Page |
| Barcode Format | Barcode formats supported. |
| Try Harder | Spend more time to try to find a barcode; optimize for accuracy, not speed. The default is true. |
| Overwrite Existing | Overwrites any file that exists with the same name in the output folder. Note: If you have the same barcode in different pages or files, they will be overwritten if this is set to true. |
| Metadata Name | Choose the Metadata field you want to set the ‘Metadata Value’ for. The named fields below will have the value added to them when set. - Author - Creator - Keywords - Producer - Subject - Title - Trapped Any other entry will be used as the name for a new custom metadata item. |
| Metadata Value | Enter a value for the Metadata Value. Alternatively, you can use the following file naming variables: - %VALUE%: Replaced by the barcode value found.- %INDEX%: Replaced by the current split index.- %FILENAME%: Replaced by the file nameNote: ‘Trapped’ metadata only accepts either ‘True’, ‘False’ or ‘Unknown’ as a value. |
| Perform Pre-processing | Do not enable this option unless instructed by Nutrient support. |
| Binarize | Set this to true to get better results from colored files. |
| Deskew | Straighten the image. |
| Remove Lines | Whether or not to remove lines from an image. |
| Despeckle | Remove specks below the specified pixel size from the image. |
| Box Size | This option is ideal for forms where sometimes boxes around text can cause an area to be identified as graphics. This option removes boxes from the temporary copy of the imaged used by the barcode reader. Technically, this option removes connected elements with a minimum area (in pixels and defined by this property). This option is currently only applied for bitonal images. |
| Zones | Only examine the region specified for barcode(s). Note: To specify the zone, you need to set the following in the step properties: - Left - Top - Width - Height |
| PDF DPI | The DPI of TIFF images generated from the source PDF file. These images are then used for barcode recognition. |
| TIFF Compression | The compression to set to the TIFF images generated or converted from the source PDF file. These images are then used for barcode recognition. |
| Advanced Flags | Additionally advanced command-line flags may be entered here (see Advanced Flags) |
| Continue on Error | Continue processing TIFF/PDF files after an error occurs. |
| Maximum Cores | The number of parallel files DAS will attempt to process at the same time. |
| Debug | Set this to true to execute the step in debug mode. |
Distributed polling
This step can be used to implement load balancing in DAS. It achieves this by copying a fraction of the files from a central input location to the local system where DAS is running. Multiple DAS servers can point to one input folder, as a result, the files will be shared across several servers and the processing will be more optimized. See Distributed Polling for more details.
| Screen field/button | Description |
|---|---|
| Autobahn Job ID | The Job ID of the Job that will be processing your input files. Note: The Source Folder of this job will be the Destination Folder of the Distributed Polling Job. |
| Limit | The maximum number of files to be copied to the shared folder per run. |
| Extensions | Enter the file extensions you want us to copy separated by a comma. For example, “.pdf,.tif,tiff” |
| Process Sub Folder | Select true if you want to copy subfolders. |
| Debug | Select true if you want to see more debug output. |
DAS content extraction job
This step allows a DAS Content Extraction job to be integrated as an DAS step. See DAS Content Extraction Job Step for more details.
| Screen field/button | Description |
|---|---|
| Kingfisher Job ID | The DAS Content Extraction Job ID |
PDF to PDFA job
This step uses GdPicture libraries to convert a PDF document to a PDFA format.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME to give the input file name without extensions. |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| PDF/A Output Type | Select the type of PDF/A to output. The selection is: PDF/A-1a, PDF/A-1b, PDF/A-2a, PDF/A-2b, PDF/A-2u, PDF/A-3a, PDF/A-3b, PDF/A-3u, PDF/A-4, PDF/A-4e, PDF/A-4f |
| Allow Vectorization | If set to false, the job will attempt to create the PDF/A files without Vectorization. |
| Allow Rasterization | If set to false, the job will attempt to create the PDF/A files without Rasterization. |
| Debug | Select true if you want to see more debug output. |
PDF recognition to JSON job
This step extracts important data from PDF files in the form of key/value pairs. Users can define their expected keys and easily retrieve the data from those fields. No templates are needed.
| Screen field/button | Description |
|---|---|
| Output Expected Key JSON | Creates a JSON file of expected key-values as output. |
| Output Expected Key Values By Page JSON | Creates a JSON file of expected key-values by page as output. |
| Output PDF Data Pages Text | Creates a .txt file of the pdf data by page. |
| Output PDF Data Page Details | Creates a .txt file of key + bounding box, Values + Bounding Boxes by page |
| Output PDF Data Pages As CSV | Creates a CSV containing page number, key, key bounding box, value, value bounding box, page number, page dimensions |
| Output PDF Data Pages As JSON | Creates a CSV containing page number, key, key bounding box, value, value bounding box, page number, page dimensions |
| List PDF Data Pages As JSON | If true, the results of ‘Output PDF Date Pages as JSON’ will be included in the logging |
| Date Format | Set to input date format. |
| Use Currency Symbols | Set to false if you want symbols and strings to be removed before returning currency values. |
| Page Limit | Maximum number of pages to be processed. |
| Page Range | A string representation of the page numbers you want to process. For example, 1,3-4. |
| Current Culture | Choose the expected format of date times if ambiguous For example, 03/07/12 |
| Expected Keys File Paths | File paths of the text files containing expected keys. (use ’ |
| Ignore Case Expected Keys | Choose if Casing is ignored when comparing recognition values to the Expected Keys set. |
| Custom Keys File Paths | File path of the text files containing custom keys. (use ’ |
| Ignore Case Custom Keys | Choose if Casing is ignored when comparing recognition values to the Custom Keys set. |
| Custom Keys Default File Path | The default file path of the text file containing custom keys. (use ’ |
| Load Default Custom Keys | Set to true if you want custom keys to be taken from the default path. |
| Skip Line Width | This value will be multiplied by page width and any line with its width below this calculated value will NOT be skipped. |
| Skip Line Word Count | Do not skip line if the number of words in the line is less than this value. |
| Skip Line Word Space | Any line with an average space greater than this value will NOT be skipped. |
| Ignore Don’t Skip Space | The only time special chunks are broken into smaller chunks is if the space between two adjacent words in the chunk is greater than this value. |
| Chunk Break Space | Any chunk that has two adjacent words with a space between them greater than this value will be chunked. |
| Chunk Break Minimum | If the average space of words in a chunk is smaller than this value, ‘Chunk break space’ will be used to break the chunk instead of this value. |
| Chunk Header Font Size | Any chunk with an average font size below this value will not be considered as a header candidate. |
| Chunk Break Space Header | Any header chunk that has two adjacent words with a space between them greater than this value will be chunked. |
| Break Words By Delimiter | Switch this to true to break words by any of the Chunk Delimiters available (wordDelimiter, chunkDelimiter and chunkSpaceDelimiter). |
