




How to split PDFs using Python
Table of contents

Split PDF documents using our split PDF Python API. Create a free account, get API credentials, and implement splitting using the requests library. Combine with 30+ other API tools for merging, watermarking, and page manipulation.
Split PDF files using our split PDF Python API. Start with 50 free credits — no payment required. Different operations consume different credit amounts, so the number of PDF documents you can generate will vary. Create a free account(opens in a new tab) to get your API key.
Nutrient DWS Processor API
Document splitting is just one of our 30+ PDF API tools. You can combine our splitting tool with other tools to create complex document processing workflows, such as:
- Converting MS Office files and images into PDFs and splitting them
- Performing OCR on documents and splitting them
- Watermarking and flattening PDFs and splitting them
Step 1 — Creating a free account on Nutrient
Go to our website(opens in a new tab), where you’ll see the page below prompting you to create your free account.
Once you’ve created your account, you’ll see a page showing an overview of your plan details.
You’ll start with 50 credits to process and can access all our PDF API tools.
Step 2 — Obtaining the API key
After verifying your email, get your API key from the dashboard. In the menu on the left, click API keys. You’ll see the following page with an overview of your keys.
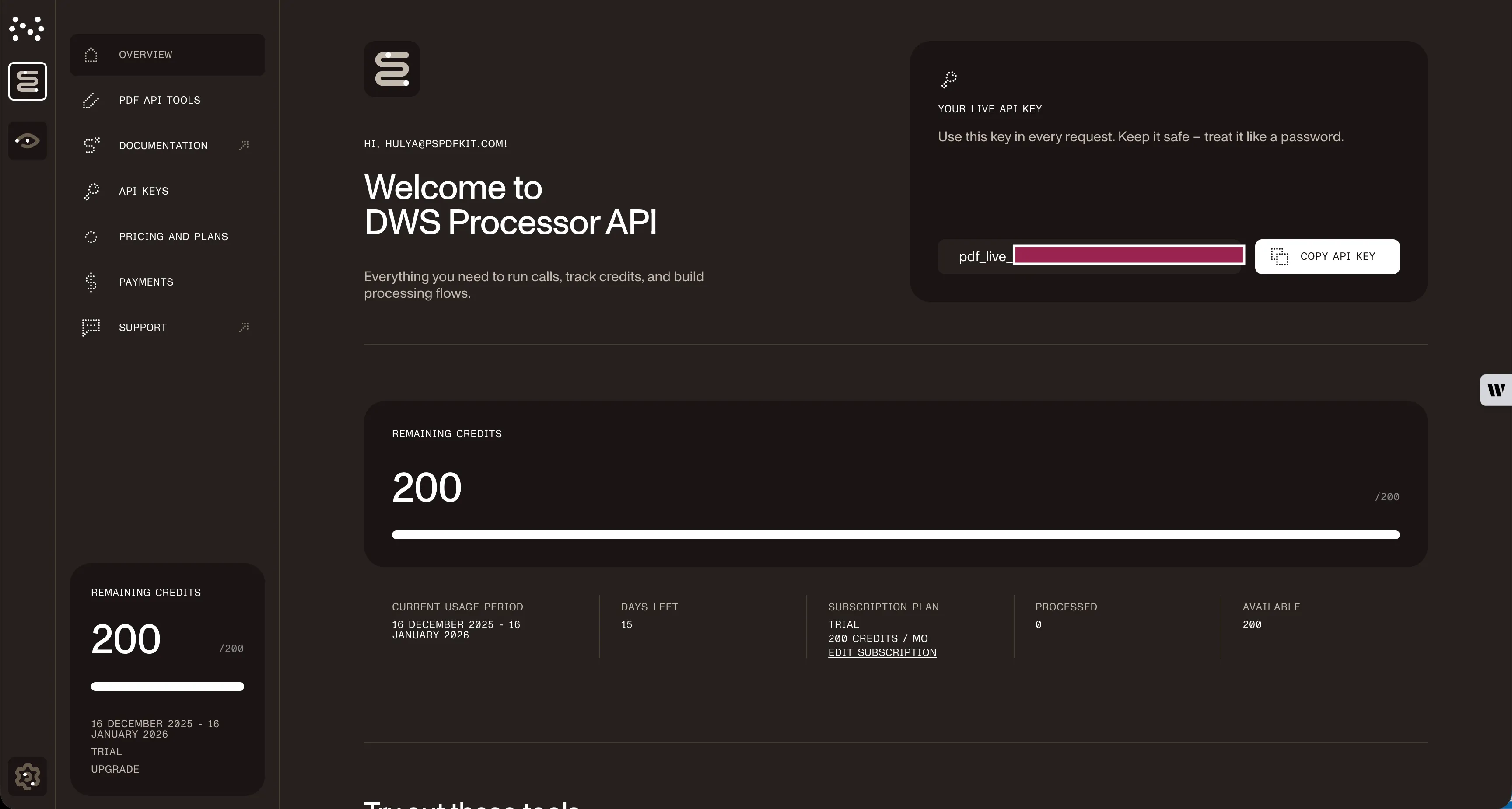
Copy the Live API key — you’ll need it for the split PDF API.
