Generate PDFs from a template using JavaScript
Generating PDFs programmatically is a common requirement in modern web applications. Whether you’re building invoices, reports, or other documents, Nutrient enables you to create PDF documents entirely on the client-side in a browser by merging predefined PDF templates with data. This guide explores key methods, use cases, and best practices to empower your PDF generation workflows.
Methods for creating PDFs in JavaScript
Nutrient Web SDK provides versatile methods for creating PDFs with JavaScript, whether through client-side generation for quick downloads or server-side rendering for high-fidelity output.
Client-side PDF generation
Nutrient Web SDK enables the creation of PDFs directly within the browser, making it a great solution for scenarios where users need instant downloads without server dependencies.
Key features
- Embed text, images, and shapes into PDFs dynamically.
- Works seamlessly in modern web applications.
- Simple to implement for lightweight use cases.
Server-side PDF generation
In the context of backend/server-side workflows, PDF generation typically refers to converting predesigned HTML templates into PDFs. This approach enables the creation of advanced layouts with precise styling, making it ideal for scenarios where high-fidelity output is required. Server-side generation also ensures better control over sensitive data, as the process is handled securely on the server.
Key features
- Converts HTML and CSS templates into pixel-perfect PDFs.
- Ideal for documents requiring accurate styling and complex layouts.
- Enhances security by keeping data processing on the server.
Loading the PDF template
This guide uses our Vanilla JavaScript getting started project as a basis for generating PDFs. Make sure to follow the steps in that guide to set up your project.
First, you’ll need to load the PDF document you wish to populate with the data. Depending on your use case, the document can be loaded in a PDF viewer where a user interface is presented to the user, or headlessly, without a UI.
Load the document in the PDF viewer:
import "./assets/pspdfkit.js";
const baseUrl = `${window.location.protocol}//${window.location.host}/assets/`;
(async () => { try { const instance = await NutrientViewer.load({ baseUrl, document: "/document.pdf", // Path to the PDF document. container: "#pspdfkit" }); } catch (error) { console.error("Failed to load document:", error.message); }})();Load in headless mode so that no UI is presented to the user:
import "./assets/pspdfkit.js";
const baseUrl = `${window.location.protocol}//${window.location.host}/assets/`;
(async () => { try { const instance = await NutrientViewer.load({ baseUrl, document: "/document.pdf", // Path to the PDF document. headless: true }); } catch (error) { console.error("Failed to load document:", error.message); }})();Populating the document with data
To populate the document, you can overlay annotations onto the PDF template. In the following example, you’ll take a JSON data set and overlay TextAnnotations at predefined coordinates:
// data.json
{ "company": "PSPDFKit", "companyInfo": "PSPDFKit", "companyName": "PSPDFKit"}If you look at this guide’s example PDF template, you’ll see placeholders for COMPANY, [Company Info], and Company Ltd.. To detect the position of these placeholders, use the search API:
const searchQuery = "Company Ltd."; // The text to search for.
const bbox = (await instance.search(searchQuery)) .first() .rectsOnPage.get(0);This will show the current position of the text in the document.
Now, create the annotations with the text you want to overlay. For the text property, bring in the data from the JSON file:
// Create a free text annotation.const textAnnotation = new NutrientViewer.Annotations.TextAnnotation({ boundingBox: bbox, // Set the bounding box of the text annotation. fontSize: 8, text: { format: "plain", value: data.companyName }, // The text to overlay. pageIndex: 0, // The page index to overlay the text on. fontColor: NutrientViewer.Color.RED, backgroundColor: NutrientViewer.Color.WHITE});
// Add the annotations to the document.await instance.create(textAnnotation);The backgroundColor property is set to white. This will help create an opaque text annotation to hide the page text underneath.
You can also change the fontSize property; just be aware that you need to adapt the boundingBox size proportionally to the new font size.
The data from the JSON file will now appear in the PDF template as text annotations.
See our guide on programmatically creating annotations for more details.
It’s also possible to overlay other annotation types, such as signatures, images, and stamps.
Flattening annotations
Once the annotations have been overlaid on top of the PDF template, they can optionally be flattened to prevent modification:
await instance.exportPDF({ flatten: true });See our flatten annotations guide for more details.
After flattening the annotations, the PDF template will look like what’s shown below.