| Word Delimiter | Enter one delimiter per index. If any series of characters match this pattern, we will break the word on that index. |
| Chunk Delimiter | Enter one delimiter per line. If any word ends with any of these delimiters, they will be broken into chunks. |
| Chunk Space Delimiter | Enter one delimiter per line. |
| Max Horizontal Space | Skip analyzing key/value chunks that have a horizontal space greater than this value (points) between them. |
| Max Vertical Space | Skip analyzing key/value chunks that have a vertical space greater than this value (points) between them. |
| Data Types To Split | Choose the data types that the Chunker will attempt to split into smaller chunks. |
| Data Types To Check | Choose the data types that will not be split once identified. |
| Data Types To Remove | Choose the unwanted data types that will be removed in post processing. |
| Error On No Expected Keys | When set to Yes, a file that does not contain any values for expected keys will be considered an error. |
| Regex Dictionary Terms File Path | File path of a text file containing regex dictionary terms. (leave blank for default) |
| Plain Dictionary Terms File Path | File path of a text file containing plain dictionary terms. (leave blank for default) |
| Debug | Select true if you want to see more debug output. |
Modern compress PDF
This step uses GdPicture libraries to compress PDF documents with various options.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME to give the input file name without extensions. |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Remove Annotations | Select “Yes” if you want to remove annotations. |
| Remove Blank Pages | Select “Yes” if you want to remove blank pages. |
| Remove Bookmarks | Select “Yes” if you want to remove bookmarks. |
| Remove Embedded Files | Select “Yes” if you want to remove embedded files. |
| Remove Form Fields | Select “Yes” if you want to remove form fields. |
| Remove Hyperlinks | Select “Yes” if you want to remove hyperlinks. |
| Remove JavaScript | Select “Yes” if you want to remove JavaScript. |
| Remove Metadata | Select “Yes” if you want to remove metadata. |
| Remove Page Thumbnails | Select “Yes” if you want to remove page thumbnails. |
| Pack Fonts | Select “Yes” if you want to pack fonts. This greatly optimizes output file size by focusing on fonts. |
| Pack Documents | Select “Yes” if you want to pack document content before saving. |
| Recompress Images | Select “Yes” if you want to recompress images. |
| Enable MRC | Select “Yes” if you want to enable MRC. |
| Downscale Resolution MRC | Set the downscale resolution of the MRC compression. The default value is 100. |
| Preserve Smoothing | Select “Yes” if you want to preserve smoothing. |
| Image Quality | Choose which Image Quality the output files will be. The default value is Medium. |
| Downscale Images | Select “Yes” if you want to downscale images. |
| Downscale Resolution | Set the downscale resolution of the compression. The default value is 150. |
| Enable Color Detection | Select “Yes” if you want to enable automatic color detection. |
| Enable Char Repair | Select “Yes” if you want to enable character repair. |
| Enable JPEG2000 | Select “Yes” if you want to enable JPEG2000. |
| Enable JBIG2 | Select “Yes” if you want to enable JBIG2. |
| JBIG2 PMS Threshold | Set the threshold of the JBIG2 pattern matching and substitution. The default value is 0.85. |
| Debug | Select true if you want to see more debug output. |
Validate PDFA
This step uses GdPicture libraries to validate if the input PDF document conforms to the selected PDFA version.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME to give the input file name without extensions. |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| PDF/A Validation Type | Choose which PDF/A version the files will be validated against. |
| Report Location | Target folder to save reports for files that failed to validate. The location must already exist, or the report will not save. |
| Debug | Select true if you want to see more debug output. |
Linearize PDF
This step uses GdPicture libraries to optimize PDFs for web-viewing, rendering the document one page at a time.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME to give the input file name without extensions. |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Pack Document | Select “Yes” if you want the document to be packed before it is saved, reducing its size. |
| Enable Compression | Select “Yes” if you want to enable compression on the output pdf. |
| Debug | Select true if you want to see more debug output. |
Convert any file to PDF (GdPicture)
This step uses GdPicture libraries to convert a large variety of file types to PDF. This step does not require an Office installation to process Office files.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME to give the input file name without extensions. |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Author | Set the Author metadata field in the output PDF. This can include %FILENAME% (original filename without the extension) or %DIRNAME% (directory name of original file) |
| Title | Set the Title metadata field in the output PDF. This can include %FILENAME% or %DIRNAME% |
| Subject | Set the Subject metadata field in the output PDF. This can include %FILENAME% or %DIRNAME% |
| Keywords | Set the Keywords metadata field in the output PDF. This can include %FILENAME% or %DIRNAME% |
| Producer | Set the Producer metadata field in the output PDF. This can include %FILENAME% or %DIRNAME% |
| Metadata | Set the Metadata field in the output PDF. This can include %FILENAME% or %DIRNAME%. |
| Convert Email Attachments | Select “Yes” if you want to convert email attachments to PDF. |
| Attach Email Attachments To Pdf | Select “Yes” if you want to attach the email attachments to the output PDF. If set to ‘No’, the files will be merged to the PDF if they have been converted to PDF, otherwise they will be removed. |
| Email Page Height | Specifies the page height, in points, of the resulting document when converting from the source Email file. |
| Email Page Width | Specifies the page width, in points, of the resulting document when converting from the source Email file. |
| Email Page Margin Bottom | Specifies the bottom page margin, in points, of the resulting document when converting from the source Email file. |
| Email Page Margin Left | Specifies the left page margin, in points, of the resulting document when converting from the source Email file. |
| Email Page Margin Right | Specifies the right page margin, in points, of the resulting document when converting from the source Email file. |
| Email Page Margin Top | Specifies the top page margin, in points, of the resulting document when converting from the source Email file. |
| Email Prefer One Page | Select “Yes” if you want the email to be converted to a single page PDF if possible. |
| Enable ICC | Specifies if the converter shall favor preserving the International Color Consortium (ICC) profile, if present in the loaded document, during the conversion. |
| Html Emulation Type | Specifies a type of a media to emulate. |
| Html Page Height | Specifies the page height, in points, of the resulting document when converting from the source Html file. |
| Html Page Width | Specifies the page width, in points, of the resulting document when converting from the source Html file. |
| Html Page Margin Bottom | Specifies the bottom page margin, in points, of the resulting document when converting from the source Html file. |
| Html Page Margin Left | Specifies the left page margin, in points, of the resulting document when converting from the source Html file. |
| Html Page Margin Right | Specifies the right page margin, in points, of the resulting document when converting from the source Html file. |
