Automate document tagging for better searchability
Version 1. 2
April 2022
Nutrient Document Searchability Tagging is a tool that further enhances findability and classification of documents in SharePoint by automatically generating and tagging metadata based on the contents of the documents via rules, taxonomies, barcodes, PDF forms, XMP and integration with NLP services.
The business problem: Drowning in data, thirsting for information
According to a survey published in Well-known findability challenges in the AI-hype (2019) on Findwise(opens in a new tab), 55% of respondents struggled to find information within their organizations, highlighting stagnation in improvements over several years. The obstacles include lack of resources, poor information quality, and insufficient metadata management.
With the rise of AI and machine learning, organizations now face additional challenges in managing vast amounts of structured and unstructured data. The need for solutions that ensure data is findable, accessible, interoperable, and reusable (aligned with the FAIR principles) has grown. Modern enterprise search tools incorporating AI and Natural Language Processing (NLP) are being adopted to address these issues.
With the ever-increasing growth of data being stored to document stores such as Microsoft SharePoint and the increased expectations of good findability, there is a need for a solution to automatically enrich the (raw) data by extracting valuable information from them, which can then be used to enhance findability – a critical need for business success.
The extracted information can be added as metadata (also known as tagging) to the documents in SharePoint. Metadata is key to improve findability and retrieve accurate and relevant information in SharePoint. Documents stored in SharePoint may often be lacking key metadata required to enable straightforward metadata searches. As a result, when a query is performed, all documents containing the search term are returned, with no possibility of further refining the search results.