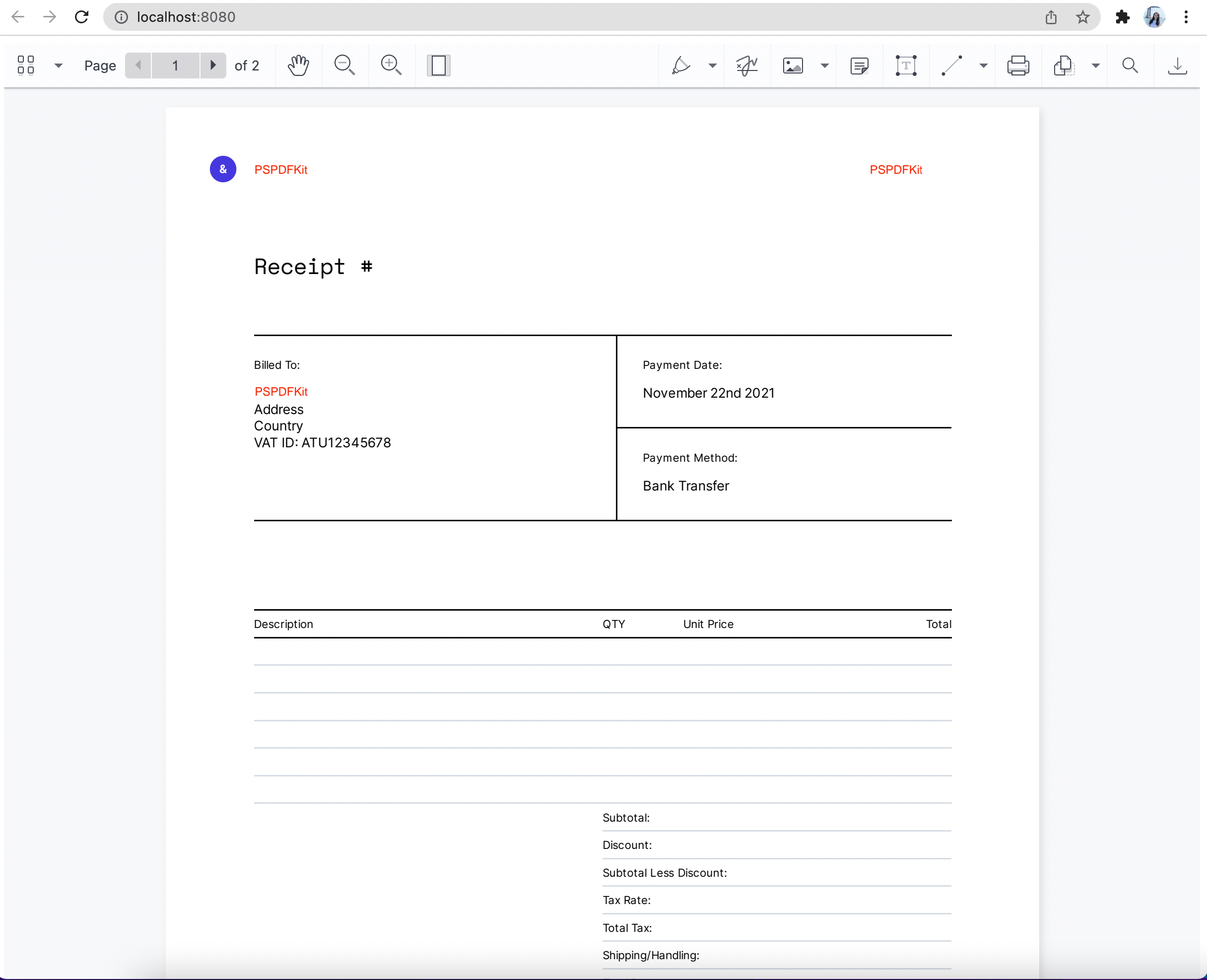
You can find the example PDF template and the code on GitHub(opens in a new tab).
The example demo first loads the document in headless mode and then loads with the UI. This allows you to process the PDF before sending it over the network, or you can use it for light processing, like adding watermarks to the document.
Serving the example project
You can serve the PDF template to the user in a browser. For this, use the serve HTTP package.
Install the serve package:
Terminal window npm install --global serveServe the contents of the current directory:
Terminal window serve -l 8080 .Navigate to http://localhost:8080 to view the website.
Using annotations
Another way to do this is via annotations instead of using page text placeholders. (The example above tried to find the position of placeholders and updated it with dynamic data.) Use text annotations with predefined visuals (font, size, color, etc.) but with a replacement string. Here, you’ll retrieve all annotations on the page, iterate through all text annotations, and update them if they have the placeholder text.
