Optimize document searchability with auditing and OCR
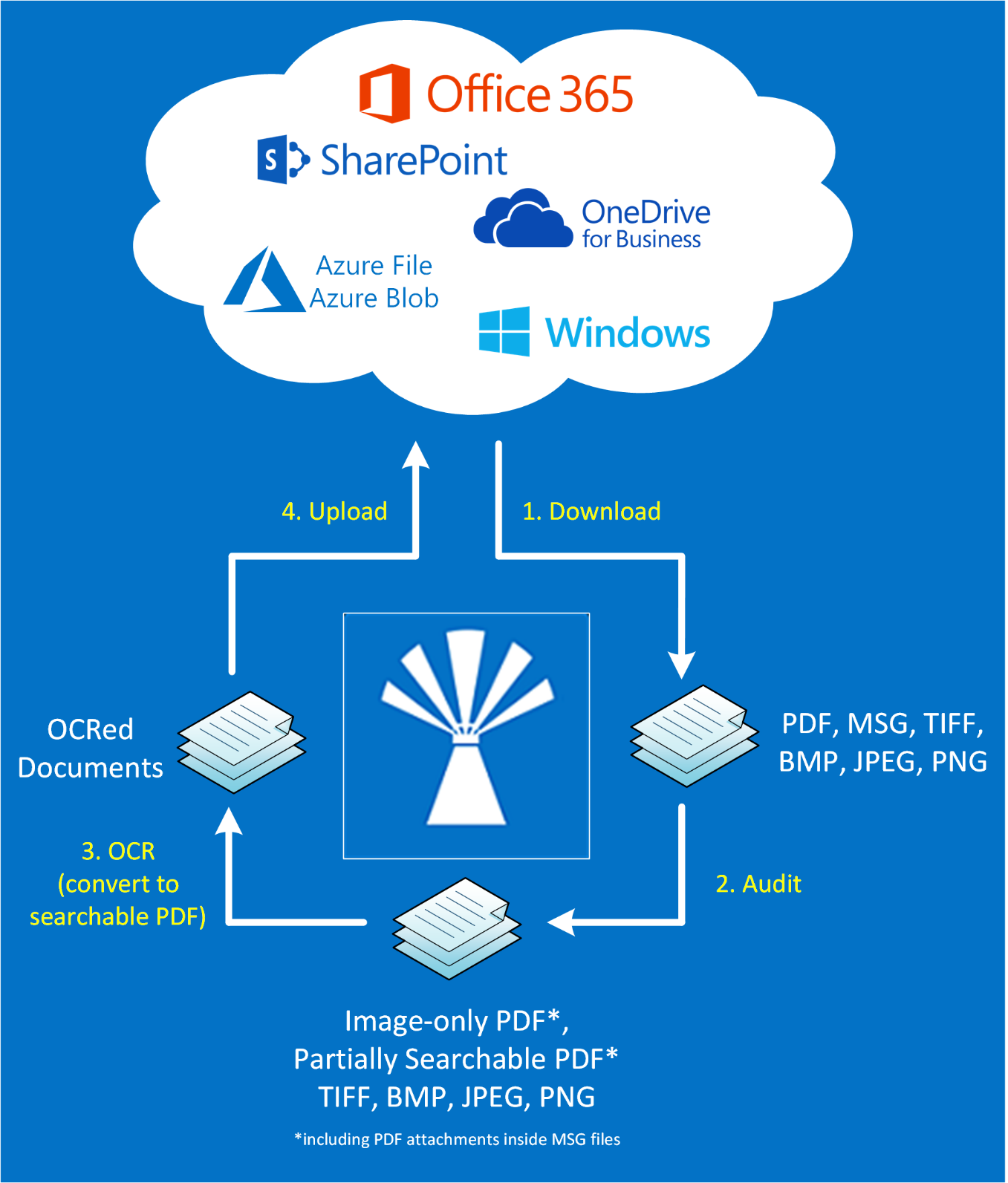
There are 2 main stages when processing a Document Searchability library: the Audit stage, and the OCR stage.
