




Boosting Healthcare Efficiency through OCR Records Digitization
Table of contents

In the healthcare industry, the efficient digitization of patient records is crucial for providing timely and accurate care. This user guide focuses on leveraging the Aquaforest PDF Connector for Power Automate, specifically utilizing the “OCR PDF or Images” action. This action empowers healthcare professionals to enhance efficiency by digitizing patient records and making them searchable through OCR technology.
Challenges without OCR Records Digitization
Manual Information Retrieval:
- Without OCR, healthcare professionals rely on manual methods to retrieve information from paper-based records, leading to time-consuming and error-prone processes.
Limited Accessibility:
- Paper-dependent records limit accessibility, making it challenging for multiple healthcare professionals to access and collaborate on patient information simultaneously.
Data Silos and Inefficiencies:
- Lack of OCR results in data silos, where patient information is stored in non-searchable formats, leading to inefficiencies in information sharing and retrieval.
Benefits of OCR Records Digitization
- Improved Accessibility: Digitizing patient records through OCR enhances accessibility, allowing healthcare professionals to quickly retrieve and review relevant information.
- Searchable Documents: OCR transforms scanned documents into searchable formats, enabling healthcare providers to efficiently search for specific patient data within records.
- Efficient Data Extraction: By extracting text from images, OCR contributes to efficient data extraction from medical charts, prescriptions, and other healthcare documents.
- Reduced Paper Dependency: Digitizing patient records reduces reliance on paper documents, leading to a more eco-friendly and streamlined healthcare environment.