Tagging documents with good metadata improves their ranking in search results by prioritising query matches against the metadata (as compared to matches against the text within the documents), thus providing more relevant results. Moreover, the results can be further refined through faceted navigation by incrementally applying multiple filters on various additional metadata to get the correct document/information.
A significant reliance on manual tagging persists across organizations, especially for nuanced or complex data. However, manual efforts are often inconsistent and subjective, leading to poor metadata quality and inefficiencies(opens in a new tab).
Satisfaction with tagging accuracy remains low due to the time-consuming and subjective nature of manual tagging. Inconsistencies in metadata(opens in a new tab) severely impact data discoverability and quality, affecting business operations negatively.
Consequently, all things considered, automated tagging is the likely practical solution. Automatically generated metadata can be complemented by manual inspections and corrections to improve consistency, accuracy, speed and cost of metadata tagging.
The solution: Nutrient Document Searchability Tagging
Nutrient Document Searchability Tagging is a tool that can be configured to automatically extract and/or generate metadata from new and existing documents in SharePoint and tag them accordingly to further enhance findability and classification. It is a stand-alone client application and can be installed on any computer that can connect to the SharePoint server.
Architecture
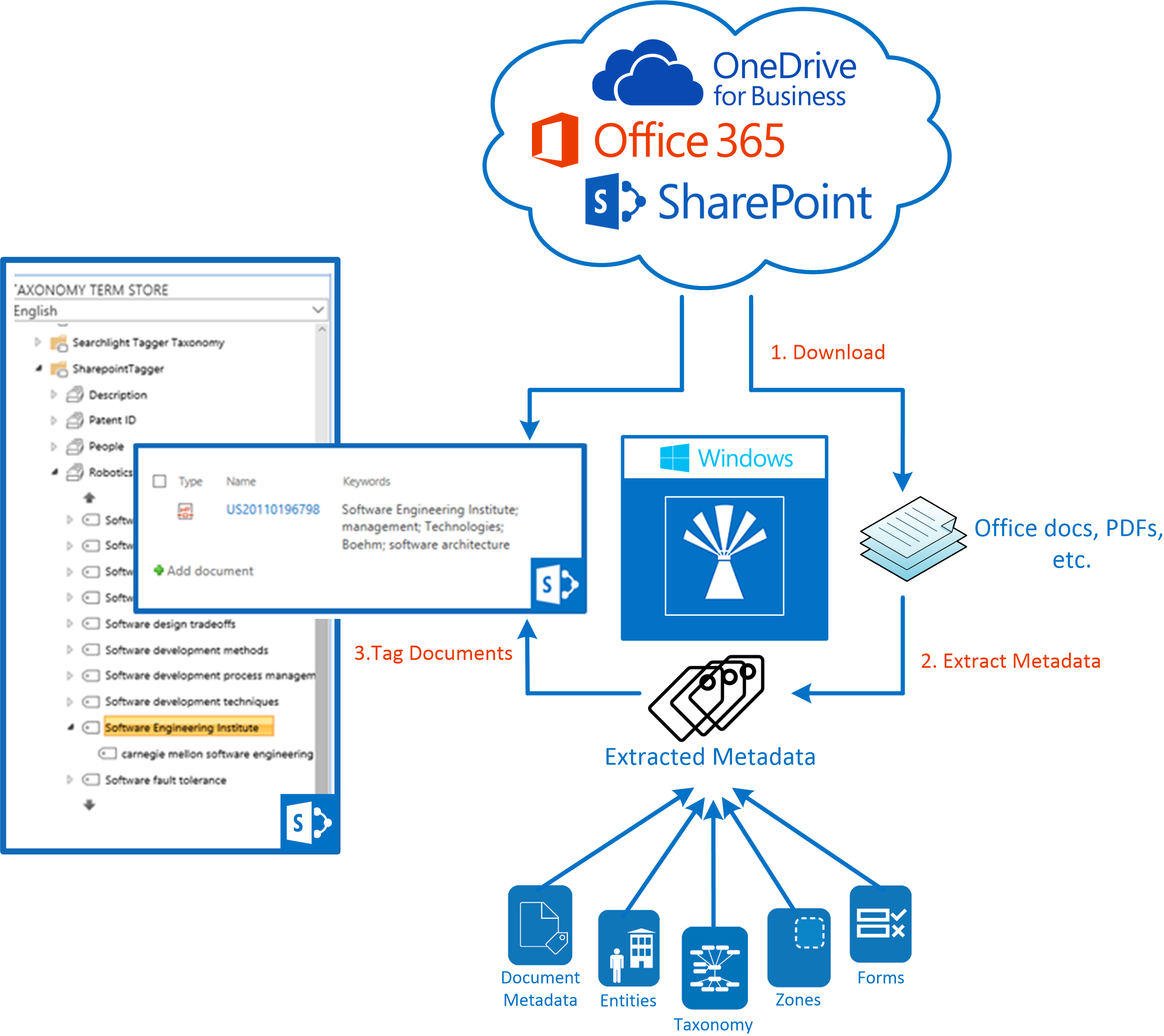
In a nutshell, Document Searchability Tagging works in 3 main steps:
- Documents are downloaded from SharePoint to the temporary location defined in Tagging.
- Metadata are extracted or generated from the documents based on the extraction type(s) selected and metadata chosen to be extracted. The extraction types are described in the sections below.
- The documents are then tagged with the extracted metadata from the previous step. If necessary the metadata are added to the Term Store if they are not already present.
The downloaded documents are deleted after processing.
