




Extract tables from PDF with Nutrient Document Web Services API on Zapier
Table of contents

What is Zapier?
Zapier(opens in a new tab) is a no-code automation tool that connects your favorite apps and services. You can create workflows (“Zaps”) that automate actions between tools like Google Drive, Gmail, Slack, Notion, and more.
What is Nutrient DWS Processor API?
Nutrient Document Web Services API provides more than 30 document automation tools for PDFs, images, and Office files. With your free account(opens in a new tab), you get 200 credits to experiment with:
- Converting documents to/from PDF
- Extracting tables, text, or metadata
- Adding digital signatures or redactions
- Running OCR, annotations, and form actions
What you’ll need
- A Zapier(opens in a new tab) account (a pro plan is necessary for multistep Zaps)
- A Google Drive account
- A PDF file stored in Google Drive (table content inside)
- A Nutrient DWS Processor API key — get one here(opens in a new tab)
Step 1 — Trigger a new file in a Google Drive folder
- Select Google Drive as the trigger app.

- Choose the New File in Folder trigger event.
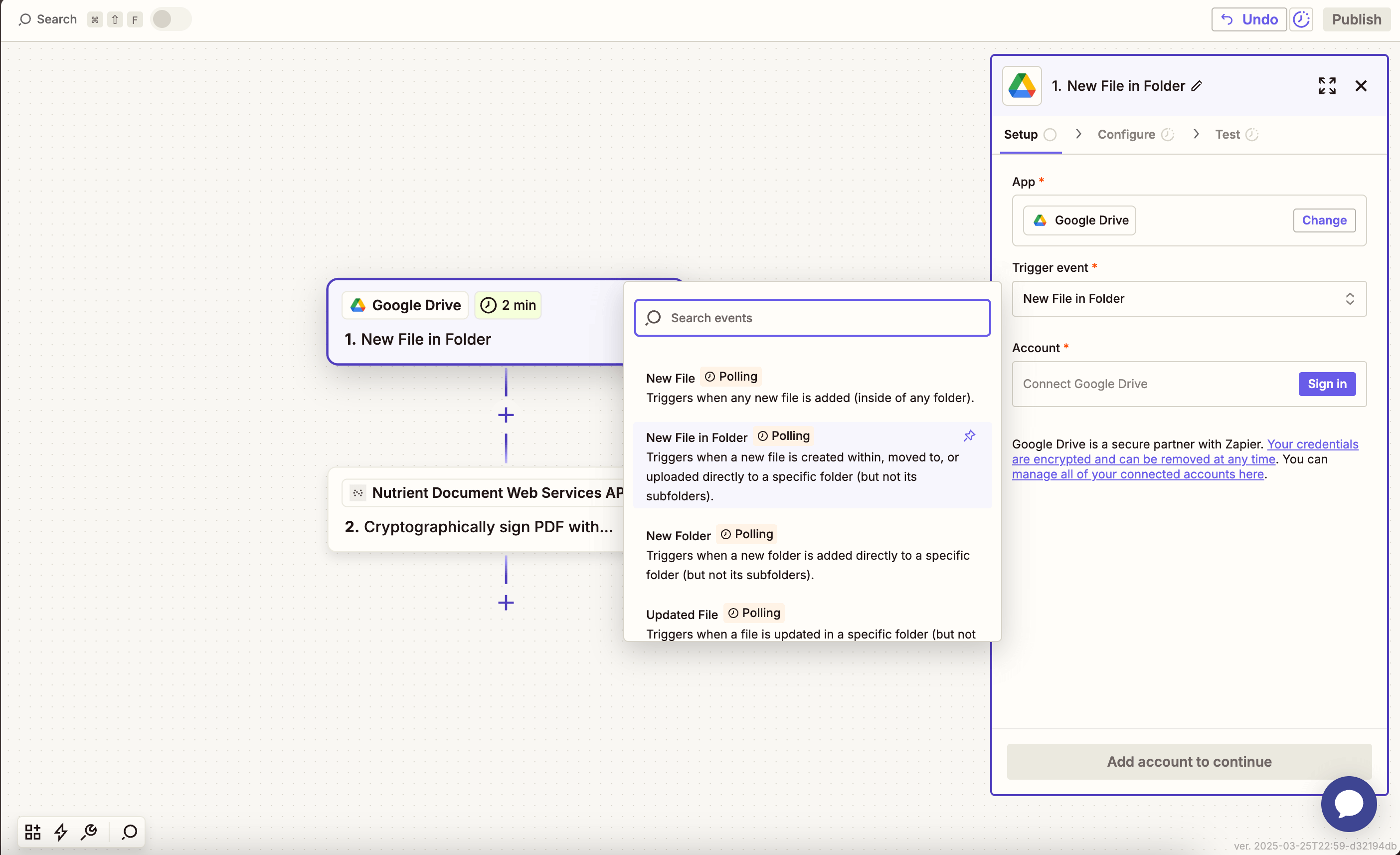
- Connect your Google Drive account.