How to Digitize Patient Records with OCR using Power Automate
Follow these step-by-step instructions to implement the “OCR PDF or images” action for healthcare records digitization:
Step 1. Configure Aquaforest PDF Connector.
Add the Aquaforest PDF Connector to your Power Automate workflow. First you choose the type of the flow and the trigger.
For this example, we will choose the “Automated cloud flow” and set a trigger “When a file is created (properties only)”. This trigger is activated when an item is created, or modified in a library. As it returns only the properties stored in the library columns you need to add a “Get file content” step and use the “Identifier” property returned by this action to get to the contents of the file.
Click on the + button to add a new action, and in the search bar type “OCR PDF or images” action.
As a next step, you will be asked for a Connection Name and an API Key. Give your connection a name and use the primary key generated upon signing up for PDF Connector(opens in a new tab). If you need assistance, read the getting started guide, particularly Generate API key section.
Step 2. Provide Input Parameters.
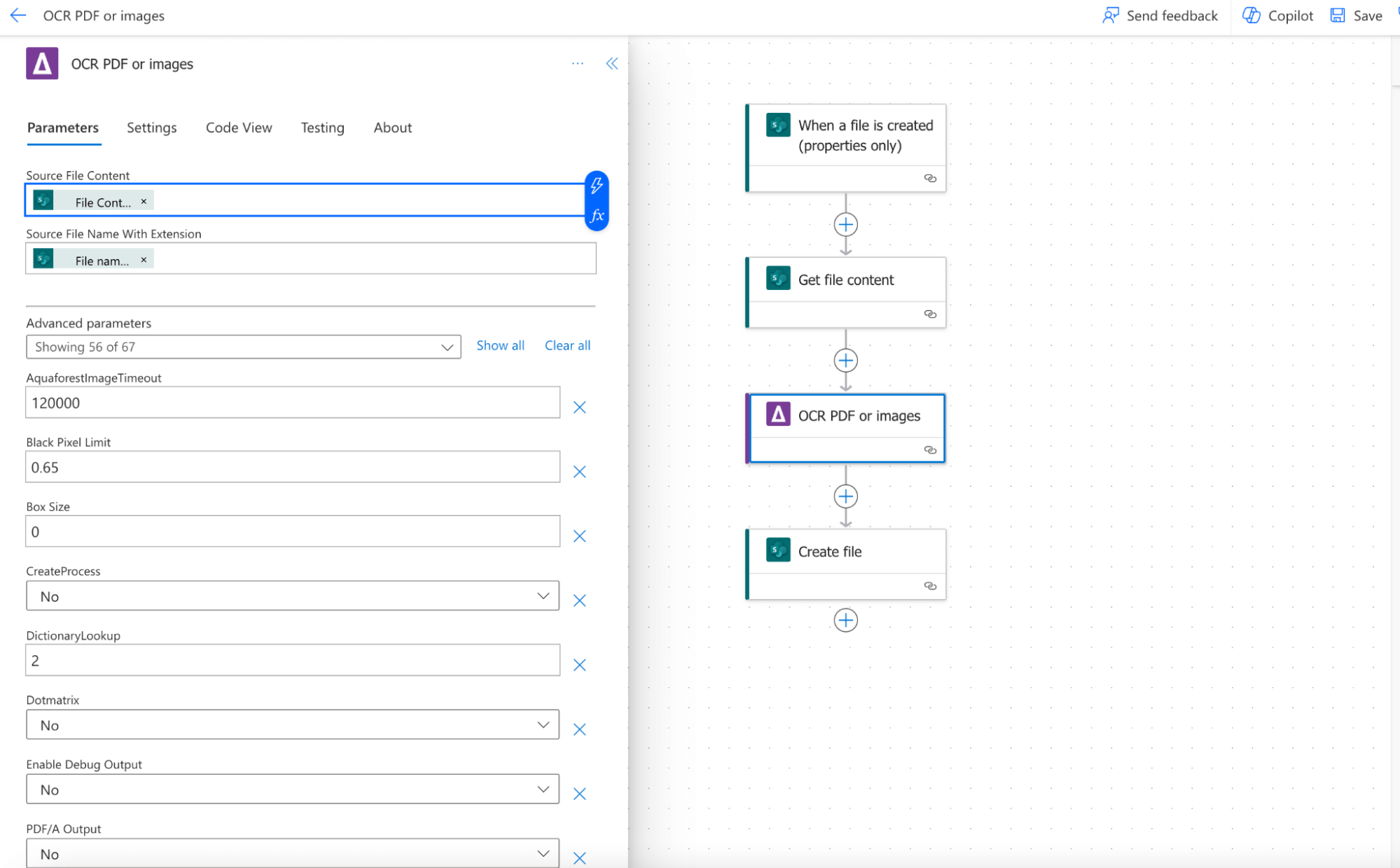
Enter the source file name or content for the patient record to be digitized.
- Source File Content: Content of the file to OCR. Click on the thunder sign and type File content to find the proper value.
- Source File Name with Extension: The name of the patient record file. Click on the thunder sign and type “File name with extension”, then click Add.
Step 3. Configure advanced parameters.
The two parameters above are mandatory but there are many other optional parameters. Check out here for more details. Define OCR settings, such as language preferences, auto-rotate, binarize, and more.
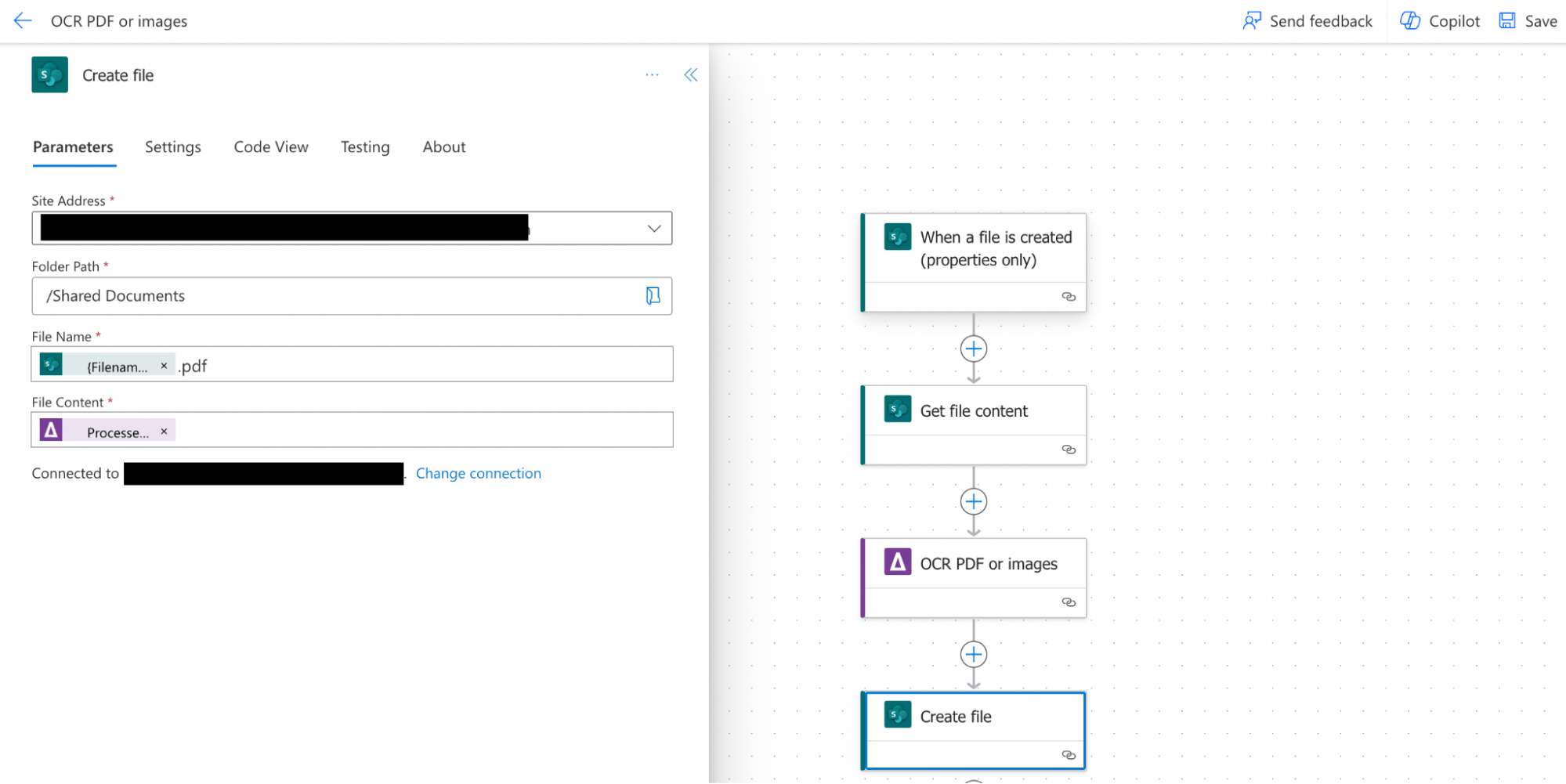