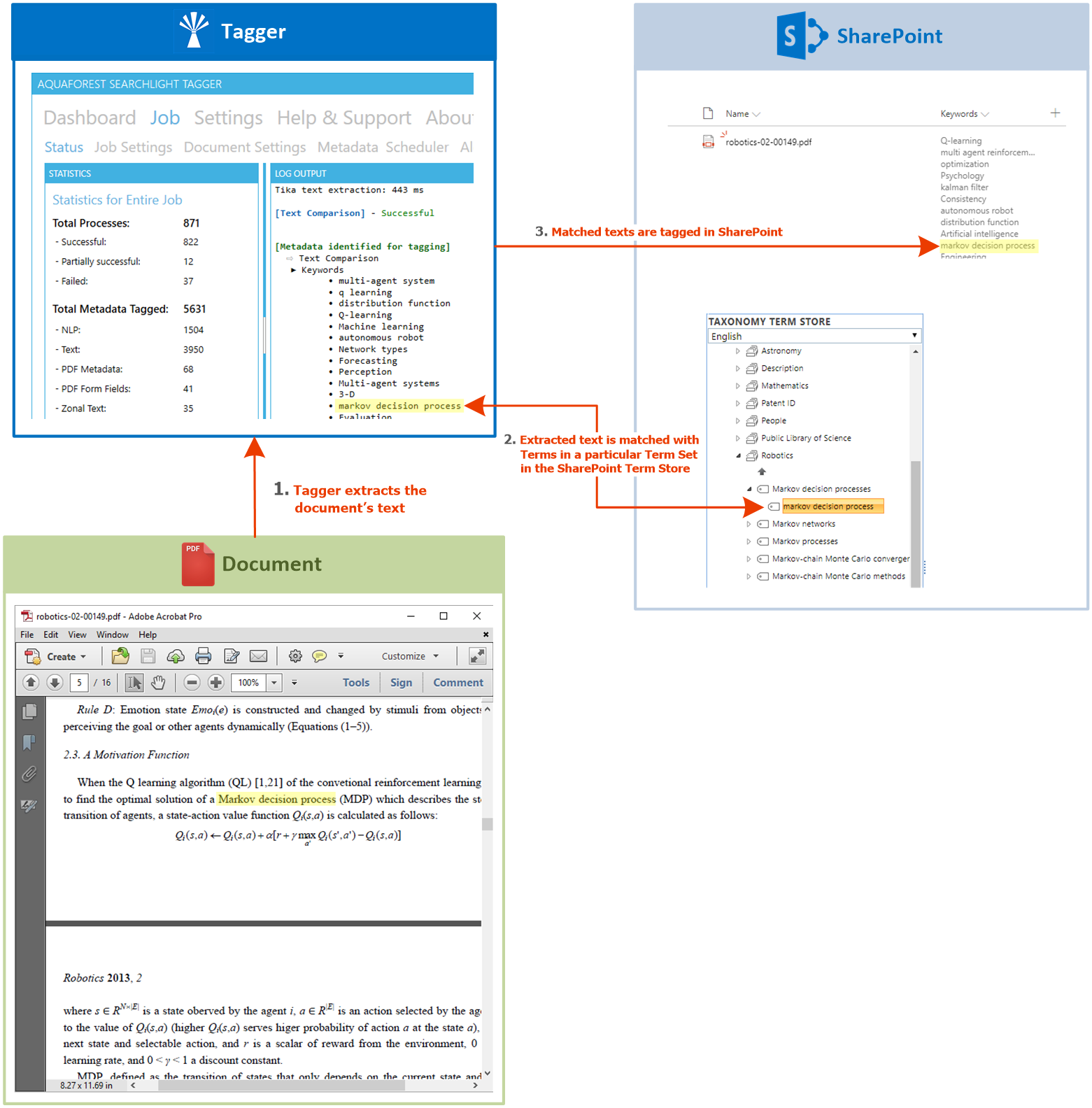
Taxonomy matching
Document Searchability supports the use of managed metadata and taxonomies for both identifying taxonomy(opens in a new tab) values that should be used to tag the document and is also able to add new taxonomy values if required. Text is extracted from the documents and compared with terms in the Taxonomy Term Store to see if any terms appears in the Text. Only the Terms in the Term Set defined for the selected SharePoint column are compared.