| Html Page Margin Top | Specifies the top page margin, in points, of the resulting document when converting from the source Html file. |
| Html Prefer CSS Page Size | Give any CSS page size declared in the page priority over what is declared in Html Page Width and Html Page Height. If set to false, the renderer will scale the content to fit the paper size. |
| Html Prefer One Page | Specifies whether the output document should contain a single page. |
| Load Only First Page | Specifies that all executed actions with the loaded document will be processed using only the first page of the document. |
| Page Range | Use the string of “1-5” for pages 1 to 5, or use the string of “1,5,6” to specify pages 1 and 5 and 6. You can use the string of “1,5,8-12” to specify pages 1, 5, 8 and all pages from page 8 to page 12, etc. |
| Pdf Bitonal Image Compression | Sets the scheme to be used to compress bitonal image data when converting/saving the currently loaded document to PDF format. ID Scheme 0 None 1 Flate 2 CCITT4 3 JPEG 4 JBIG2 5 JPEG2000 |
| JBIG2 PMS Threshold | Sets the threshold of the JBIG2 pattern matching and substitution. The default value is 0.85. |
| Pdf Color Image Compression | Sets the scheme to be used to compress color image data when converting/saving the currently loaded document to PDF format. |
| Pdf Enable Color Detection | Enables or disables the automatic color detection feature when converting/saving the currently loaded document to PDF format. |
| Pdf Image Quality | Sets the level of quality used to compress images with a lossy compression scheme, which are embedded in the newly produced PDF document when converting/saving the currently loaded document to PDF format. It must be a value from 0 to 100. 0 means the worst quality and the best compression, 100 means the best quality and the worst compression. |
| PDF Use Deflate On JPEG | Specifies if the converter shall use additional Deflate compression for JPEG images in PDF output. |
| Rasterization DPI | Sets the rendering resolution to be used when converting vector content to raster content, if any is included in the currently loaded document. |
| Tiff Enable Exif Rotate | Specifies whether tiff encoder is using Exif rotate flag to handle page rotations. |
| Timeout Milliseconds | Specifies the timeout of the subsequent conversion process, in milliseconds. Default value is -1, which means no timeout. |
| Txt Font Bold | Specifies whether the font used for the resulting document when converting from the source txt file must have a bold style. |
| Txt Font Italic | Specifies whether the font used for the resulting document when converting from the source txt file must have an italic style. |
| Txt Font Family | Specifies the name of the font to be used for the resulting document when converting from the source txt file. |
| Txt Font Size | Specifies the text size, in points, to be used for the resulting document when converting from the source txt file. |
| Txt Horizontal Text Alignment | Specifies the horizontal text alignment of the resulting document when converting from the source txt file. |
| Txt Page Height | Specifies the page height, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Width | Specifies the page width, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Margin Bottom | Specifies the bottom page margin, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Margin Left | Specifies the left page margin, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Margin Right | Specifies the right page margin, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Margin Top | Specifies the top page margin, in points, of the resulting document when converting from the source Txt file. |
| Debug | Select true if you want to see more debug output. |
Combine any file to PDF
This step uses GdPicture libraries to convert a large variety of file types to PDF, and then merges them to create a single output PDF. This step does not require an Office installation to process Office files.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %DIRNAME (original directory name) |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Author | Set the Author metadata field in the output PDF. This can include %FILENAME% (original filename without the extension) or %DIRNAME% (directory name of original file) |
| Title | Set the Title metadata field in the output PDF. This can include %FILENAME% or %DIRNAME% |
| Subject | Set the Subject metadata field in the output PDF. This can include %FILENAME% or %DIRNAME% |
| Keywords | Set the Keywords metadata field in the output PDF. This can include %FILENAME% or %DIRNAME% |
| Producer | Set the Producer metadata field in the output PDF. This can include %FILENAME% or %DIRNAME% |
| Metadata | Set the Metadata field in the output PDF. This can include %FILENAME% or %DIRNAME% |
| Convert Email Attachments | Select “Yes” if you want to convert email attachments to PDF. |
| Attach Email Attachments To Pdf | Select “Yes” if you want to attach the email attachments to the output PDF. If set to ‘No’, the files will be merged to the PDF if they have been converted to PDF, otherwise they will be removed. |
| Email Page Height | Specifies the page height, in points, of the resulting document when converting from the source Email file. |
| Email Page Width | Specifies the page width, in points, of the resulting document when converting from the source Email file. |
| Email Page Margin Bottom | Specifies the bottom page margin, in points, of the resulting document when converting from the source Email file. |
| Email Page Margin Left | Specifies the left page margin, in points, of the resulting document when converting from the source Email file. |
| Email Page Margin Right | Specifies the right page margin, in points, of the resulting document when converting from the source Email file. |
| Email Page Margin Top | Specifies the top page margin, in points, of the resulting document when converting from the source Email file. |
| Email Prefer One Page | Select “Yes” if you want the email to be converted to a single page PDF if possible. |
| Enable ICC | Specifies if the converter shall favor preserving the ICC profile, if present in the loaded document, during the conversion. |
| Html Emulation Type | Specifies a type of a media to emulate. |
| Html Page Height | Specifies the page height, in points, of the resulting document when converting from the source Html file. |
| Html Page Width | Specifies the page width, in points, of the resulting document when converting from the source Html file. |
| Html Page Margin Bottom | Specifies the bottom page margin, in points, of the resulting document when converting from the source Html file. |
| Html Page Margin Left | Specifies the left page margin, in points, of the resulting document when converting from the source Html file. |
| Html Page Margin Right | Specifies the right page margin, in points, of the resulting document when converting from the source Html file. |
| Html Page Margin Top | Specifies the top page margin, in points, of the resulting document when converting from the source Html file. |
| Html Prefer CSS Page Size | Give any CSS page size declared in the page priority over what is declared in Html Page Width and Html Page Height. If set to false, the renderer will scale the content to fit the paper size. |
| Html Prefer One Page | Specifies whether the output document should contain a single page. |
| Load Only First Page | Specifies that all executed actions with the loaded document will be processed using only the first page of the document. |
| Page Range | Use the string of “1-5” for pages 1 to 5, or use the string of “1,5,6” to specify pages 1 and 5 and 6. You can use the string of “1,5,8-12” to specify pages 1, 5, 8 and all pages from page 8 to page 12, etc. |