At its most basic level, Document Searchability will:
Audit Stage
1.1. Download (SharePoint or Azure hosted locations) or copy (Windows file system locations) to a temporary local location.
1.2. Analyse (Audit) the files to identify whether they need to be OCR’d.
1.3. Record the results of the audit in the database.
OCR stage
2.1. If the file needs to be OCR’d then OCR it.
2.2. If the file has been OCR’d then replace the existing document (optionally restoring original file meta data and archiving the original)
2.3. Record the results of the OCR in the database.
Audits can be undertaken without the OCR stage to determine how many of your files are not currently searchable and allow you to determine the optimum way of fragmenting your libraries.
Audit (and OCR) results are recorded in a database which means that files which are unchanged do not need to be analyzed again, speeding up subsequent processing.
See the following blog(opens in a new tab) for a more detailed explanation.
Supported Formats
Document Searchability currently supports TIFF, BMP, JPG, PNG and PDF documents (including PDF attachments inside MSG files) as input. As a result, candidate documents will always be one of these formats.
Document Searchability Libraries
Document Searchability revolves around the concepts of libraries. A Document Searchability library can be described as a job in Document Searchability that has all the settings required to process documents from specific Document Management Systems. It will usually consist of the following:
- The location(s) containing the documents that need to be processed.
- Document selection settings to indicate what types of documents to process (TIFF, PDF, etc.)
- OCR settings to use during the OCR phase.
All Document Searchability libraries are displayed in the Dashboard as shown below and the various settings associated with one can be accessed by double-clicking on it.
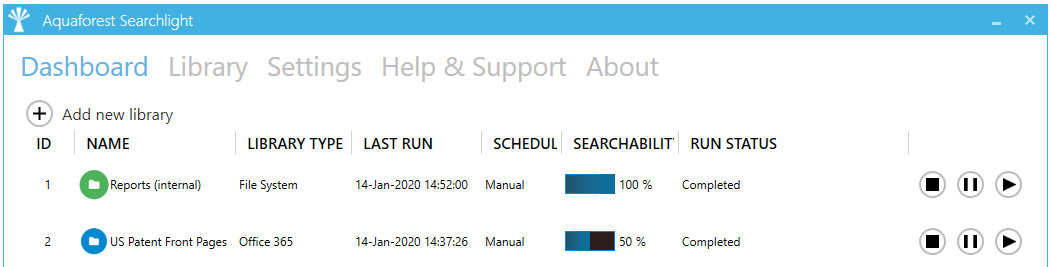
A Document Searchability library should not be confused with a SharePoint document library, which is a document library in SharePoint. See this blog for a more detailed explanation.
Searchability Status
The searchability status of a document describes how indexable the document is. It is classified in the following 3 categories:
Fully Searchable
A PDF document is fully searchable if all its pages have text that can indexed and searched.
Partially Searchable
A partially searchable document contains some pages with text, others with only images or no images and no text (blank)
Image-only
This is a PDF that has been created from one or more images – most commonly because of scanning a document either directly to PDF or by converting a scanned TIFF image to PDF. These files do not contain any searchable text and most often comprise a set of Group4 or JBIG2 images in a PDF “wrapper”.
Image documents (TIFF, BMP, JPG and PNG) are always identified as image-only.
Audit and Candidate Identification
Before processing a document library, Document Searchability will perform an Audit (analysis) on the document library to determine which documents are candidates for processing by examining each document’s searchability status and comparing it with the document selection settings in the Library > Document Settings tab.
Document Stores Concepts
SharePoint and Office 365 Document Stores Concepts
Document Searchability can be configured to monitor multiple SharePoint libraries. Below are some concepts that should be taken into consideration during configuration.
