How to use the OCR server
This guide provides an overview of the OCR API and how to use it. For information on what OCR can do, refer to the OCR overview guide.
API overview
Document Engine enables you to perform OCR using the ocr action in the Build API. This can be either applied directly on upload or used with existing documents.
Running OCR on upload
You can run OCR when uploading your document by providing the OCR action inside the instructions parameter:
curl -X POST http://localhost:5000/api/documents \ -H "Authorization: Token token=<API token>" \ -F instructions='{ "parts": [ { "file": "document" } ], "actions": [ { "type": "ocr", "language": "english" } ]}' \ -F 'document=@/path/to/Example Document.pdf' \ -o result.pdfPOST /api/documents HTTP/1.1Content-Type: multipart/form-data; boundary=customboundaryAuthorization: Token token=<API token>
--customboundaryContent-Disposition: form-data; name="instructions"Content-Type: application/json
{ "parts": [ { "file": "document" } ], "actions": [ { "type": "ocr", "language": "english" } ]}--customboundaryContent-Disposition: form-data; name="document"; filename="Example Document.pdf"Content-Type: application/pdf
<PDF data>--customboundary--Before OCR: Text in the document isn’t searchable or selectable.
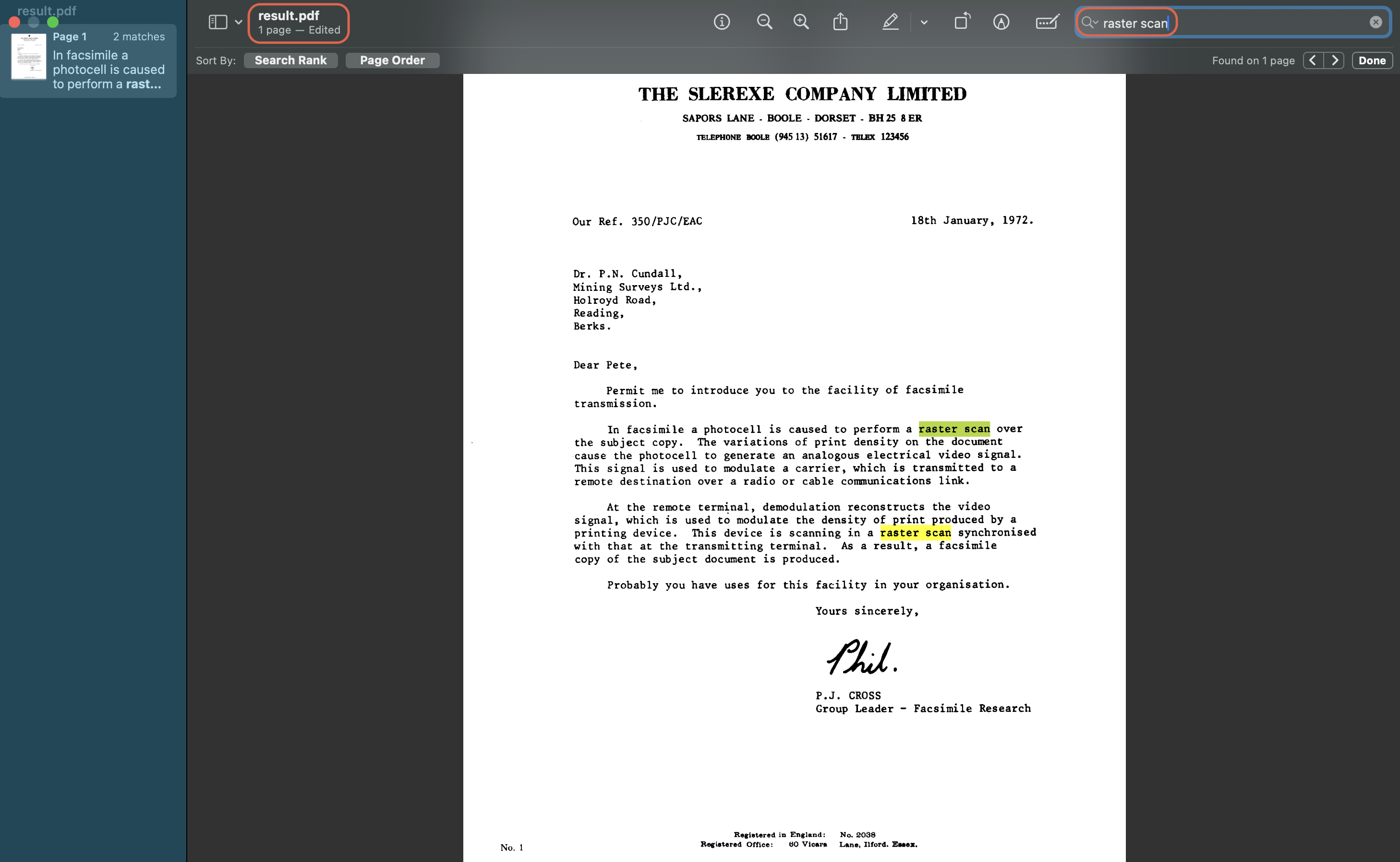
After OCR: Text becomes searchable and selectable.
During your trial period, any document processed using our OCR API will include a watermark on the output. Upon subscribing to our paid plan, you’ll gain the ability to perform OCR on your documents without any watermarks being added to the resulting PDF.
Applying OCR to existing documents and persisting the result
You can also run OCR on documents you’ve already uploaded using the apply_instructions endpoint.
Use the #self anchor to refer to the current document:
curl -X POST http://localhost:5000/api/documents/:document_id/apply_instructions \ -H "Authorization: Token token=<API token>" \ -H "Content-Type: application/json" \ -d '{ "parts": [ { "document": { "id": "#self" } } ], "actions": [ { "type": "ocr", "language": "english" } ]}' \ -o result.pdfPOST /api/documents/:document_id/apply_instructions HTTP/1.1Content-Type: application/jsonAuthorization: Token token=<API token>
