




NULL-Characters in Strings and Tales of Apple Radar
Table of contents

We’re finally dropping iOS 11 support in the PSPDFKit SDK. While there’s nothing major in terms of new features for iOS 12, doing this helps us remove old workarounds for system-level bugs. Apple didn’t drop any devices with the iOS 12 release, so everybody running iOS 11 can upgrade to iOS 12. (While there are no official statistics for iOS 11 usage, it seems to already be below one percent(opens in a new tab).)
Our Process
Whenever we drop an iOS release, we take time to carefully modernize the codebase, remove deprecations, and adopt new APIs. This is important for keeping technical debt low and ensuring the codebase remains a comfortable place to work in.
The first step in removing iOS 11 was running a full-text search for “iOS 11” in the codebase. We documented version-specific issues, and in the process, I found something I’d long forgot about:
/** Returns a string that has been cleaned of '\0' characters. Guarantees to return a copy.
iOS 11 made it easy to create them: https://github.com/PSPDFKit/PSPDFKit/issues/12280 rdar://34651564 http://openradar.appspot.com/34651564 March 22, 2018: Verified to be fixed at least as of iOS 11.3b6. */@property (nonatomic, readonly) NSString *pspdf_nullCharacterCleanedString;In iOS 11, Smart Punctuation caused data loss when the dash key was tapped three times with the US English keyboard. We take data-loss issues seriously and quickly shipped a workaround for this OS-level bug.
Radar Time
We have strict rules for working around OS bugs. One of them is the requirement of submitting a great b̶u̶g̶ ̶r̶e̶p̶o̶r̶t̶ Feedback Assistant entry(opens in a new tab) to Apple, both to report and to document the issue. (Since this issue was reported in 2017, it was converted from Radar to Feedback Assistant — more specifically, FB5735669.)
Apple’s How to file great bug reports(opens in a new tab) article is a great resource to learn how bug reports should look like.
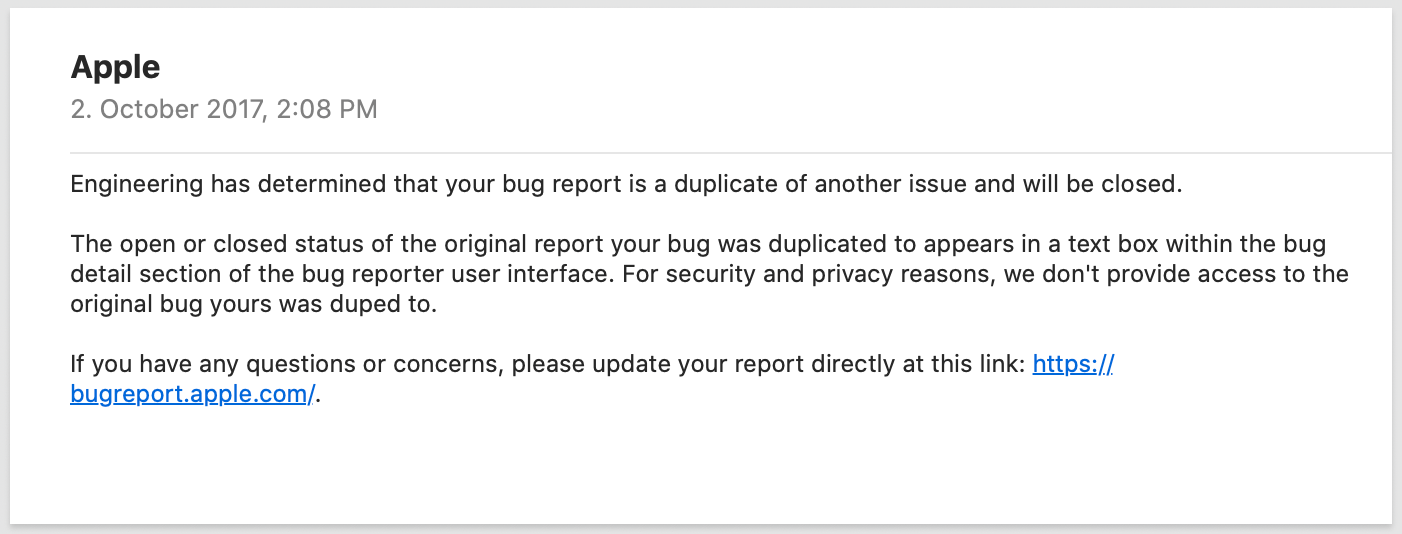
Apple followed up on this issue saying it had been reported before. However, when I look at the header of Feedback Assistant, I see this:
Recent Similar Reports: NoneResolution: OpenIs that the case though? The comment in our codebase mentions this is fixed. And, as a matter of fact, I am unable to reproduce this with an OS other than iOS 11.0. (We keep devices with older OS versions around so we can test.)
It’s unfortunate that Apple’s bug reporting process is so dysfunctional. This ticket should show the correct state (closed) and that similar reports are attached, but something fell apart with either closing the original ticket or because of the mapping from Radar to Feedback Assistant.