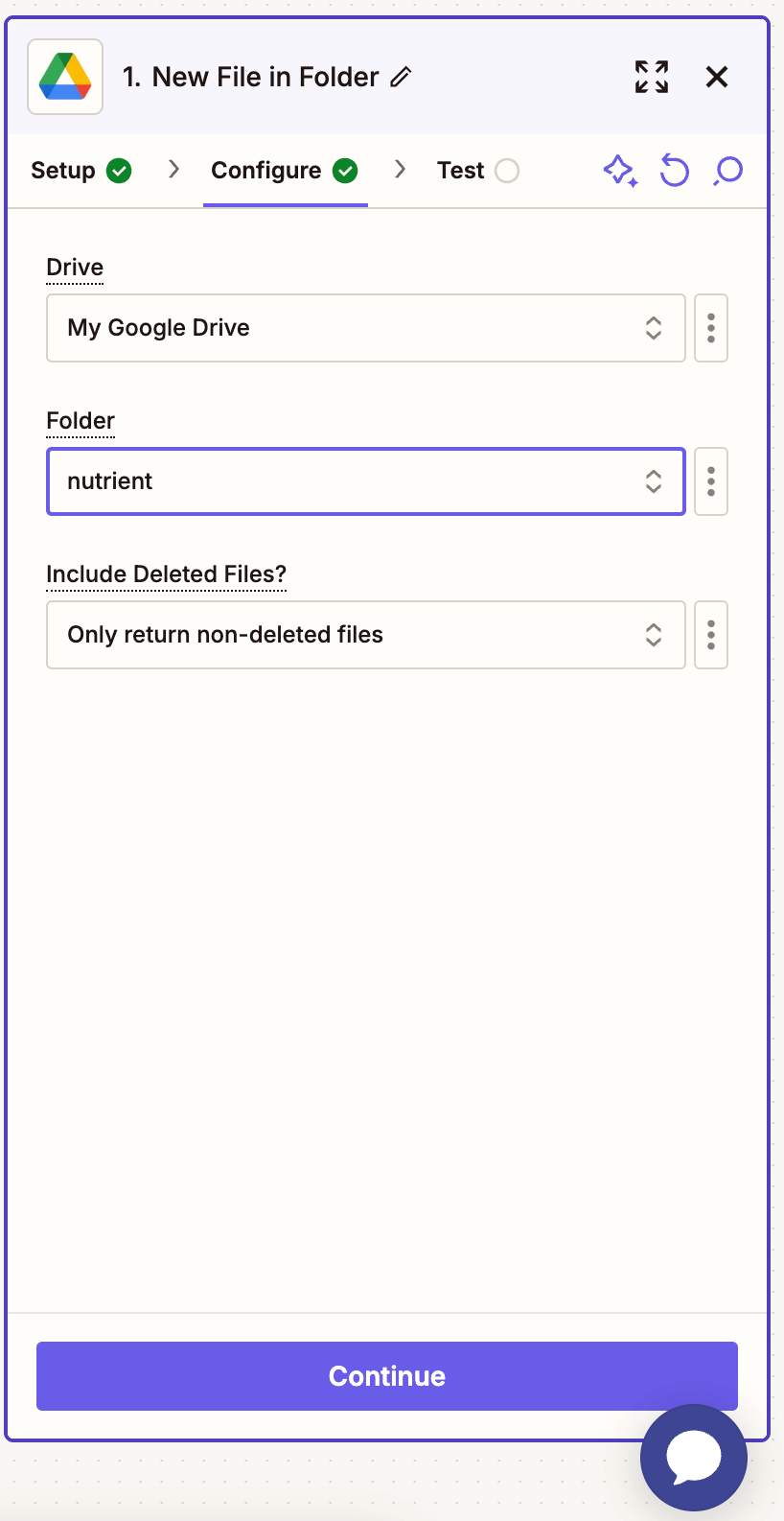
- Configure the trigger:
- In the Drive field, select your Google Drive.
- Select or create a folder where PDFs with tables will be uploaded (e.g.
/extract-tables).
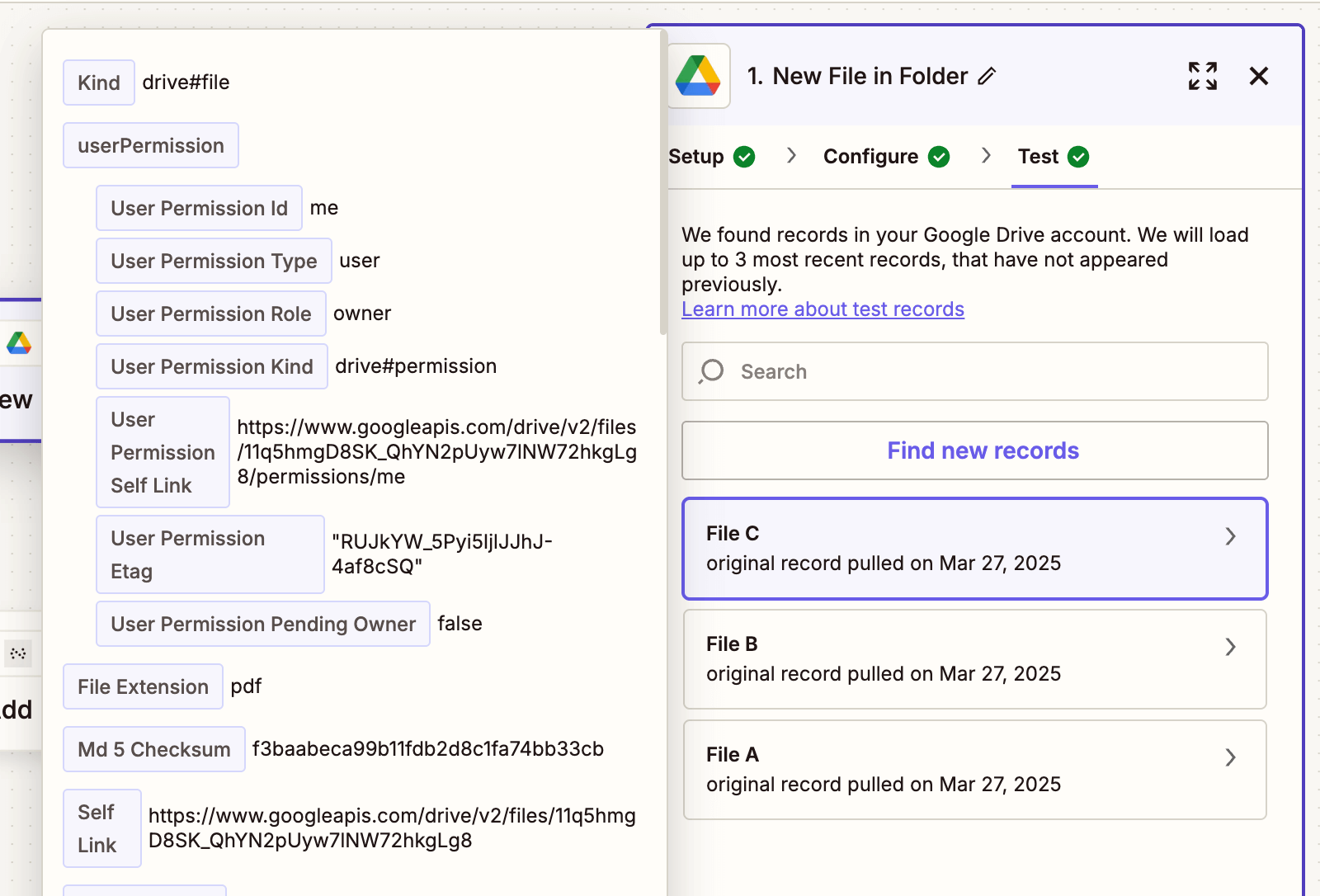
- Test with a sample PDF containing tables.