| Pdf Bitonal Image Compression | Sets the scheme to be used to compress bitonal image data when converting/saving the currently loaded document to PDF format. ID Scheme 0 None 1 Flate 2 CCITT4 3 JPEG 4 JBIG2 5 JPEG2000 |
| JBIG2 PMS Threshold | Sets the threshold of the JBIG2 pattern matching and substitution. The default value is 0.85. |
| Pdf Color Image Compression | Sets the scheme to be used to compress color image data when converting/saving the currently loaded document to PDF format. |
| Pdf Enable Color Detection | Enables or disables the automatic color detection feature when converting/saving the currently loaded document to PDF format. |
| Pdf Image Quality | Sets the level of quality used to compress images with a lossy compression scheme, which are embedded in the newly produced PDF document when converting/saving the currently loaded document to PDF format. It must be a value from 0 to 100. 0 means the worst quality and the best compression, 100 means the best quality and the worst compression. |
| Pdf Use Deflate On JPEG | Specifies if the converter shall use additional Deflate compression for JPEG images in PDF output. |
| Rasterization DPI | Sets the rendering resolution to be used when converting vector content to raster content, if any is included in the currently loaded document. |
| Tiff Enable Exif Rotate | Specifies whether tiff encoder is using Exif rotate flag to handle page rotations. |
| Timeout Milliseconds | Specifies the timeout of the subsequent conversion process, in milliseconds. Default value is -1, which means no timeout. |
| Txt Font Bold | Specifies whether the font used for the resulting document when converting from the source txt file must have a bold style. |
| Txt Font Italic | Specifies whether the font used for the resulting document when converting from the source txt file must have an italic style. |
| Txt Font Family | Specifies the name of the font to be used for the resulting document when converting from the source txt file. |
| Txt Font Size | Specifies the text size, in points, to be used for the resulting document when converting from the source txt file. |
| Txt Horizontal Text Alignment | Specifies the horizontal text alignment of the resulting document when converting from the source txt file. |
| Txt Page Height | Specifies the page height, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Width | Specifies the page width, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Margin Bottom | Specifies the bottom page margin, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Margin Left | Specifies the left page margin, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Margin Right | Specifies the right page margin, in points, of the resulting document when converting from the source Txt file. |
| Txt Page Margin Top | Specifies the top page margin, in points, of the resulting document when converting from the source Txt file. |
| Debug | Select true if you want to see more debug output. |
Combine PDFs
This step uses GdPicture libraries to convert a large variety of file types to PDF, and then merges them to create a single output PDF. This step does not require an Office installation to process Office files.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %DIRNAME (original directory name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Enable Numerical Ordering | When enabled, documents will be merged in numerical order for example, file1, file3, file11, file20, file101. Otherwise it will be ordered lexographically for example, file1, file101, file11, file20, file3 |
| Debug | Select true if you want to see more debug output. |
PDF to JPEG/PDF to PNG/ PDF to TIFF
These steps use GdPicture libraries to convert PDF files into the JPEG, PNG or TIFF format.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME (original file name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Tiff Compression (PDF to TIFF only) | Specifies the TIFF compression when saving images in TIFF format. |
| DPI | The DPI resolution to be used for rendering. A value of 72 will give the same result as Acrobat when zoom level is 100%. Values over 300 will cause excessive memory usage. |
| Brightness | Adjust the Brightness of the output image. Value must be between -100 and 100. |
| Contrast | Adjust the Contrast of the output image. Value must be between -100 and 100. |
| Saturation | Adjust the Saturation of the output image. Value must be between -100 and 100. |
| Gamma | Adjust the Gamma of the output image. Value must be between -100 and 100. |
| Threshold 1BPP | If set, converts the output image to a 1-bit BW indexed color image specifying a threshold value. Pixel values less than the threshold will be turned black, while the values equal to or larger will be turned white. Value must be between 0 and 255. |
| Auto Deskew | Select “Yes” to try to deskew the image to about 15 degrees. Deskewing an image can help a lot to do OCR, OMR, barcode detection or just improve the readability of an image. |
| Crop Black Borders | Detects and removes margins consisting of black color around the image. |
| Crop Black Borders Ex | Detects and sets to White, margins consisting of black color around the image. This does not have the same behavior as Crop Black Borders; The black borders are not removed but are set to blank. Therefore, the image dimensions are kept the same. |
| Crop Area Height | Specifies the page height, in pixels, of the resulting document when cropping. |
| Crop Area Width | Specifies the page width, in pixels, of the resulting document when cropping. |
| Crop Location Left | Specifies the distance, in pixels, to crop from the left of the resulting document. |
| Crop Location Bottom | Specifies the distance, in pixels, to crop from the bottom of the resulting document. |
| Despeckle | Performs a 3x3 despeckle filter. It can remove black noise pixels from white backgrounds and visa versa. It also can remove random noise from multicolored backgrounds. |
| Despeckle More | Performs a 5x5 despeckle filter. It can remove black noise pixels from white backgrounds and visa versa. It also can remove random noise from multicolored backgrounds. |
| Enable ICM | Specifies if color correction is used for images embedding an ICC profile. Enables ICM results in automatic pixel transformation while opening image including an ICC profile. |
| Remove Hole Punch | Removes all punch holes situated on the margins of your image. |
| Remove Lines | Performs line removal on the image in the direction specified. |
| Resize New Height | New image height in pixels, of the resulting document when resizing. |
| Resize New Width | New image width in pixels, of the resulting document when resizing. |
| Resize Interpolation Mode | The interpolation mode to use when resizing the image. |
| Rotate By Angle | Selects whether to rotate by an angle specified, or by a preset type of rotation. |
| Rotation Angle | The angle of rotation for the image. |
| Rotation Type | The method of rotation to apply to the image. |
| Page Range | Use the string of “1-5” for pages 1 to 5, or use the string of “1,5,6” to specify pages 1 and 5 and 6. You can use the string of “1,5,8-12” to specify pages 1, 5, 8 and all pages from page 8 to page 12, etc. |
| Debug | Select true if you want to see more debug output. |
PDF to text
This step uses GdPicture libraries to extract the searchable text from the pages of a PDF file, and creates an output text file. If the page is non-searchable, there is the option to enable OCR.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME (original file name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Page Range | Use the string of “1-5” for pages 1 to 5, or use the string of “1,5,6” to specify pages 1 and 5 and 6. You can use the string of “1,5,8-12” to specify pages 1, 5, 8 and all pages from page 8 to page 12, etc. |