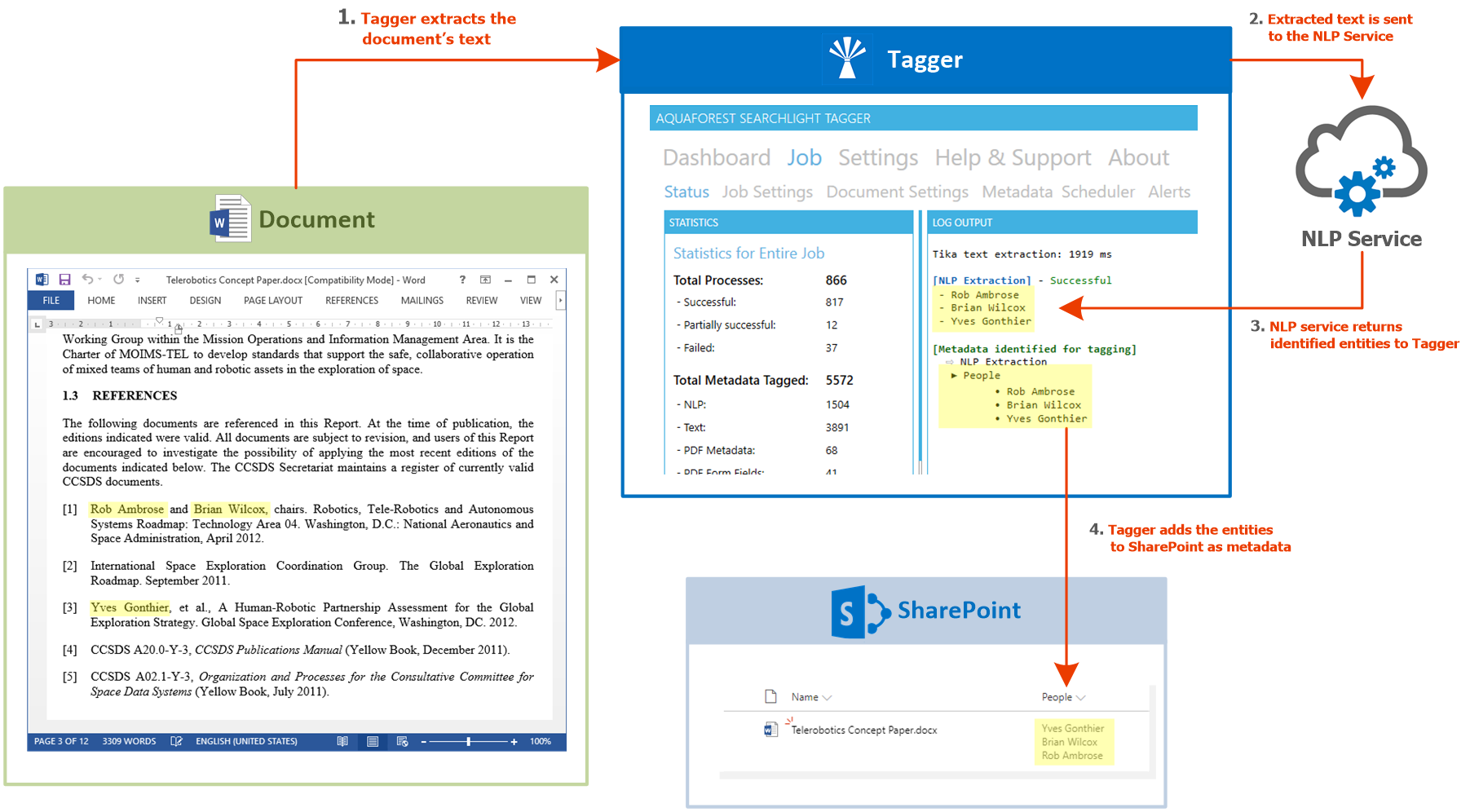
Entity extraction
By integrating with NLP (Natural Language Processing) services, it is able to assign values for Entities such as Location, Person, Company and more. Text is extracted from the documents and passed to the NLP service defined in Tagging. The NLP service will then analyse the text and automatically identify or generate entities to be used as metadata. Entity Extraction is explained in more detail in section 5.1.