Step 2 — Extract tables from PDF
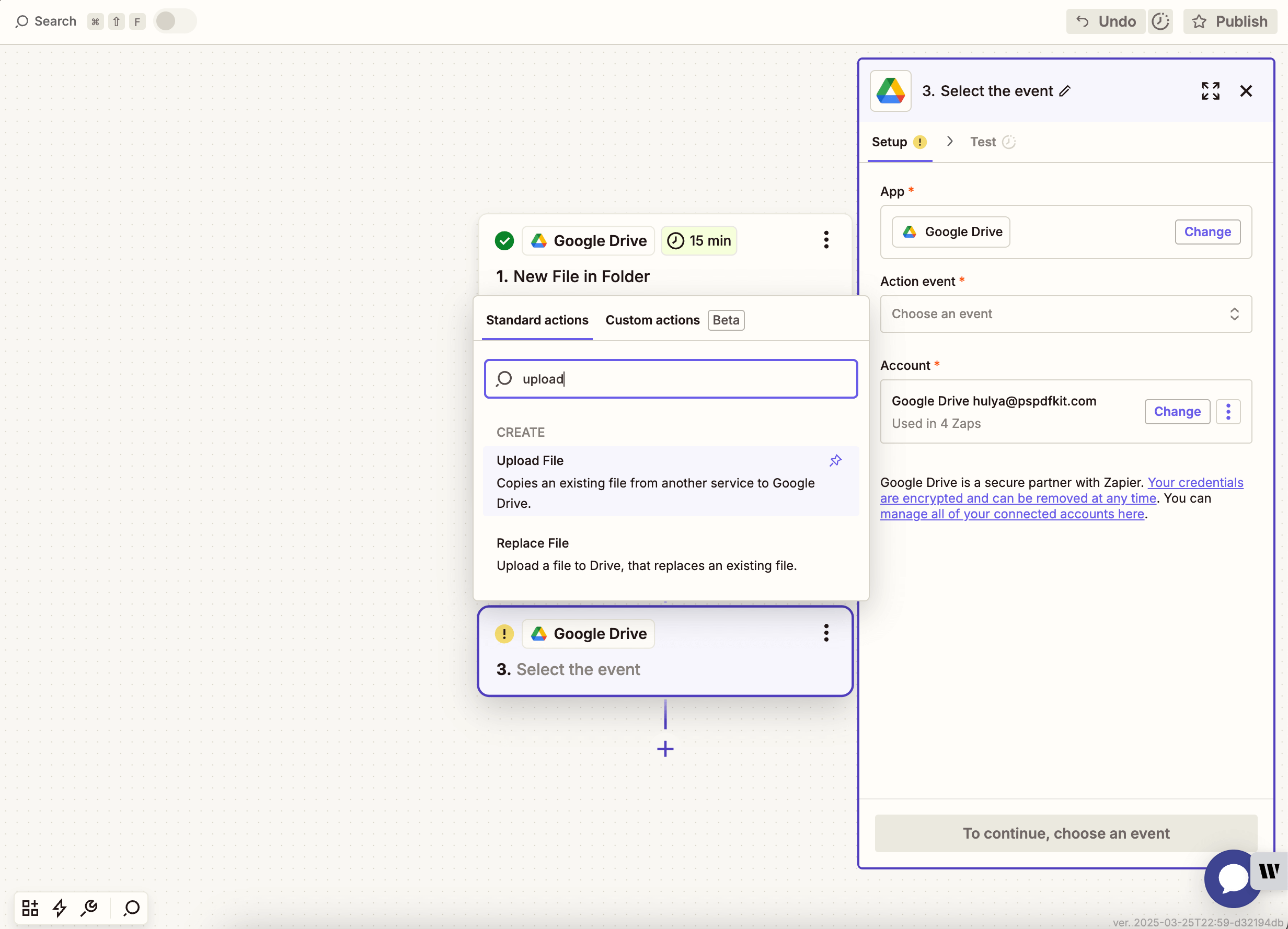
- Choose Nutrient Document Web Services API as the action app.
