Understanding tokenization for effective tagging
Tokenization is the process of breaking text into individual words, phrases, symbols, etc. called tokens (or segments).
In Tagging, tokenization can be used for Taxonomy Matching and it is controlled by Text Pre-processing Settings under the Job > Metadata > Taxonomy Matching Settings tab.
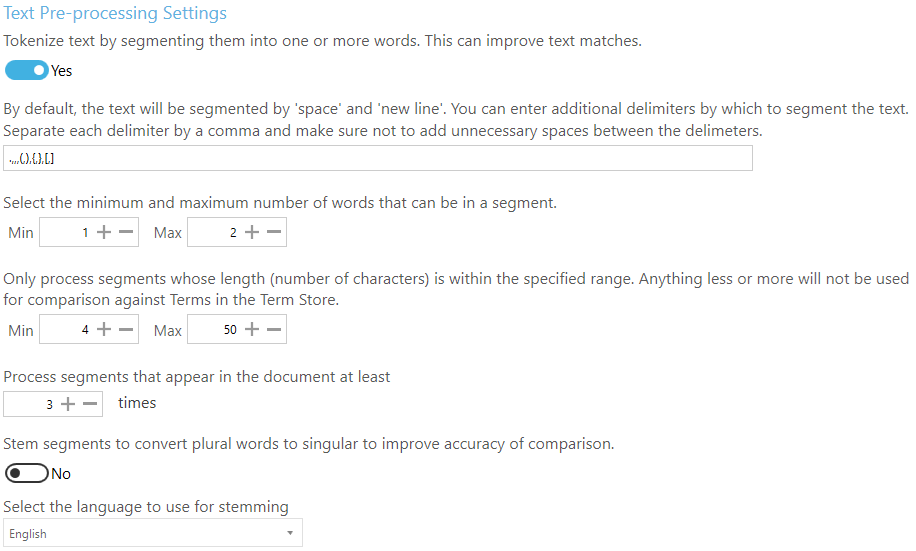
By default, Tagging will tokenize text using the space and new line characters but you can specify additional delimiters to use to tokenize text. When you create a new job, Tagging will have default additional delimiters as shown below.
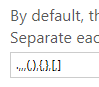
The delimiters (shown below in green) must be separated by a comma:
.,,,(,),{,},[,]
You can add or remove delimiters from the default values. Just make sure to avoid having unnecessary spaces between the delimiters.
Let us look at an example of how tokenization works in Tagging. Say we had the following text (adapted from “The Everlasting Story of Nory” by “Nicholson Baker”):
| Nory was an ice cream vendor because her mother was an ice cream vendor, and Nory’s mother was an ice cream vendor because her father was an ice cream vendor, and her father was an ice cream vendor because his mother was an ice cream vendor, or had been. |
|---|
Based on the following Tagging settings,

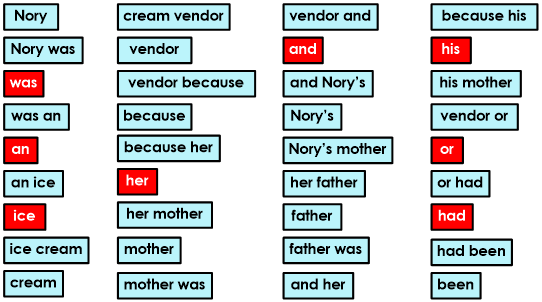
Tagging will tokenize the sentence as follows.

Each ‘box’ is a token/segment. For this particular sentence, the tokens were generated after splitting it with space, comma and full stop delimiters because these are the only delimiters present in the sentence. Note how the delimiters are not part of the tokens.
With only these two Tagging settings, each of the tokens above will be compared to Terms in the SharePoint Term Store. However, this is not very efficient since there are quite a few duplicate tokens. Moreover, if the Term Set(s) being compared had the word “ice cream”, the above sentence would not return a match because “ice” and “cream” are two separate tokens.
To deal with this Tagging has the following setting, which allows combining tokens together.