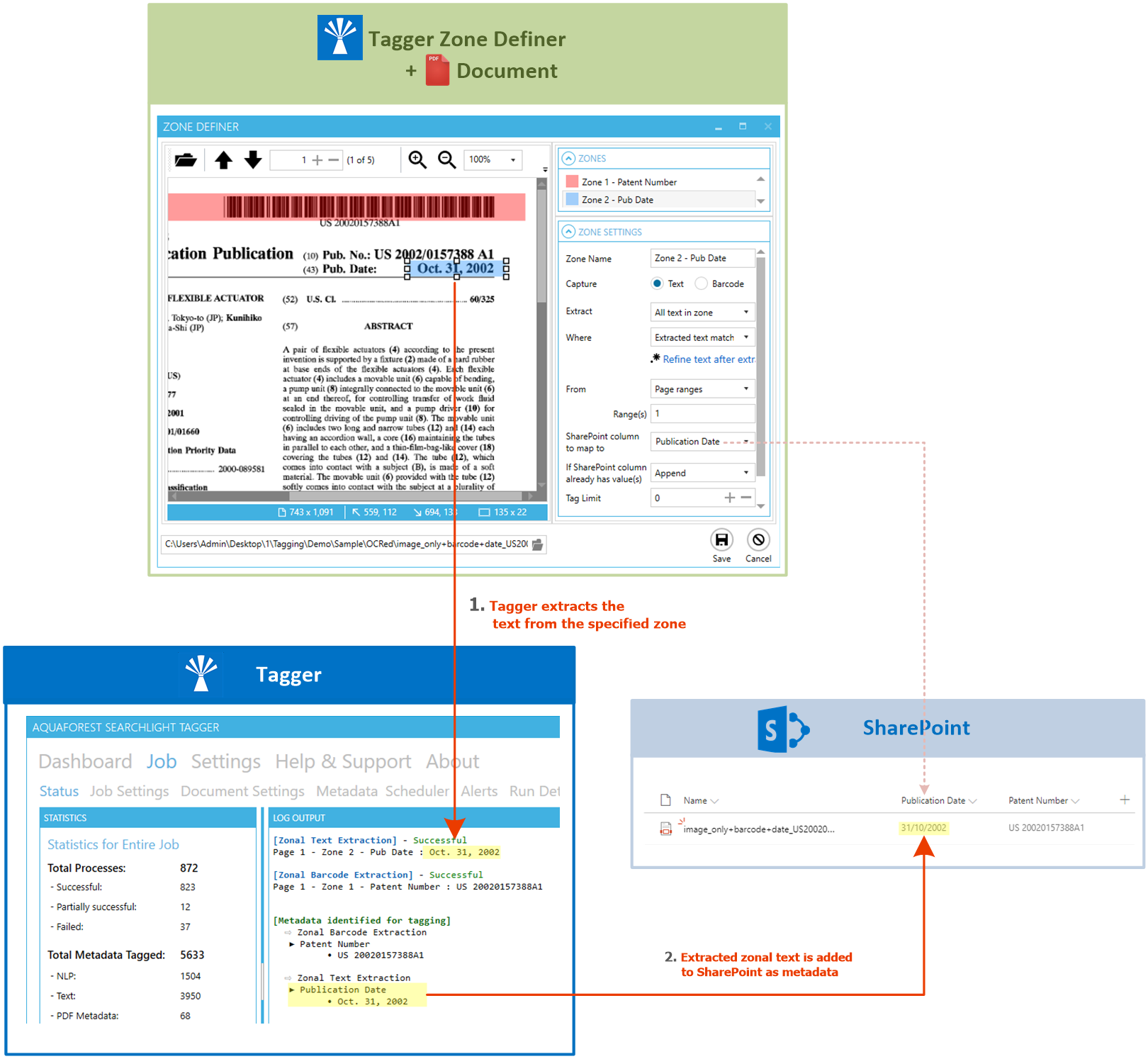
Zonal extraction
It enables zonal extraction of text and barcodes from PDF documents. Over 20 types of barcode can be recognized and the values assigned to Library metadata columns.