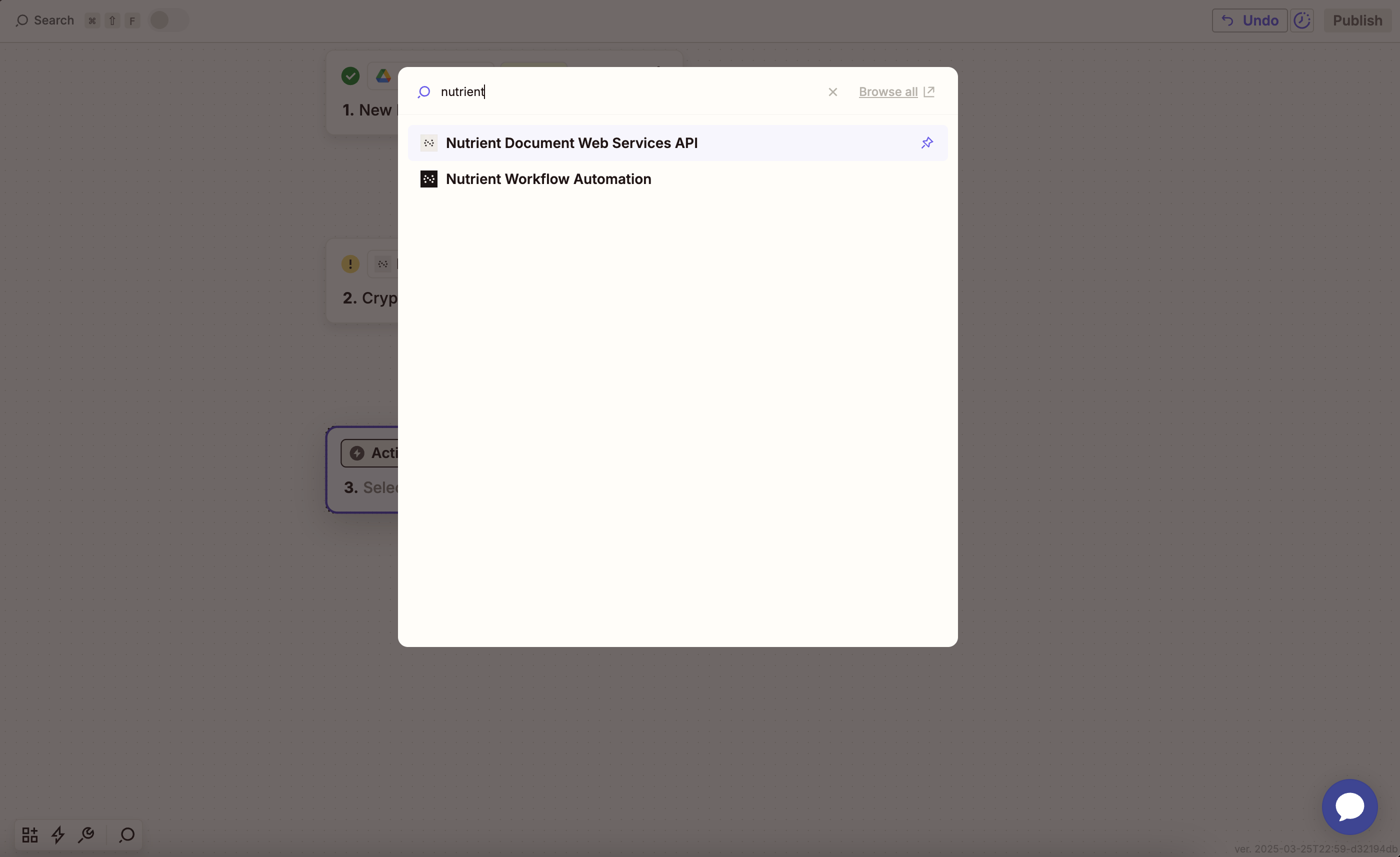
- Select the Extract Tables from PDF action.
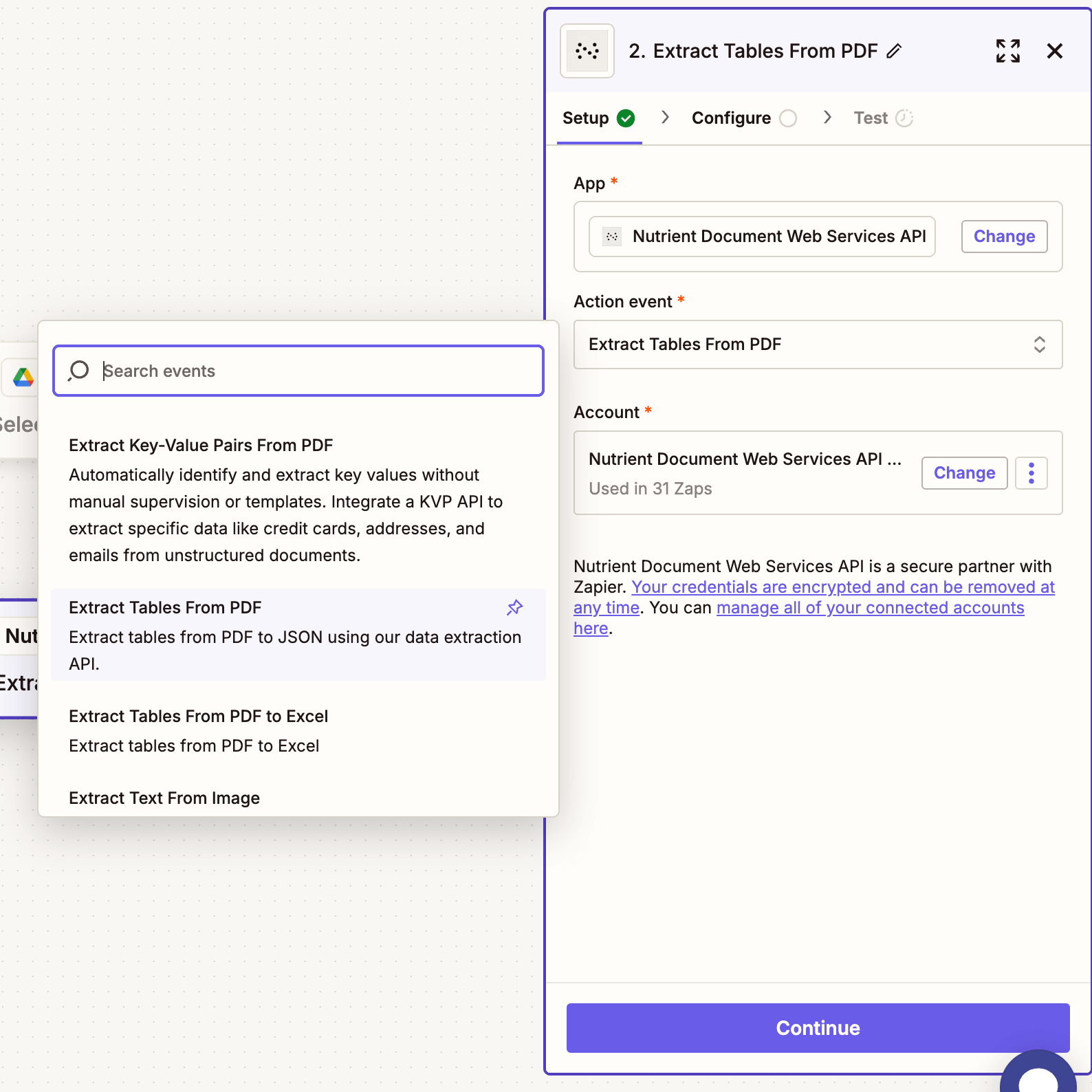
- Connect your Nutrient DWS Processor API account using your API key.