Another option would be to maintain a public database of known issues, or to make it easier to share issues publicly. Apple does that to a degree (with WebKit(opens in a new tab), with Swift(opens in a new tab), and in the Xcode release notes), but not for OS-level issues.
We indeed can no longer reproduce this issue, and it seems to be fixed in iOS 11.1. But why are NULL bytes even a problem? They are invisible after all.
NULL Bytes in Strings?
C-based strings are NULL-terminated. If we create a string in code, the compiler automatically appends \0 at the end:
char cString[] = "A\0BC"; // 5 bytes in memory: A\0BC\0printf("string: %s", cString); // outputs: string: ANSString is more sophisticated; it is a class cluster(opens in a new tab) — using different representations,<sup id=“a1”>1</sup> depending on the content. All of these variants are toll-free bridged to CFString.
Depending on the backend, different backing stores are used. CFString uses 16-bit UniChars(opens in a new tab) (UTF-16). CFString stores length in a variable, so accessing it is O(1), where C-based string functions need to iterate on the string to find the NULL-termination \0 character, making strlen(opens in a new tab) an O(n) operation.<sup id=“a2”>2</sup>
String in Swift
Swift has a modern String object(opens in a new tab) (e.g. using grapheme clusters(opens in a new tab) for better Unicode/emoji support), but it behaves similar to Objective-C in the case of NULL:
NSString *string = @"A\0BC";NSLog(string); // prints "ABC"NSLog(@"%@", string); // prints "A"printf(string.UTF8String); // prints "A"NSLog gets the Swift case right, whereas the string is cut off in the Objective-C example above. This is likely related to using os_log(opens in a new tab) and how it prints NSStrings: (Thanks to Jeff Johnson(opens in a new tab) for testing this!)
let string = "A\u{0}BC";print(string). // prints "ABC"print("\(string)") // prints "ABC"NSLog("%@", string) // prints "ABC"NSLog("%@", string as NSString) // prints "ABC"
string.withCString { cstr in // prints "A" print("\(String(cString: cstr)), len: \(strlen(cstr))")}However, you generally want to avoid NULL characters in your strings. They trigger bugs, e.g. SR-11355: String.range(of…) matches an extra NUL (and returns range outside string boundaries)(opens in a new tab). I’m sure we could find more issues with some digging.
std::string in C++
The most common way to store strings in C++ is std::string(opens in a new tab). Reading the implementation is extremely difficult(opens in a new tab), but there are much more readable(opens in a new tab) explanations of its internals.
std::string operates on bytes — not on characters or even graphemes. While there are different storage modes, both include a size field and do not rely on a NULL termination.
To bridge between Objective-C and C++, we use Djinni(opens in a new tab), which uses Objective-C++ to conveniently translate between these types. The below code is slightly simplified, removing assertions:
static std::string toCpp(NSString* string) { return {string.UTF8String, [string lengthOfBytesUsingEncoding:NSUTF8StringEncoding]};}
static NSString* fromCpp(const std::string& string) { return [[NSString alloc] initWithBytes:string.data() length:static_cast<NSUInteger>(string.size()) encoding:NSUTF8StringEncoding];}This converts losslessly between the two representations:
NSString *string = @"A\0BC";std::string cppString = toCpp(string);std::cout << cppString; // prints ABCNSString *nsString = fromCpp(cppString);NSLog(nsString); // prints ABCStrings in PDF
Now why is \0 still a problem? The PDF format has two ways to encode strings: name and string.
Name objects allow ASCII characters, with the exception of \0, while other characters are encoded — for example, #20 for space. This is generally used for keys and not longer-form text.
String objects are (usually) encoded between ( and ) and support all characters, including NULL bytes. However, we project both data types to String/NSString in our iOS SDK, so as to not burden developers with additional complexity. So depending on what property is accessed, \0 would be silently discarded or not.
In practice, we have some more parsing and optimized code that uses C strings for performance. Our parsing code runs everywhere, including WebAssembly in modern browsers. In this layer, strings are truncated early when a \0 is found.
Conclusion
We decided to remove the code that would manually check for NULL characters at the API boundary — if developers really include NULL characters, we accept that the string is truncated. As you learned today, inserting NULL characters in strings does work, but it’s generally a bad idea, due to bugs and pitfalls that pop up when converting them to other string storage variants. Now that this bug has been fixed and can no longer be triggered from the user interface, removing our checks is a better tradeoff than reducing performance just so everyone can work around an edge case.
<span id=“f1”>1</span> __NSLocalizedString(opens in a new tab), NSLocalizableString(opens in a new tab), NSPlaceholderString(opens in a new tab), __NSCFConstantString, __NSCFString and NSTaggedPointerString, and more. Tagged pointers(opens in a new tab) are an interesting technology used to increase performance and reduce memory usage. ↩
<span id=“f2”>2</span> There are many interesting ways to speed up strlen. While Clang’s libc uses a straightforward loop with a todo for performance optimization(opens in a new tab), GCC’s glibc tests four bytes at a time(opens in a new tab) (see here for an explanation of how this works(opens in a new tab)), and OpenBSD has hand-optimized code for some architectures, such as arm64(opens in a new tab). ↩