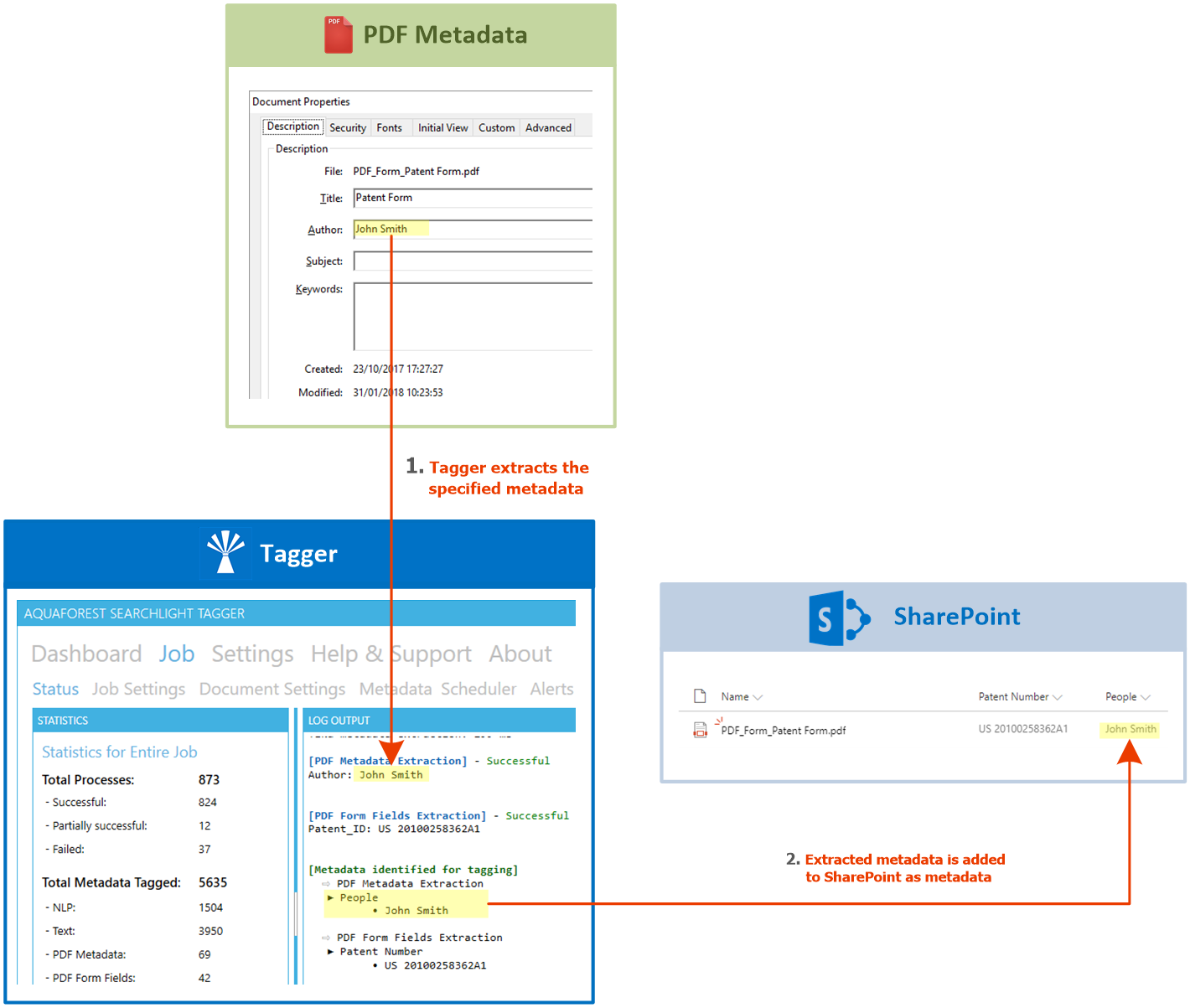
Document metadata
Both standard and custom PDF metadata can be extracted and assigned to SharePoint columns. This can also include XMP metadata.