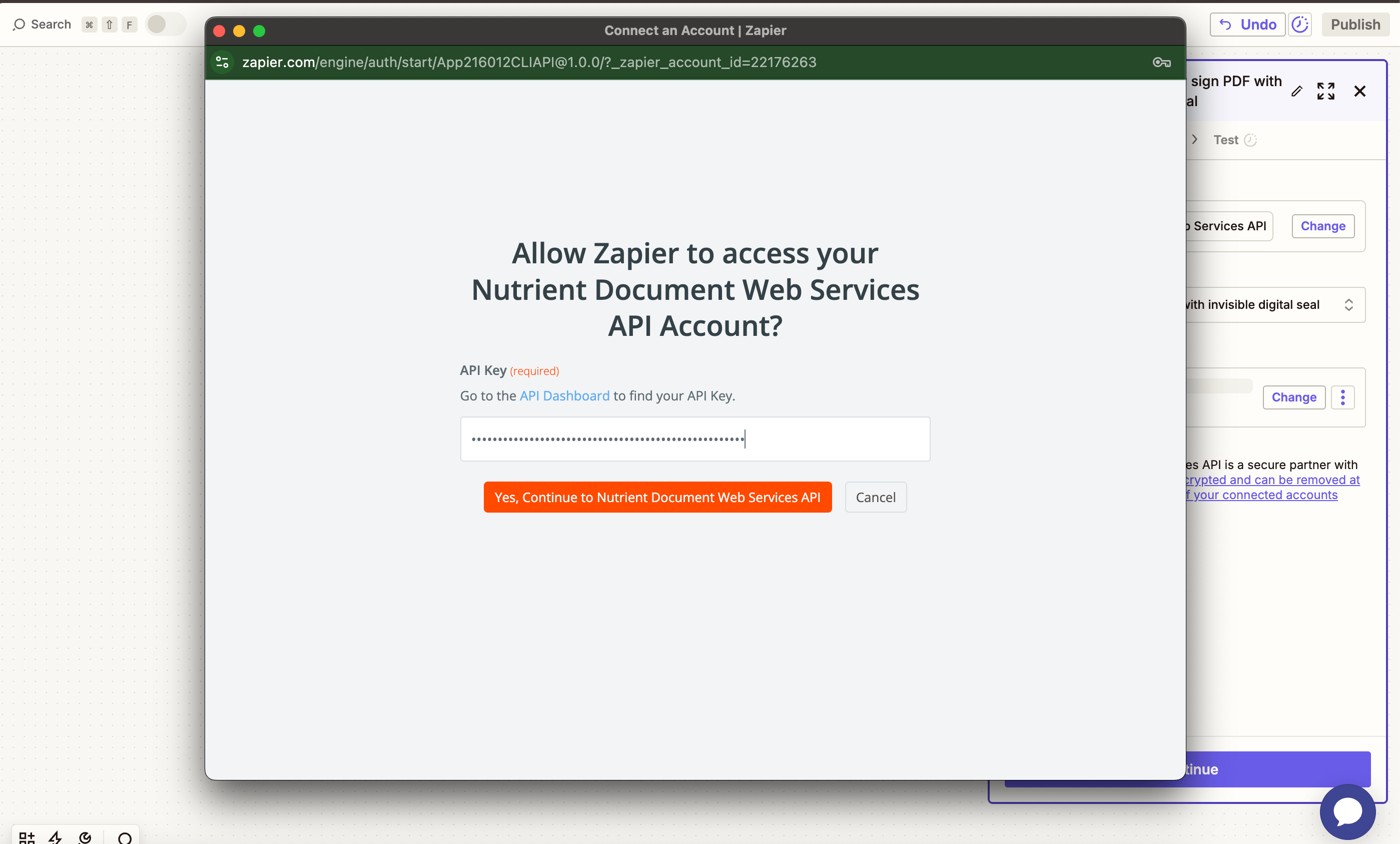
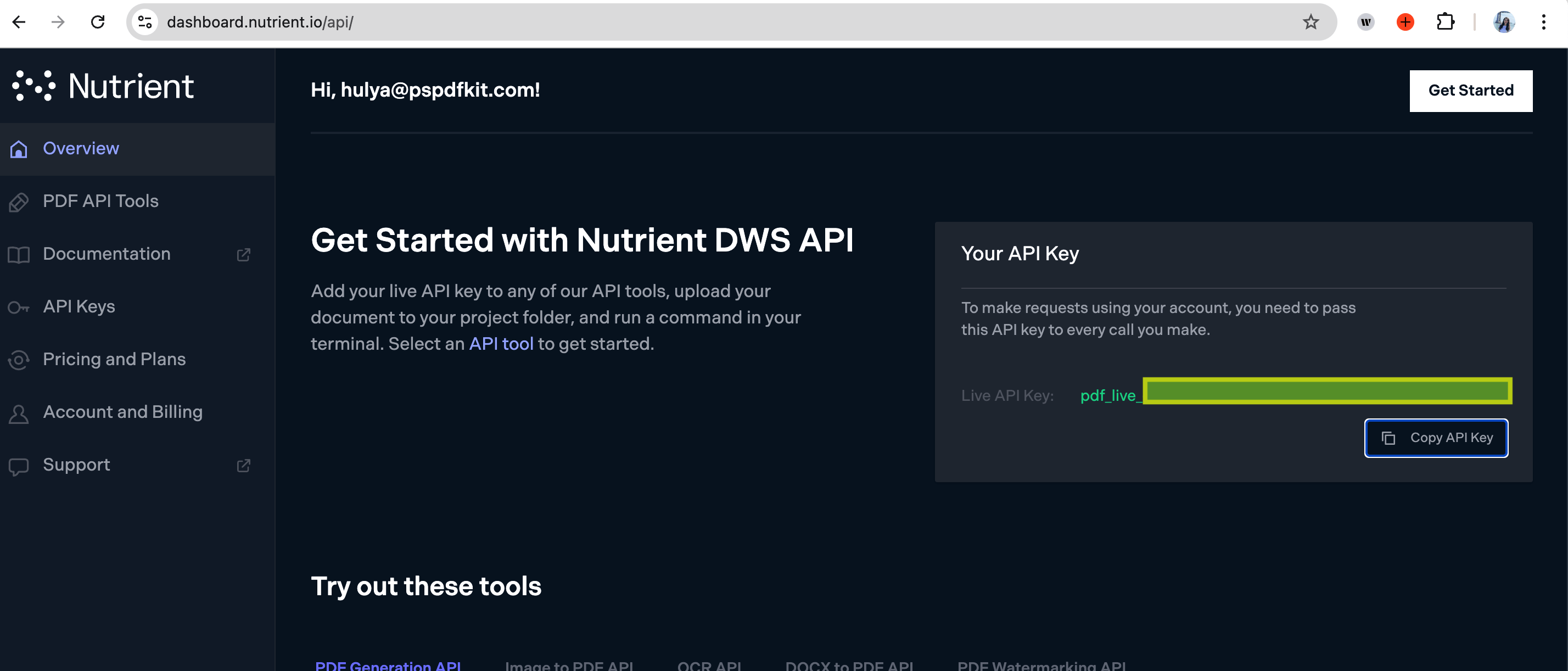
You can find your API key in the Nutrient dashboard(opens in a new tab).