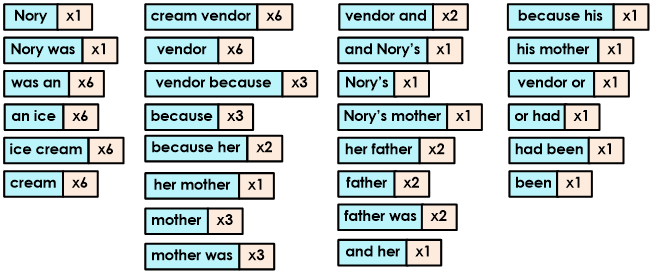
Using the above settings, Tagging will combine up to two tokens together resulting in the following:
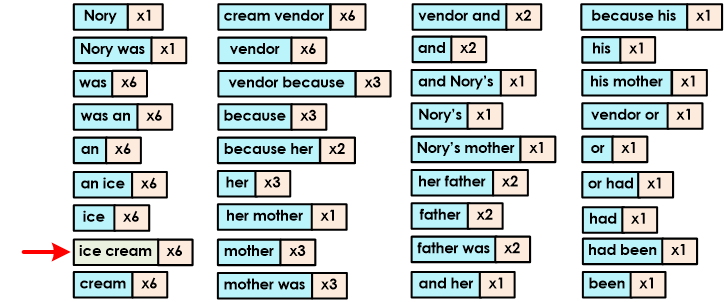
You will also notice that duplicate tokens have been grouped together to avoid comparing the same tokens multiple times.
The comparison process can be further optimized by excluding tokens of certain lengths to improve efficiency and effectiveness. This can be useful to remove common less pertinent words (or stop words) such as “a”, “or”, “to”, etc. The following settings control this:

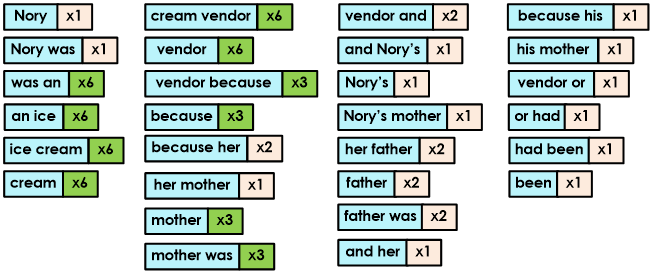
Using the above settings, only tokens whose length is between 4 and 50 characters will be used for comparison. Consequently, the tokens shown in red below will be excluded because they are less than four characters.
In order to improve the accuracy and validity of terms tagged, we can tell Tagging to compare only those tokens that appear at least a minimum number of times.
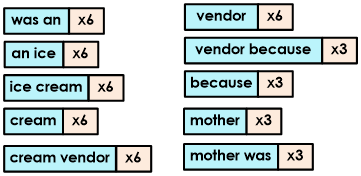
Below are the remaining tokens and the frequency of their appearance in the sentence.
Using the following setting, we can tell Tagging to only compare tokens that appear at least 3 times (in the document).

Consequently, only the following tokens will be compared against Terms in the Term Store:
Using all the settings described above, Tagging can efficiently and accurately match text from documents to Terms in Term Store.
Stemming
Stemming is the process of reducing words to their root form. Most languages have inflected version(opens in a new tab) of words to express different grammatical categories such as number, tense, gender, mood, etc.
Example:
| Root form | Inflected form(s) |
|---|---|
| Child | Children |
| Play | Playing, Played |
| Engineer | Engineers, Engineered, Engineering |
If the SharePoint Term Store has the root form of a word as a Term (e.g. Engineer), and a document has the inflected form of the word (e.g. Engineers), it will not match and therefore will not be tagged. Using stemming, Tagging will attempt to convert the inflected form in the document to its root form, which will match, thus improving comparison accuracy.
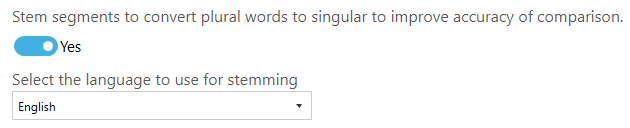
To use stemming in Tagging, enable it and set the language to use for stemming based on the language of the documents being processed because different languages have different stemming rules.