| Page Separator | A text separator that will go between the text of pages |
| Page Separator Placement | The placement of the Page Separator. It can go above or below each page of text |
| Copy Input PDF To Target Folder | Set to true to copy the input pdf to the output location after the text in extracted |
| Preserve Paragraph | Specifies that the text extraction engine must preserve text paragraphs. |
| Paragraph Separator | This property specifies the separator to be utilized for splitting paragraphs. It only takes effect when the PreserveParagraphs property is set to Yes. |
| Enable OCR | Enables the use of the GdPicture OCR engine if the page in non-searchable. |
| OCR Dictionary | Add the code of languages for OCR, separated by ’+’. For example, ‘eng+deu+fra’ would add English, German, and French. |
| Debug | Select true if you want to see more debug output. |
PDF to searchable PDF (GdPicture)
This step uses GdPicture libraries to carry out optical character recognition on the input PDF, creating an invisible searchable text layer over the document.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME (original file name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| OCR Dictionary | Add the code of any additional languages for OCR, separated by +. For example, eng+deu+fra would add English, German and French. Codes can be found in the OCR language codes section. |
| DPI | DPI of TIFF images generated or converted from the source PDF file. These images are then OCRed to create the searchable PDF. |
| Page Range | Use the string of “1-5” for pages 1 to 5, or use the string of “1,5,6” to specify pages 1 and 5 and 6. You can use the string of “1,5,8-12” to specify pages 1, 5, 8 and all pages from page 8 to page 12, etc. |
| Thread Limit | The GdPicture OCR engine processes multiple pages concurrently for optimal performance. This can take a heavy toll on the CPU. If needed, this option allows the number of pages processed consecutively to be limited. |
| Ignore Non Image Pages | Setting this to Yes will skip OCRing any pages that contain fewer images than the image limit threshold. |
| Image Limit | If the page has images that can be ignored (e.g. company logos) you can set an image limit. Any page that contains a number of images equal to or less than the limit will be skipped. |
| Ignore Searchable Pages | Setting this to Yes will skip OCRing any pages that already contain visible text. |
| Ignore Hidden Text | Setting this to Yes will skip OCRing and pages that already contain hidden text. |
| Character Threshold | If a page has some text but you still want to OCR (e.g. Bates numbers), you can set a threshold where pages will be skipped only if they meet this character threshold. If 0, any text found will cause the page to be skipped. |
| Autorotate | Automatically rotate pages if the text does not have the correct orientation. |
| Debug | Select true if you want to see more debug output. |
PDF portfolio
This step uses GdPicture libraries to combine a folder of files into an integrated PDF unit. There are a wide range of file types that can be used to create the PDF Portfolio.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %DIRNAME (original directory name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Pdf Portfolio Type | The initial view mode for the PDF Portfolio. This affects the way the user views the component files after opening the PDF Portfolio file. |
| Debug | Select true if you want to see more debug output. |
Smart redaction
This step uses GdPicture libraries to identify and redact selected sensitive information in the input document.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME (original file name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Redact Credit Card Numbers | Set to true if you want to redact Credit Card Numbers. |
| Redact Email Addresses | Set to true if you want to redact Email Addresses. |
| Redact IBANs | Set to true if you want to redact IBANs. |
| Redact Phone Numbers | Set to true if you want to redact Phone Numbers. |
| Redact URIs | Set to true if you want to redact URIs. |
| Redact VAT IDs | Set to true if you want to redact VAT IDs. |
| Redact Vehicle Identification Numbers | Set to true if you want to redact Vehicle Identification Numbers. |
| Redact Social Security Numbers | Set to true if you want to redact Social Security Numbers. |
| Redact Postal Addresses | Set to true if you want to redact Postal Addresses. |
| Redaction Color | Choose which color will be used for redacting. |
| OCR Dictionary | Add the code of any additional languages for OCR, separated by +. For example, eng+deu+fra would add English, German and French. To install additional dictionaries, see the language codes. |
| Detect Orientation | Select ‘Yes’ if you want to auto detect orientation. |
| Page Range | Use the string of “1-5” for pages 1 to 5, or use the string of “1,5,6” to specify pages 1 and 5 and 6. You can use the string of “1,5,8-12” to specify pages 1, 5, 8 and all pages from page 8 to page 12, etc. |
| Redaction Timeout (ms) | Limits the amount of time in milliseconds that can be spent on a redaction. A value of zero means it will wait indefinitely. |
| Debug | Select true if you want to see more debug output. |
Detect signatures
This step uses GdPicture libraries to identify pdf documents that contain digital signatures.
Any step that alters a digitally signed PDF will invalidate that PDF’s signature. This step allows signed files to be identified, and either copied or moved to a specified folder so the signature can be preserved.
If the Copy option is selected, the original signed file can also be attached to the copy that is processed. This means that the original is attached to the file that can be subsequently processed.
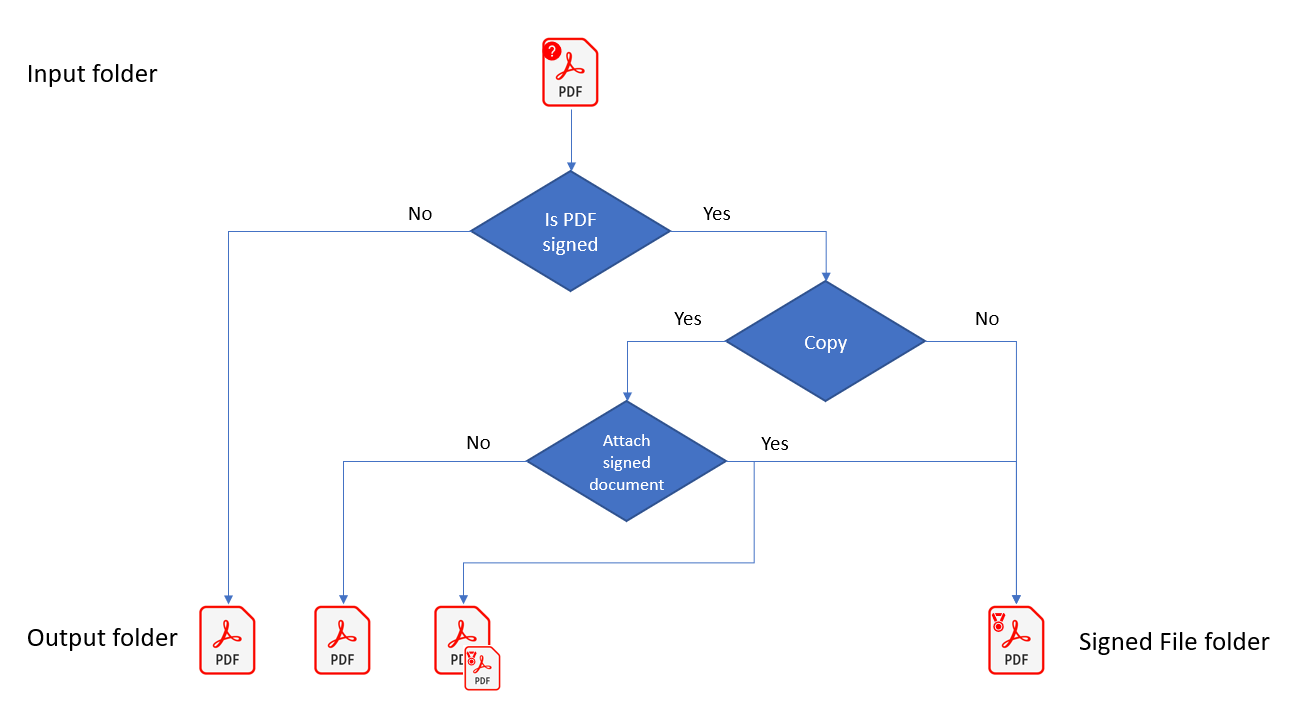
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME (original file name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Signed File Name | Signed file name template which can include %FILENAME (original file name). |
| Signed File Path | The full path (excluding file name) for the location to copy/move the signed file before processing. |
| Create Signed Path | Setting this to “Yes” will create the signed file path directory if it does not exist. The file processing will fail if a signed file is processed, the signed path does not exist, and this is set to ‘No’. |
| Overwrite Signed | Setting this to “Yes” will automatically overwrite any file in the signed file path with the same name as the current signed file. The file processing will fail if the signed file already exists and overwrite is set to false. |
| Signed Action | The action to take if a signed file is detected. It can either be copied or moved to the Signed File Path. |
| Attach Signed Document to Output | Setting this to “Yes” will attach a copy of the signed document to itself before being saved in the output location. This ensures a signed copy will remain with the copy that is processed. |
| Debug | Select true if you want to see more debug information. |
Key-value pair extraction
This step uses the GdPicture engine to extract information about key-value pairs in pdf document. The extra information included can be the Key or Value Bounding Box, Page Number, Confidence, and Data Type.
The user can also use JSON file to declare Expected Keys. These specific keys will be added to a separate output file if a value is found. Synonyms can also be declared for each Expected Key, so that a match for any of the synonyms will be counted as a match for the Expected Key. An example is below.
For example, we have used total and invoice number as the expected keys. grand total is a synonym for ‘total’, and there are two synonyms for invoice number in invoice no and inv no.