- Fill out the fields:
- PDF File URL — From step 1 (Google Drive trigger).
- Output File Name — Optional (e.g.
extracted_table.json).
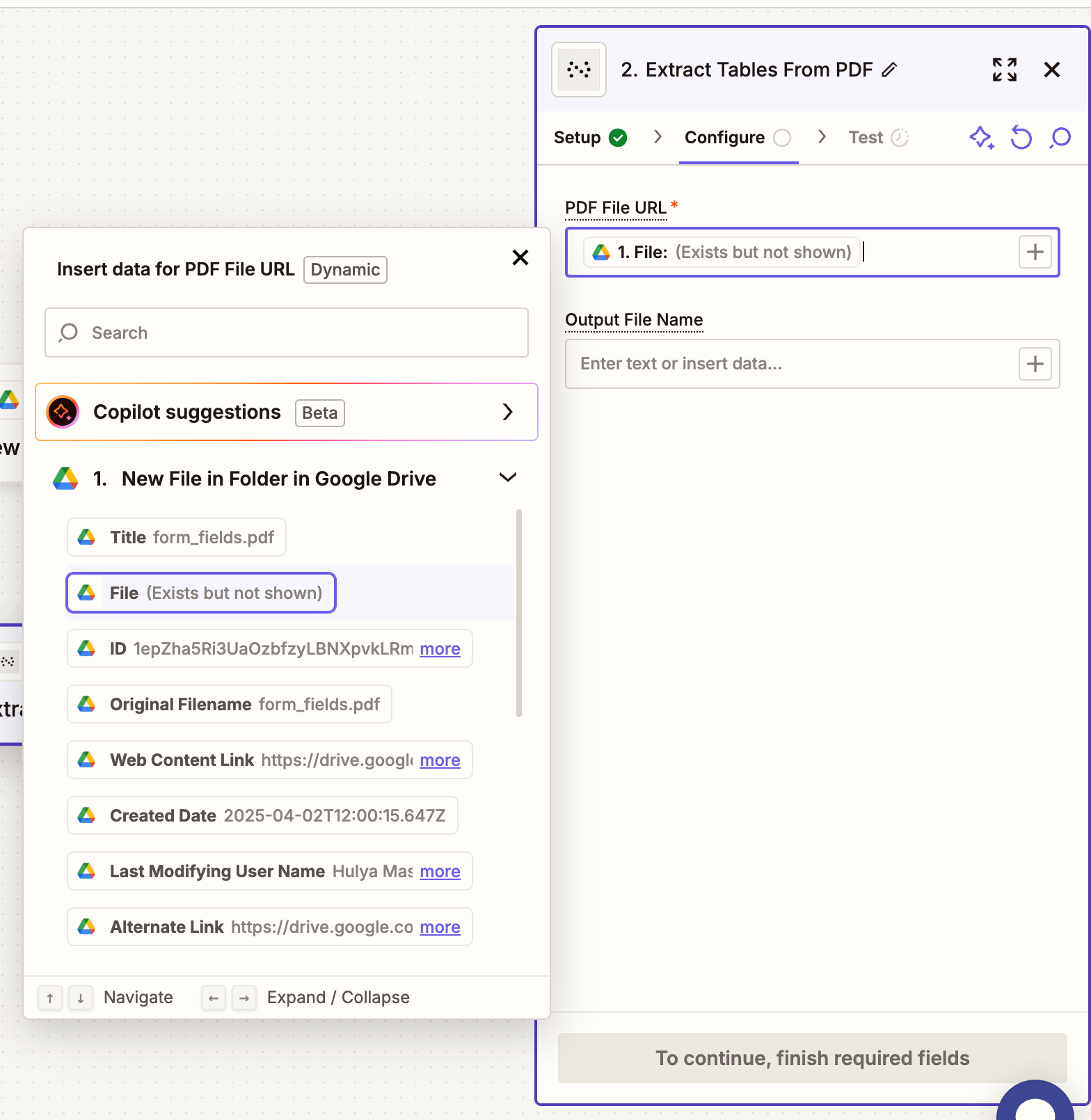
Ensure the PDF is publicly accessible via URL or shared through Zapier’s Google Drive integration.