Step 4. Create file action.
Add the create file action and configure following the details below:
Site address: The URL of your SharePoint site.
Folder path: The location of your SharePoint library where the output file will be stored. You need to store the OCRed PDF file into a different folder, or otherwise it will create an indefinite loop and the flow will be running all the time.
File name: The name of the OCRed PDF file. Click on the thunder sign and open Dynamic content. Type “File name with extension” in the search bar and click on Add. Then add “.pdf” value as well.
File content: Click on the thunder sign and open Dynamic content. Click on See More to show all the output parameters and then click on Processed file content and confirm by clicking on the Add button.
- Processed File Content: The PDF file generated by the Aquaforest PDF Connector.
You can also check other output parameters:
- Log File Content: The log contents of the operation.
- Error Message: Error message returned by the operation.
- Is Successful: Whether the operation was successful or not.
- License Info: Information about your API subscription key, including LicenseType, CallsRemaining, CallsMade, and RenewalDate.
Step 5. Execute the Action.
Click on the Save button and run the Power Automate workflow to execute the “OCR PDF or Images” action.
Step 6. Review Output.
Check the output for the OCR-processed patient record, now in a searchable format, including the extracted text.
Conclusion
By incorporating the Aquaforest PDF Connector(opens in a new tab)’s “OCR PDF or Images” action into healthcare workflows, you can significantly enhance efficiency and accessibility in managing patient records. This user guide provides a comprehensive walkthrough of the action, empowering healthcare professionals to embrace OCR technology for improved patient care.