[
{
"expectedKey":"total",
"synonyms":\["grand total"\]
},
{
"expectedKey":"invoice number",
"synonyms":\["invoice no", "inv no"\]
}
]CSV output warning
CSV is a format commonly used by spreadsheet programs. These programs commonly transform numerical data or formula, and will save these transformations, overwriting the original data. To prevent these transformations, we add an apostrophe to the start of any possible transformations.
For example, the phone number +44 115 496 0999 will appear as ‘+44 115 496 0999 in the CSV only.
The transformations are listed below.
- Formula - these are generally for values that begin with +, -, =, or @, we add an apostrophe at the beginning for the CSV output. This prevents the CSV from producing unintended formulas and functions from these values.
- Dates/Times – this covers many cases of date and time formats, as data can often be mistaken as a date or time, and then irreversibly transformed.
- Long Numbers – this covers numbers that are 11 digits or longer, as they are transformed to decimal notation
We recommend removing the apostrophes when extracting the data. This only affects CSV output, so it may be easier to extract data from the other formats if possible.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME (original file name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| OCR Language | Add the codes of the languages for OCR and KVP extraction, separated by ‘+’. For example, eng+fra. Codes can be found in the OCR Language Codes section. |
| DPI | DPI used when performing OCR on the file as part of the KVP extraction process. |
| KVP Output Format | This setting determines the file output format(s). KVP data can be output in JSON, CSV and XML. e.g. json,csv,xml. |
| Page Range | Use the string of “1-5” for pages 1 to 5, or use the string of “1,5,6” to specify pages 1 and 5 and 6. You can use the string of “1,5,8-12” to specify pages 1, 5, 8 and all pages from page 8 to page 12, etc. |
| Autorotate | Automatically rotate the page if the text does not have the correct orientation. |
| Trim Symbols | Setting this to “Yes” will remove any symbols from the start/end of values, with the exception of the hash # or period . symbols. |
| Include Key Bounding Box | Setting this to “Yes” will include the bounding box values for the key in the output. |
| Include Value Bounding Box | Setting this to “Yes” will include the bounding box values for the value in the output. |
| Include Page Number | Setting this to “Yes” will include the page number of the key value pair in the output. |
| Include Confidence | Setting this to “Yes” will include the confidence score of the key value pair in the output. Confidence is measured between 0 (no confidence) and 100 (full confidence). |
| Confidence Threshold | The value of confidence (0-100) that a KVP must reach to be included in the output. Results under this confidence threshold will be discarded. |
| Include Type | Setting this to “Yes” will include the data type of the key value pair in the output. |
| Expected Keys | The path to a JSON file for the expected keys and synonyms. |
| Debug | Select true if you want to see more debug information. |
Pattern redaction/pattern highlight
These steps use GdPicture libraries to identify and redact sensitive information (Redaction) or highlight important information (Highlight) in the input document based on a regular expression or terms list.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME (original file name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Pattern | A Regex pattern. The input pdf will be searched for matches to this Regex pattern, and any matches will be redacted/highlighted. |
| Terms Filepath | The path to a text file containing a list of terms to redact/highlight. Each line will be treated as a pattern, and any matches will be redacted/highlighted. |
| Case Sensitive | Determined whether or not the regex pattern matching should be case sensitive. |
| Red | The amount of red color to be used for the redaction/highlighted region color. Use a value between 0 and 255. Default is 0. |
| Green | The amount of green color to be used for the redaction/highlighted region color. Use a value between 0 and 255. Default is 0. |
| Blue | The amount of blue color to be used for the redaction/highlighted region color. Use a value between 0 and 255. Default is 0. |
| Alpha | The transparency value of the resulting region color. Use the value between 0 (full transparency) and 255 (full opacity). Default is 255. |
| Debug | Select true if you want to see more debug output. |
Split PDF (GdPicture)
This step uses GdPicture libraries to split PDF files based on the ranges, bookmarks, or into single pages.
| Screen field/button | Description |
|---|---|
| Output File Name | Target file template which can include %UNIQUEn (unique number starting at 1, zero padded to n digits) %FILENAME (original filename without the extension) and %PAGEn (first page of split, zero padded to n digits) |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Retain Metadata | Generated files will include metadata(such as Author and Title) from the original file. |
| Split Type | Sets the way that the input file will be split. One of: - Split into single pages - Split by ranges (See below) - Split by repeating ranges (See below) - Split by bookmarks |
| Ranges | Set of page ranges separated by commas that defines which pages from the original should be extracted. |
| Repeat Every (Pages) | Apply the page range to each set of Page Ranges pages within the document. For example, if 2-4 is specified for page ranges, and 4 is specified as the repeating range, then the range is re-applied every 4 pages. |
| Remove Unused Resources | Removes unused resources from a pdf file to minimize file size. |
Split PDF by barcode
This step uses GdPicture libraries to identify different barcode types in a PDF, and split the PDF document at each instance of a barcode.
| Screen field/button | Description |
|---|---|
| Output File Name | Target file template which can include %UNIQUEn or %INDEXn (unique number starting at 1, zero padded to n digits) %FILENAME (original filename without the extension) and %PAGEn (first page of split, zero padded to n digits) |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Read QRCode | Set this to true to recognize QRCode barcodes. |
| Read MicroQR | Set this to true to recognize MicroQR barcodes. |
| Read DataMatrix | Set this to true to recognize DataMatrix barcodes. |
| Read PDF417 | Set this to true to recognize PDF417 barcodes. |
| Read Aztec | Set this to true to recognize Aztec barcodes. |
| Read MaxiCode | Set this to true to recognize MaxiCode barcodes. |
| Read Industrial2of5 | Set this to true to recognize Industrial2of5 barcodes. |
| Read Inverted2of5 | Set this to true to recognize Inverted2of5 barcodes. |
| Read Interleaved2of5 | Set this to true to recognize Interleaved2of5 barcodes. |
| Read Iata2of5 | Set this to true to recognize Iata2of5 barcodes. |
| Read Matrix2of5 | Set this to true to recognize Matrix2of5 barcodes. |
| Read Code39 | Set this to true to recognize Code39 barcodes. |
| Read Codabar | Set this to true to recognize Codabar barcodes. |
| Read BcdMatrix | Set this to true``true to recognize BcdMatrix barcodes. |
| Read DataLogic2of5 | Set this to true to recognize DataLogic2of5 barcodes. |
| Read Code128 | Set this to true to recognize Code128 barcodes. |
| Read Code93 | Set this to true to recognize Code93 barcodes. |
| Read EAN13 | Set this to true to recognize EAN13 barcodes. |
| Read EAN8 | Set this to true to recognize EAN8 barcodes. |
| Read UPCA | Set this to true to recognize UPCA barcodes. |