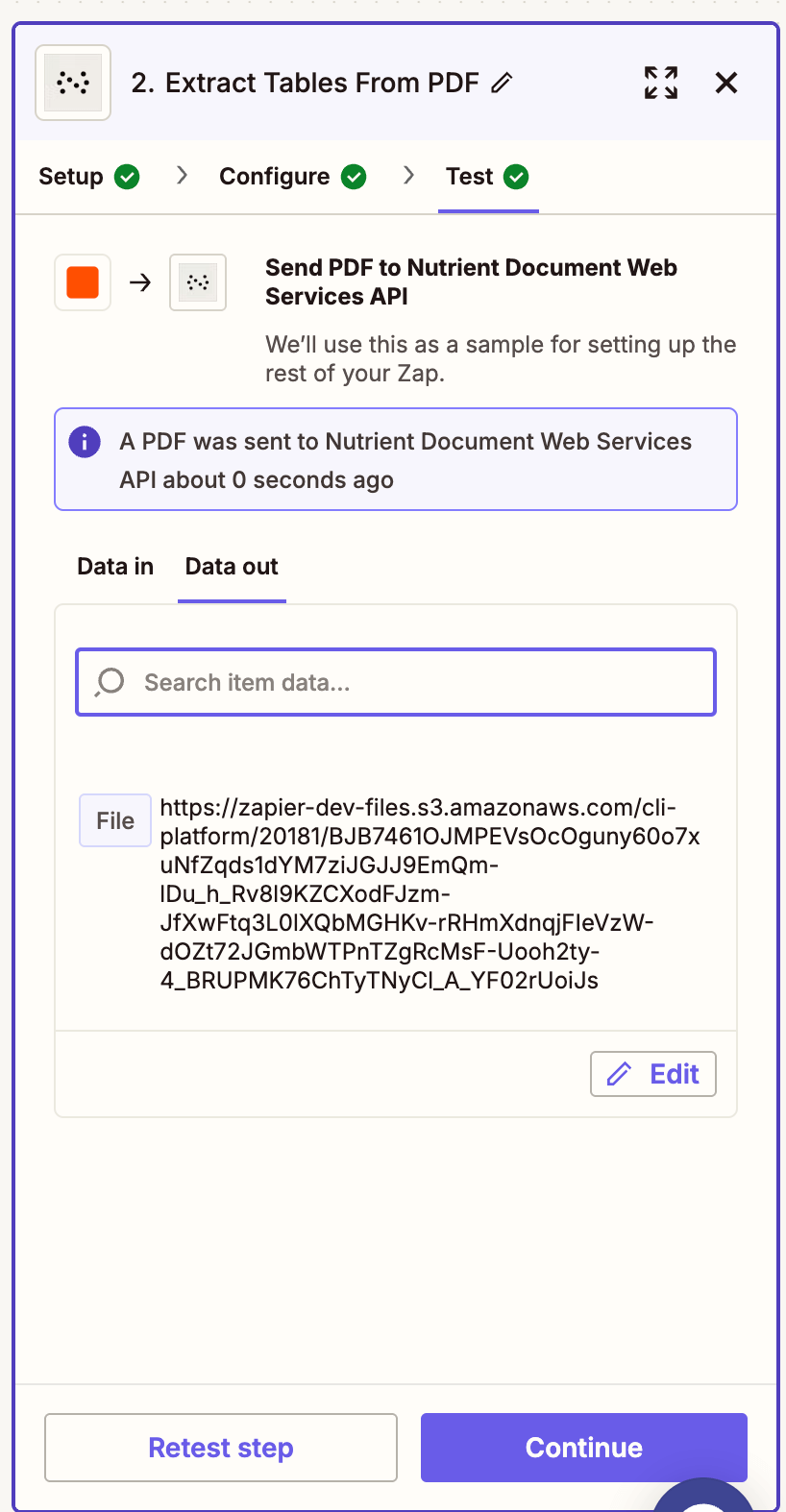
- Test the step. The result will be a structured JSON file containing extracted table data.
Step 3 — Upload the extracted table to Google Drive
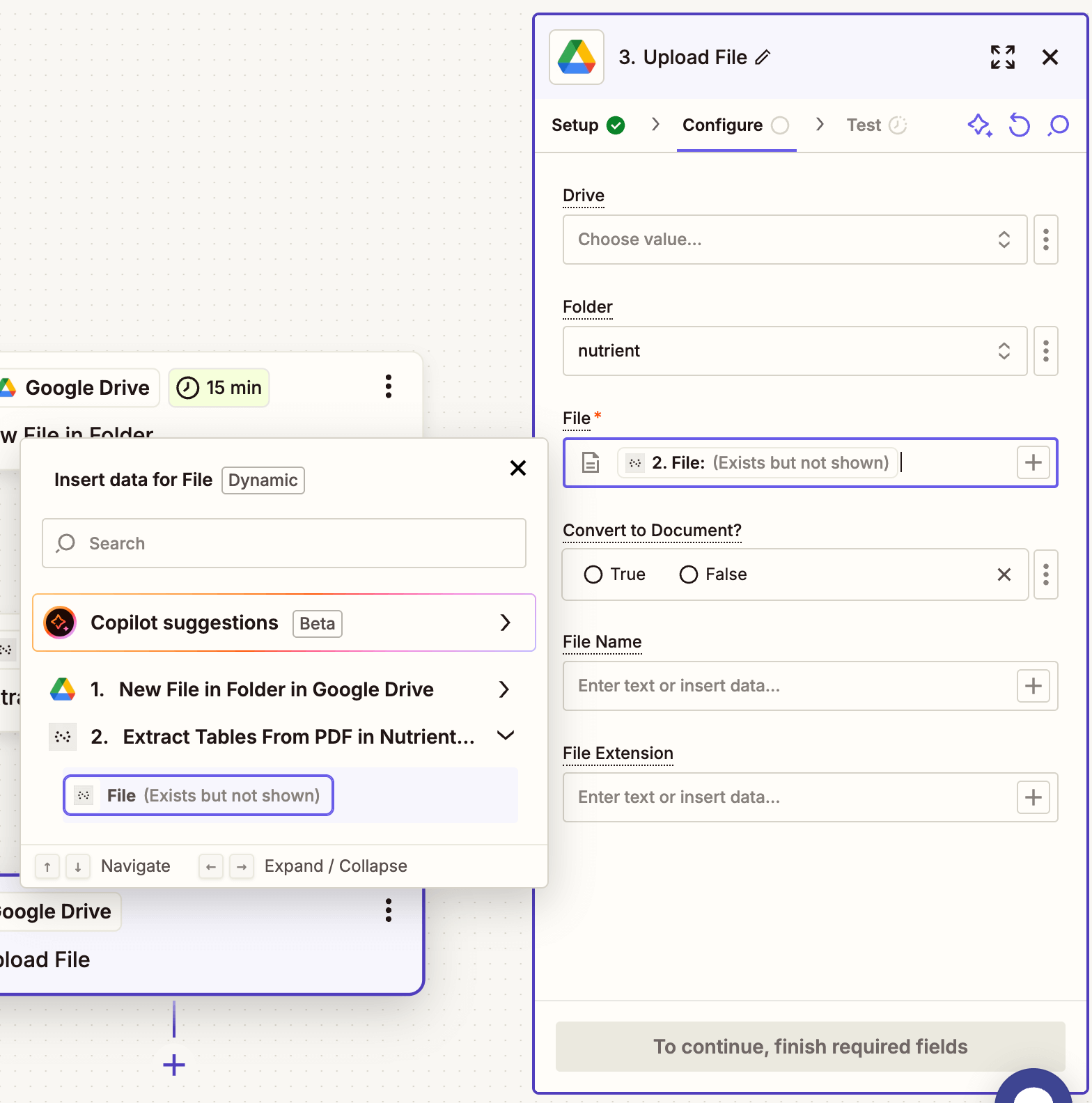
- Add Google Drive as the final app and select Upload File.