File and path lengths
The file path is everything after the server’s name and port number in the URL. File path includes the name of the site and subsites, document library, folders, and the file name itself.
| SharePoint Type | Maximum file path Length | Maximum file or folder name length |
|---|---|---|
| SharePoint Online (Office 365) | 400 | 400 |
| SharePoint On-Premises 2019 | 400 | 400 |
| SharePoint On-Premises 2016 | 256 | 128 |
| SharePoint On-Premises 2013 | 256 | 128 |
| SharePoint On-Premises 2010 | 256 | 128 |
Versioning
Since Document Searchability uses in-place processing, the source document is replaced by the resulting PDF file. However, if versioning is turned on, the resulting PDF file will be created as another version of the input file in SharePoint. If versioning is turned off, then the resulting PDF file replaces the source file.
URL formats
Below are examples of SharePoint URL formats accepted by Document Searchability when setting up a document library. NOTE: Make sure the URLs start with “http” or “https”
Example formats
Site/Web:
- https://myCompany(opens in a new tab)
- https://myCompany/sites/mySite(opens in a new tab)
- https://myCompany/sites/mySite/mySubSite(opens in a new tab)
Document Library:
- https://myCompany/myLibrary(opens in a new tab)
- https://myCompany/sites/mySite/myLibrary(opens in a new tab)
- https://myCompany/sites/mySite/mySubSite/myLibrary(opens in a new tab)
List:
- https://myCompany/Lists/myList(opens in a new tab)
- https://myCompany/sites/mySite/Lists/myList(opens in a new tab)
OneDrive for Business
- https://myCompany-my.sharepoint.com/personal/firstname_lastname_mycompany_onmicrosoft_com(opens in a new tab)
- https://myCompany-my.sharepoint.com/personal/firstname_lastname_mycompany_onmicrosoft_com/myLibrary(opens in a new tab)
However, if the full URL is entered (i.e., ending with “.aspx”) as shown below, Document Searchability will try to automatically format it to one of the above accepted formats:
- https://myCompany/sites/mySite/SitePages/Home.aspx(opens in a new tab)
- https://myCompany/sites/mySite/myLibrary/Forms/AllItems.aspx(opens in a new tab)
- https://myCompany/sites/mySite/_layouts/15/start.aspx#/myLibrary/Forms/AllItems.aspx(opens in a new tab)
- https://myCompany/sites/mySite/Lists/myList/AllItems.aspx(opens in a new tab)
- https://myCompany/sites/mySite/_layouts/15/start.aspx#/Lists/myList/AllItems.aspx(opens in a new tab)
- https://myCompany-my.sharepoint.com/personal/firstname_lastname_mycompany _onmicrosoft_com/_layouts/15/onedrive.aspx(opens in a new tab)
- https://myCompany-my.sharepoint.com/personal/firstname_lastname_mycompany_onmicrosoft_com/myLibrary/Forms/AllItems.aspx(opens in a new tab)
Windows File System Stores Concepts
File and path lengths
Windows File System Standard Windows File System
The maximum length of a path is 260 characters (D:\some 256-character path string<NUL>).
Windows File System (Unicode)
The Windows API has many functions that also have Unicode versions to permit an extended-length path for a maximum total path length of 32,767 characters.
This type of path is composed of components separated by backslashes, each up 255 characters.
To specify an extended-length path, use the ”?\ prefix. For example, ”?\D:\very long path”.
Windows File System (long path)
Starting in Windows 10 version 1607 it is possible to opt out of the MAX_PATH limitations in common Win32 file and directory functions.
File Access Permissions
Document Searchability Service must be configured with the security credentials of a user that has permissions to access that specific location.
Azure File Storage Stores Concepts
The entire path, including the file name, must contain fewer than 2,048 characters.
The path is composed of components separated by backslashes (for example \A\B\C\D, each letter is a component), each component can be up to 255 characters in length.
Azure Blob Storage Stores Concepts
Blob storage is a flat storage scheme. Within one container, each blob name identifies a blob. It is possible to simulate a folder structure using delimiters within the blob name.
Blobs are identified by both a container name and a blob name.
Container names are between 3 and 63 characters in length.