| Read UPCE | Set this to true to recognize UPCE barcodes. |
| Read ADD5 | Set this to true to recognize ADD5 barcodes. |
| Read ADD2 | Set this to true to recognize ADD2 barcodes. |
| Page Range | Specifies the page range to be scanned for barcodes. A value of * will scan every page for barcodes. |
| Pattern | A Regex pattern. The input pdf will be searched for matches to this Regex pattern, and any matches will be redacted. |
| DPI | DPI of TIFF images generated or converted from the source PDF File. These images are then scanned for barcodes. |
| Retain Metadata | Generated files will include metadata(such as Author and Title) from the original file. |
| Remove Unused Resources | Removes unused resources from a pdf file to minimize file size. |
| Left | X coordinate of the Top Left Point of the rectangle you want to recognize the barcode. |
| Top | Y coordinate of the Top Left Point of the rectangle you want to recognize the barcode. |
| Width | Width of the rectangle you want to recognize the barcode. |
| Height | Height of the rectangle you want to recognize the barcode. |
Pattern enumeration
This step uses GdPicture libraries to identify terms and/or a pattern, and it’ll produce a report based on the frequency of each term.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME (original file name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Pattern | A regex pattern. The input PDF will be searched for matches to this regex pattern, and any matches will be redacted/highlighted. |
| Terms Filepath | The path to a text file containing a list of terms to redact/highlight. Each line will be treated as a pattern, and any matches will be redacted/highlighted. |
| Case Sensitive | Determines whether or not the regex pattern matching should be case sensitive. |
| Pass Through | Determines whether or not the input PDF will be copied to the output folder. |
| Debug | Select true if you want to see more debug output. |
Get document information
This step uses GdPicture libraries to produce a report on the number of PDF pages that are searchable vs. an image. It’ll also calculate how many searchable pages are visible text pages vs. hidden text layer.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME (original file name). |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Output Format | Choose the output format for the report: - .txt- .csv- .json- .xml |
| Pass Through | Determines whether or not the input PDF will be copied to the output folder. |
| Debug | Select true if you want to see more debug output. |
Convert PDF to office
This step uses GdPicture libraries to convert PDF input files to various Office output formats, including .docx, .pptx, .xlsx, and .svg.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME to give the input file name without extensions. |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Output Format | Choose the output format for the report: - .docs- .pptx- .xlsx- .svg |
| Enable ICC | Specifies if the converter shall favor preserving the ICC profile if present in the loaded document during the conversion. |
| Page Range | Use the string of “1-5” for pages 1 to 5, or use the string of “1,5,6” to specify pages 1 and 5 and 6. You can use the string of “1,5,8-12” to specify pages 1, 5, 8 and all pages from page 8 to page 12, etc. |
| Timeout Milliseconds | Specifies the timeout of the subsequent conversion process in milliseconds. Default value is -1, which means no timeout. |
| Debug | Select true if you want to see more debug output. |
Convert any file to office
This step uses GdPicture libraries to convert various input file types to various Office output formats, including .docx, .pptx, .xlsx, and .svg. Not all file conversions are supported.
| Screen field/button | Description |
|---|---|
| Output File Name | The template for the output file, which can include %FILENAME to give the input file name without extensions. |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Output Format | Choose the output format for the report: - .doc- .pptx- .xlsx- .svg |
| Author | Set the Author metadata field in the output PDF. This can include %FILENAME% (original filen ame without the extension) or %DIRNAME% (directory name of the original file). |
| Title | Set the Title metadata field in the output PDF. This can include %FILENAME% or %DIRNAME%. |
| Subject | Set the Subject metadata field in the output PDF. This can include %FILENAME% or %DIRNAME%. |
| Keywords | Set the Keywords metadata field in the output PDF. This can include %FILENAME% or %DIRNAME%. |
| Producer | Set the Producer metadata field in the output PDF. This can include %FILENAME% or %DIRNAME%. |
| Metadata | Set the Metadata field in the output PDF. This can include %FILENAME% or %DIRNAME%. |
| Inject Email Header | Specifies whether the email header should be injected into the output document. |
| Convert Email Attachments To Office | Select Yes if you want to convert email attachments to Office. |
| Email Attachments Filter | A regular expression that specifies the attachments that will be converted to Office format. Attachments that don’t match will be skipped. |
| Email Page Height | Specifies the page height, in points, of the resulting document when converting from the source email file. |
| Email Page Width | Specifies the page width, in points, of the resulting document when converting from the source email file. |
| Email Page Margin Bottom | Specifies the bottom page margin, in points, of the resulting document when converting from the source email file. |
| Email Page Margin Left | Specifies the left page margin, in points, of the resulting document when converting from the source email file. |
| Email Page Margin Right | Specifies the right page margin, in points, of the resulting document when converting from the source email file. |
| Email Page Margin Top | Specifies the top page margin, in points, of the resulting document when converting from the source email file. |
| Email Prefer One Page | Select Yes if you want the email to be converted to a single page PDF if possible. |
| Enable ICC | Specifies if the converter shall favor preserving the ICC profile, if present in the loaded document during the conversion. |
| Html Emulation Type | Specifies a type of media to emulate. |
| Html Page Height | Specifies the page height, in points, of the resulting document when converting from the source HTML file. |
| Html Page Width | Specifies the page width, in points, of the resulting document when converting from the source HTML file. |
| Html Page Margin Bottom | Specifies the bottom page margin, in points, of the resulting document when converting from the source HTML file. |
| Html Page Margin Left | Specifies the left page margin, in points, of the resulting document when converting from the source HTML file. |
| Html Page Margin Right | Specifies the right page margin, in points, of the resulting document when converting from the source HTML file. |
| Html Page Margin Top | Specifies the top page margin, in points, of the resulting document when converting from the source HTML file. |
| Html Prefer CSS Page Size | Give any CSS page size declared in the page priority over what is declared in Html Page Width and Html Page Height. If set to false, the renderer will scale the content to fit the paper size. |
| Html Prefer One Page | Specifies whether the output document should contain a single page. |
| Load Only First Page | Specifies that all executed actions with the loaded document will be processed using only the first page of the document. |