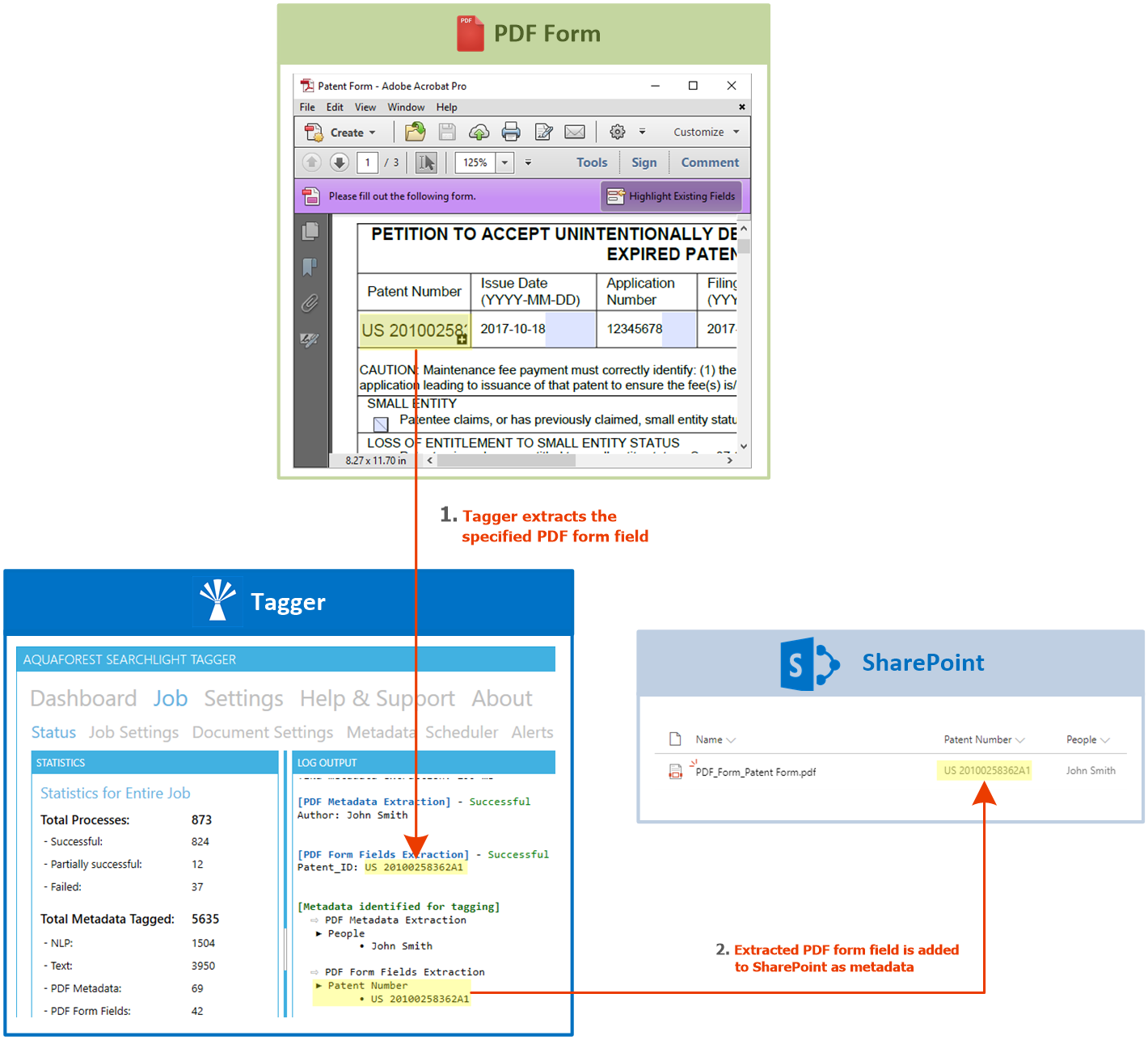
PDF forms
Data from PDF forms can be extracted and each field value assigned to a separate SharePoint column.