A blob name must be at least one character long and cannot be more than 1,024 characters long.
Mixed Storage Types
Though it is possible within a Document Searchability library to use one document store type as the source, and another document store type for both Archive location, and for files generating errors, there will be issues due to differences in file path lengths and characters acceptable in file paths.
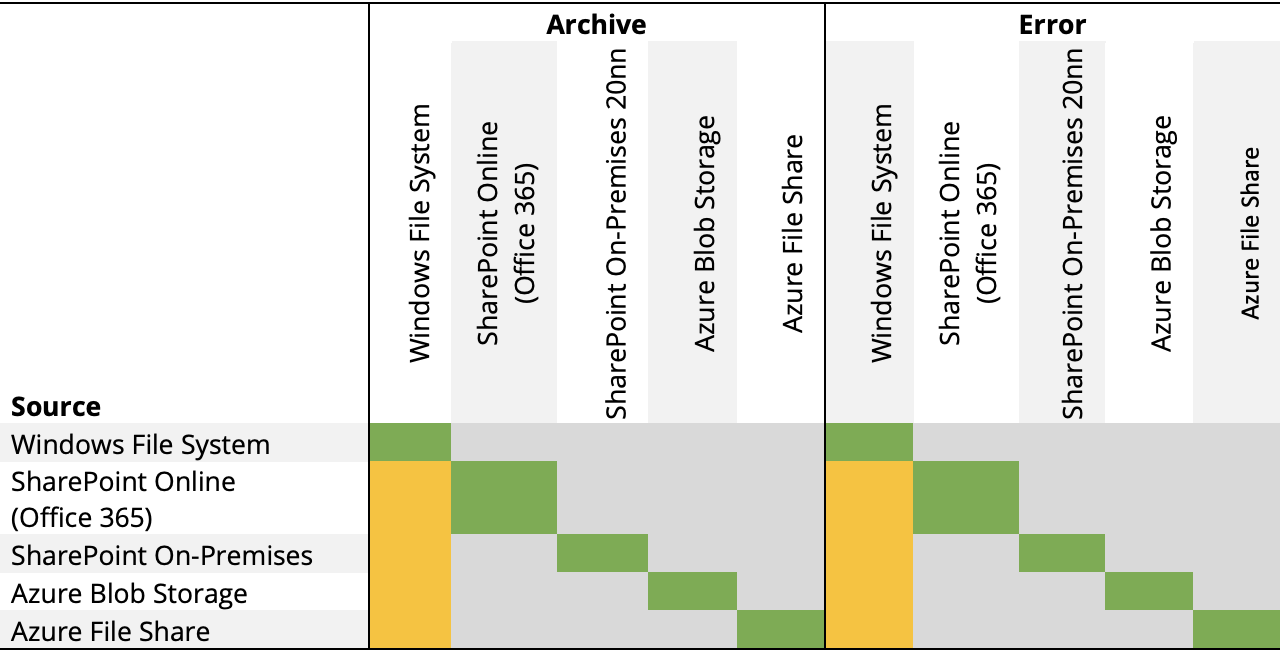
For general use, it is recommended that a Document Searchability Library uses the same type of storage for all locations.
Use of Windows File System for Archive and Error locations has been tested, but there are issues with respect to path lengths and accepted characters as noted above.
Archiving
To avoid making inadvertent changes to the source document, it is recommended to turn Archiving on to maintain a backup of the source documents.
If Archiving is turned on, a copy of the file is created in a user specified archive location before any processing takes place. There is an option to retain the folder structure in the archive location.
Document Searchability Service
This is the heart of the product and controls the execution of all libraries. Without it running, a library cannot be audited or OCRed. It is also used by the scheduler to automate the processing of libraries at regular time intervals without interfering with other work being performed on the machine it is installed in. It is also used to generate scheduled reports and sending email alerts.
The service can be turned on or off by going to Settings > Advanced tab.
The Service Status is displayed at the bottom left of all tabs.