Step 3 — Setting up folders and files
Create a folder called split_pdf and open it in a code editor. For this tutorial, use VS Code as your code editor. Create two folders inside split_pdf and name them input_documents and processed_documents. Copy your PDF to the input_documents folder and rename it to document.pdf.
In the root folder, split_pdf, create a file called processor.py. This is where you’ll keep your code.
Your folder structure will look like this:
split_pdf├── input_documents├── processed_documents└── processor.pyStep 4 — Writing the code
Open the processor.py file and paste the code below into it:
import requestsimport json
def process_first_half(): response = requests.request( 'POST', 'https://api.nutrient.io/build', headers = { 'Authorization': 'Bearer YOUR_API_KEY_HERE' }, files = { 'document': open('input_documents/document.pdf', 'rb') }, data = { 'instructions': json.dumps({ 'parts': [ { 'file': 'document', 'pages': { 'end': -6 } } ] }) }, stream = True )
if response.ok: with open('processed_documents/first_half.pdf', 'wb') as fd: for chunk in response.iter_content(chunk_size=8096): fd.write(chunk) else: print(response.text) exit()
def process_second_half(): response = requests.request( 'POST', 'https://api.nutrient.io/build', headers = { 'Authorization': 'Bearer YOUR_API_KEY_HERE' }, files = { 'document': open('input_documents/document.pdf', 'rb') }, data = { 'instructions': json.dumps({ 'parts': [ { 'file': 'document', 'pages': { 'start': -5 } } ] }) }, stream = True )
if response.ok: with open('processed_documents/second_half.pdf', 'wb') as fd: for chunk in response.iter_content(chunk_size=8096): fd.write(chunk) else: print(response.text) exit()
process_first_half()process_second_half()Make sure to replace YOUR_API_KEY_HERE with your API key.
Code explanation
You created two functions: process_first_half and process_second_half. These functions perform the same operation. First, you create a variable called instructions, which contains instructions for processing the PDF file, including the offset for your page-splitting operation. Then you use the requests module to make the API call to our split PDF API. The result is saved to the processed_documents folder.
Output
To execute the code, use the command below:
python3 processor.pyOnce the code successfully executes, you’ll see two new files in the processed_document folder: first_half.pdf and second_half.pdf. The folder structure will look like this:
split_pdf├── input_documents├── processed_documents| └── first_half.pdf| └── second_half.pdf└── processor.pyAdditional resources
Explore more ways to work with Nutrient API:
- Postman collection — Test API endpoints directly in Postman
- Zapier integration — Automate document workflows without code
- MCP Server — PDF automation for LLM applications
- Python client — Official Python library
Conclusion
You’ve learned how to split PDF files for your Python application using our split PDF API.
Integrate these functions into your existing applications. With the same API token, you can perform other operations like merging documents into a single PDF, adding watermarks, and more. To get started with a free trial, sign up(opens in a new tab) here.
FAQ
Nutrient DWS Processor API offers 30+ PDF operations, including merging, watermarking, OCR, flattening, and converting Office documents to PDF. You can combine these operations in a single workflow. For example, split a PDF, watermark each part, and then merge specific sections back together — all through the same API.
Yes! Use our Postman collection to test all API endpoints directly in Postman. Import the collection, add your API key, and experiment with different operations and parameters. This helps you understand the API before integrating it into your Python application. You can also test using tools like cURL or HTTPie in your terminal.
Use our Zapier integration to automate PDF processing without writing code. Connect Nutrient DWS Processor API with 5,000+ apps like Google Drive, Dropbox, Gmail, and Slack. For example, automatically split PDFs when they’re uploaded to Google Drive, or split invoices from email attachments and save them to separate folders.
Make separate API calls for each page you want to extract. For a single page, specify {"pages": {"start": 1, "end": 1}} in the instructions. To extract pages 1, 3, and 5 as separate files, make three individual API calls with different output filenames. Use a Python loop to automate this process and save each page with a numbered filename.
Negative page numbers count from the end of the document. -1 is the last page, -2 is the second-to-last page, and so on. In the example code, {"end": -6} gets all pages except the last 5 pages, while {"start": -5} gets only the last 5 pages. This is useful when you don’t know the total page count.