- Configure:
- Drive — Select your drive.
- Folder — Choose a destination like
/extracted-json. - File — Use the output from step 2 (JSON file).
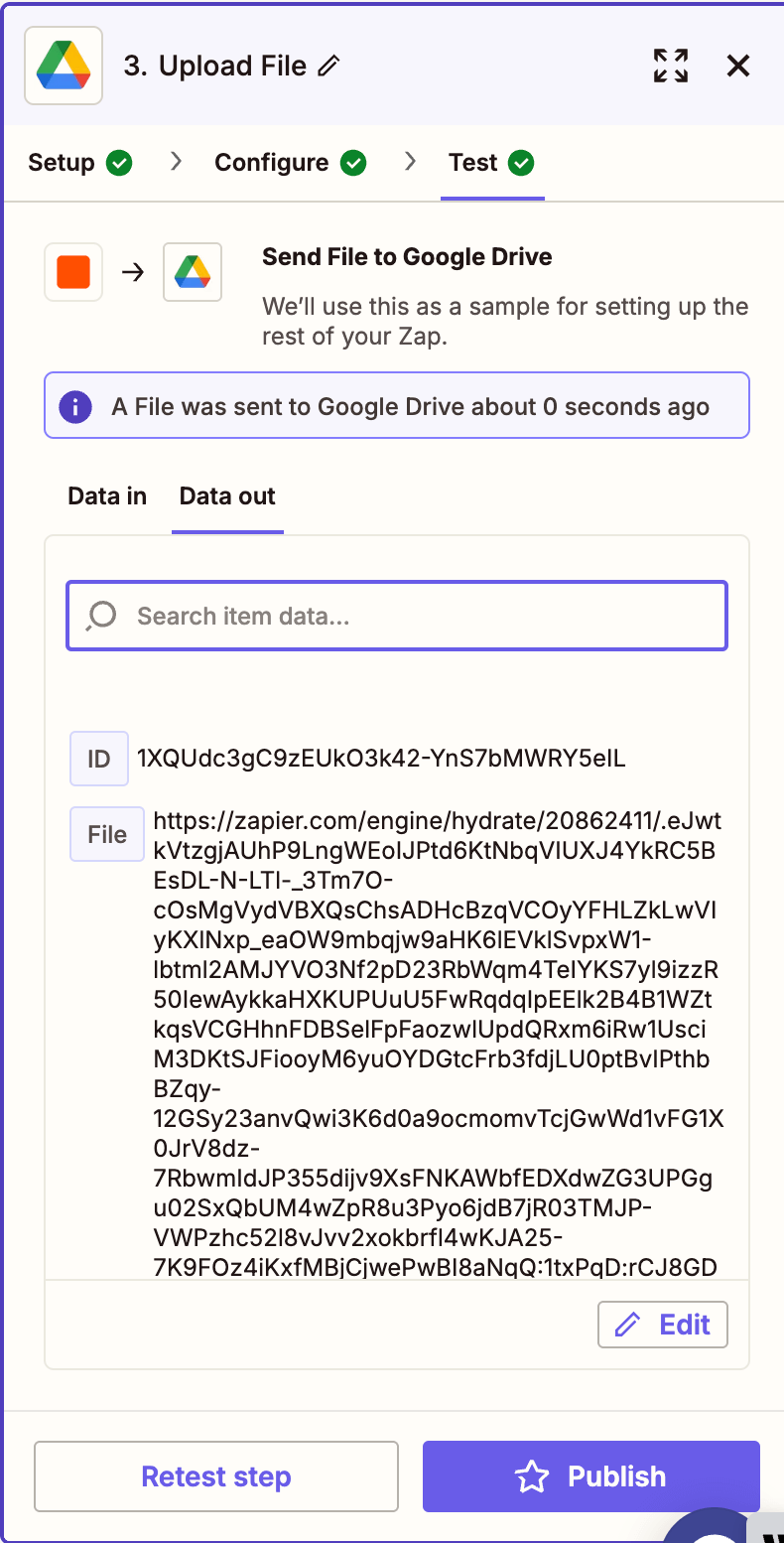
- Run a test to confirm the JSON file is uploaded to drive.
Conclusion
You’ve now automated the process of extracting tabular data from PDFs and saving it as a JSON file using Zapier(opens in a new tab) and Nutrient DWS Processor API(opens in a new tab). This workflow is perfect for pulling out table-based data from receipts, invoices, reports, or financial documents. Enhance this workflow with OCR text recognition, table-to-Excel extraction, or key-value pair extraction for even more data capture capabilities.
You can expand this Zap to:
- Add parsed data to Google Sheets(opens in a new tab).
- Send alerts when new tables are extracted.
- Automatically archive or analyze extracted tables using other apps.