For example, you could have the following text annotation as part of the template.

Then, you can perform the token replacement via the following:
const replacements = { "[[Company]]": "PSPDFKit"};
const annotationsToUpdate = // Retrieve annotations for a page. (await instance.getAnnotations(0)) // Filter to text annotations. .filter((it) => it instanceof NutrientViewer.Annotations.TextAnnotation) // Replace annotations with text that matches any replacement token. .map((annotation) => replacements[annotation.text.value] ? annotation.set("text", { format: annotation.text.format, value: replacements[annotation.text.value] }) : annotation );
// Annotations are immutable. `annotationsToUpdate` contains new instances of annotations. You need to use `instance.update` to actually update them.await instance.update(annotationsToUpdate);This will replace the [Company] annotation with PSPDFKit.

Saving the PDF document
See our guide for saving a document.
You can also check out this blog post to learn more.
Best practices for PDF generation in JavaScript
When creating PDFs in JavaScript, follow these guidelines to ensure optimal results. Note that some practices, such as creating annotations or advanced features, apply specifically to backend HTML-to-PDF conversion and may not be achievable in client-side generation workflows.
- Optimize performance
- Use compression options to reduce file size.
- Minimize the size of embedded assets like images or fonts.
- Ensure accessibility
- Include proper metadata for screen readers.
- Add alternative text for any images embedded in the PDF.
- Security considerations
- Avoid embedding sensitive information in client-side PDFs.
- Use server-side generation for documents with critical data.
- Leverage modular code
- Separate your logic for data processing and PDF generation.
- Use reusable templates for consistent styling and formatting.
Conclusion
By leveraging Nutrient Web SDK’s robust capabilities for PDF creation, you can simplify workflows and enhance user experiences. Whether generating documents dynamically on the client-side or creating complex templates on the server, our SDK provides the flexibility and power needed to efficiently create high-quality PDFs.
FAQ
Nutrient Web SDK is a versatile tool for PDF generation due to its ability to integrate directly into web applications. It supports both client-side and server-side methods, enabling developers to meet diverse requirements, whether they involve creating simple forms or highly customized, data-driven documents.
You can generate PDFs using JavaScript with Nutrient by integrating the library into your project and loading a PDF template. You can then populate the template with data either by overlaying text annotations or by using predefined placeholders. The generated PDFs can be rendered directly in the browser.
Nutrient allows for client-side PDF generation and manipulation. It supports various features, making it suitable for dynamic and customizable document creation.
You can load a PDF template into Nutrient by specifying the document path in the configuration options. You can load the document with or without a user interface, depending on whether you want to present the PDF to the user or process it headlessly.
To populate a PDF template with data, you can use Nutrient’s annotation features to overlay text or other elements at predefined coordinates. You can search for placeholder text in the document and then use this information to position annotations accordingly.
Yes, you can flatten annotations after adding them to a PDF template using Nutrient. Flattening annotations will make them a permanent part of the PDF, preventing further modifications.
The recommended approach for replacing placeholders in PDF annotations is to retrieve all annotations on the page, filter for text annotations, and then update them based on replacement tokens. This method allows you to dynamically update text annotations with new data.
Nutrient Web SDK offers significant advantages over libraries like jsPDF, pdf-lib, and Puppeteer by simplifying PDF generation with a template-first approach, enabling developers to design PDFs visually and populate them dynamically without extensive coding. Unlike jsPDF and pdf-lib, which require manual element creation, or Puppeteer, which is resource-intensive and harder to scale, Nutrient provides a lightweight, scalable solution for both client-side and server-side use. With its ease of use and cross-platform compatibility, Nutrient is ideal for creating professional, dynamic PDFs in modern applications.
JavaScript PDF generation, particularly through backend HTML-to-PDF conversion, is widely used to automate document creation in various applications. One common use case is dynamic invoice generation, where user-specific data is rendered into HTML templates to produce professional, accurate invoices. Another is automated report creation, enabling the dynamic production of reports based on user inputs or analytics data, often integrated into dashboards or data visualization tools. Additionally, event ticketing leverages backend HTML-to-PDF workflows to automate the creation of e-tickets, incorporating dynamic elements like QR codes, barcodes, and personalized seating details. These advanced use cases aren’t easily achievable with client-side-only solutions due to the complexity of rendering precise layouts and handling sensitive data.