| Page Range | Use the string of “1-5” for pages 1 to 5, or use the string of “1,5,6” to specify pages 1 and 5 and 6. You can use the string of “1,5,8-12” to specify pages 1, 5, 8 and all pages from page 8 to page 12, etc. |
| Pdf Bitonal Image Compression | Sets the scheme to be used to compress bitonal image data when converting/saving the currently loaded document to PDF format. - 0: None - 1: Flate - 2: CCITT4 - 3: JPEG - 4: JBIG2 - 5: JPEG2000 |
| JBIG2 PMS Threshold | Sets the threshold of the JBIG2 pattern matching and substitution. The default value is 0.85. |
| Pdf Color Image Compression | Sets the scheme to be used to compress color image data when converting/saving the currently loaded document to PDF format. |
| Pdf Enable Color Detection | Enables or disables the automatic color detection feature when converting/saving the currently loaded document to PDF format. |
| Pdf Image Quality | Sets the level of quality used to compress images with a lossy compression scheme, which are embedded in the newly produced PDF document when converting/saving the currently loaded document to PDF format. It must be a value from 0 to 100. 0 means the worst quality and the best compression, while 100 means the best quality and the worst compression. |
| Pdf Use Deflate On JPEG | Specifies if the converter shall use additional Deflate compression for JPEG images in PDF output. |
| Rasterization DPI | Sets the rendering resolution to be used when converting vector content to raster content, if any is included in the currently loaded document. |
| Render Sheets Headers and Footers | Specifies that the .xls and .xlsx headers and footers should be rendered. Affects XLSX/XLS input only. |
| Split Excel Sheets Into Pages | Specifies that .xls and .xlsx sheets should be split into pages according to the PageSetup element of each sheet. Affects XLSX/XLS input only. |
| Spreadsheet Bottom Margin Override | Specifies the spreadsheet bottom margin height in millimeters. If the height isn’t given or is negative, the margin specified in the document will be used instead. Affects XLSX/XLS input only. |
| Spreadsheet Left Margin Override | Specifies the spreadsheet left margin width in millimeters. If the height isn’t given or is negative, the margin specified in the document will be used instead. Affects XLSX/XLS input only. |
| Spreadsheet Maximum Content Height Per Sheet | Decimal value indicating the maximum height of the sheet content, in millimeters. Maximum content height ignores header and footer height. Affects XLSX/XLS input only. |
| Spreadsheet Maximum Content Width Per Sheet | Decimal value indicating the maximum width of the sheet content, in millimeters. Maximum content width ignores margins. Affects XLSX/XLS input only. |
| Spreadsheet Page Height Override | Specifies the spreadsheet page height in millimeters. If the height isn’t given or is negative, the page height specified in the document will be used instead. Affects XLSX/XLS input only. |
| Spreadsheet Page Width Override | Specifies the spreadsheet page width in millimeters. If the width isn’t given or is positive, the page width specified in the document will be used instead. Affects XLSX/XLS input only. |
| Spreadsheet Render Only Print Area | For spreadsheet, specifies that for each sheets only the print areas must be rendered. If no print area exists, the whole sheets will be rendered. Affects XLSX/XLS input only. |
| Spreadsheet Right Margin Override | Specifies the spreadsheet right margin width in millimeters. If the width isn’t given or is positive, the page height specified in the document will be used instead. Affects XLSX/XLS input only. |
| Spreadsheet Top Margin Override | Specifies the spreadsheet top margin height in millimeters. If the width isn’t given or is positive, the page width specified in the document will be used instead. Affects XLSX/XLS input only. |
| Tiff Enable Exif Rotate | Specifies whether TIFF encoder is using the Exif rotate flag to handle page rotations. |
| Timeout Milliseconds | Specifies the timeout of the subsequent conversion process, in milliseconds. Default value is -1, which means no timeout. |
| Txt Font Bold | Specifies whether the font used for the resulting document when converting from the source TXT file must have a bold style. |
| Txt Font Italic | Specifies whether the font used for the resulting document when converting from the source TXT file must have an italic style. |
| Txt Font Family | Specifies the name of the font to be used for the resulting document when converting from the source TXT file. |
| Txt Font Size | Specifies the text size, in points, to be used for the resulting document when converting from the source TXT file. |
| Txt Horizontal Text Alignment | Specifies the horizontal text alignment of the resulting document when converting from the source TXT file. |
| Txt Page Height | Specifies the page height, in points, of the resulting document when converting from the source TXT file. |
| Txt Page Width | Specifies the page width, in points, of the resulting document when converting from the source TXT file. |
| Txt Page Margin Bottom | Specifies the bottom page margin, in points, of the resulting document when converting from the source TXT file. |
| Txt Page Margin Left | Specifies the left page margin, in points, of the resulting document when converting from the source TXT file. |
| Txt Page Margin Right | Specifies the right page margin, in points, of the resulting document when converting from the source TXT file. |
| Txt Page Margin Top | Specifies the top page margin, in points, of the resulting document when converting from the source TXT file. |
| Debug | Select true if you want to see more debug output. |
Zip folder
This step zips up the input folder and has the option to create a CSV report, which will give information about each zipped file.
| Screen field/button | Description |
|---|---|
| Output Folder Name | The template for the output folder, which can include %DIRNAME to give the input directory name without extensions. |
| Continue on Error | Set to true if the job should continue processing files after a file has failed. |
| Zip Option | Choose the output zip option. Either create one top-level zip, recursively zip each folder (with or without a depth limit), or zip all folders at a specific depth. |
| Subfolder Depth | Depending on the Zip Option, this determines the depth limit to stop recursive zipping, or the specific level to zip at. |
| Create Report | Choose if a report of the zip files should be created. |
| Report Directory | The full path of the report file directory. This path can include %DIRNAME (input folder name), %DATESTAMP (date), or %TIMESTAMP (time the report is created). If left blank, the report will be saved in the output folder. |
| Report Name | The name of the report file without extension. This filename can include %DIRNAME (input folder name), %DATESTAMP (date), or %TIMESTAMP (time the report is created). If the path is left empty, it will be created with the format report-%TIMESTAMP |
| Debug | Select true if you want to see more debug output. |
Step type properties
Each of the step types referred to in the previous section will have a set of properties, such as that shown below for Convert any File to PDF. Each property has a description associated with it, which is displayed when the property is highlighted.
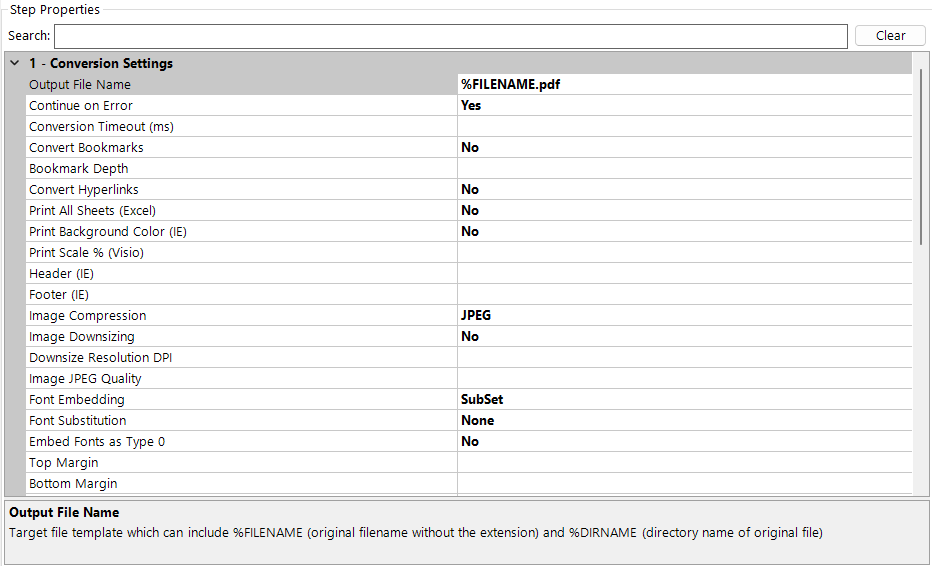
To look for a property, you can use either the scroll bar on the right-hand side or the search bar at the top. The search bar looks for an exact match of the text that you type but will offer suggestions that start with the text you have typed. Selecting a suggestion will jump you to the property and select it for editing.