{ "parts": [ { "document": { "id": "#self" } } ], "actions": [ { "type": "ocr", "language": "english" } ]}Performing OCR and downloading the result
You can also run OCR as part of the Build API request. This method enables you to upload input documents and retrieve the result without storing anything in Document Engine’s persistent storage:
curl -X POST http://localhost:5000/api/build \ -H "Authorization: Token token=<API token>" \ -F instructions='{ "parts": [ { "file": "document" } ], "actions": [ { "type": "ocr", "language": "english" } ]}' \ -F 'document=@/path/to/Example Document.pdf' \ -o result.pdfPOST /api/build HTTP/1.1Content-Type: multipart/form-data; boundary=customboundaryAuthorization: Token token=<API token>
--customboundaryContent-Disposition: form-data; name="instructions"Content-Type: application/json
{ "parts": [ { "file": "document" } ], "actions": [ { "type": "ocr", "language": "english" } ]}--customboundaryContent-Disposition: form-data; name="document"; filename="Example Document.pdf"Content-Type: application/pdf
<PDF data>--customboundary--Performance considerations
Running OCR is a CPU-bound single-threaded operation. This means performing many parallel OCR operations on a single Document Engine instance can cause a high load for extended periods of time. We did some performance testing using our development hardware (2.4 GHz 8-core Intel Core i9 9980HK, 32 GB RAM, running a single OCR operation at a time), which should give you an idea of what kinds of speed you can expect given your server infrastructure:
- Running OCR on a 6-page document — ~35–40 seconds to run OCR on the entire document, ~6–11 seconds to run OCR on a single page.
- Running OCR on a 1-page document — ~3–4 seconds to run OCR on the page.
Things that affect how fast OCR will be performed:
- The amount of pages in the document.
- The amount of pages OCR will be performed on.
- The content of the pages OCR will be performed on.
- The single-threaded performance of your server hardware.