How to Extract Text from a PDF
Table of contents
Extracting text from a PDF can be more challenging than expected. PDF files are designed to preserve document appearance rather than facilitate text extraction. In this post, we’ll explore how to extract text from a PDF effectively and see how PSPDFKit’s advanced features make this process easier.
Understanding the Challenges of Text Extraction from PDFs
PDFs are primarily created for consistent visual presentation across different devices. This design focus makes text extraction from PDFs complex, as PDFs aren’t optimized for this purpose.
How Text Is Represented in a PDF
A PDF file doesn’t simply contain text as you’d be used to in a text file. What it does contain are commands on how to render the given text on the screen without whitespace characters or newlines. But let’s dive a little bit deeper into some PDF internals to further our understanding of this.
Content Streams
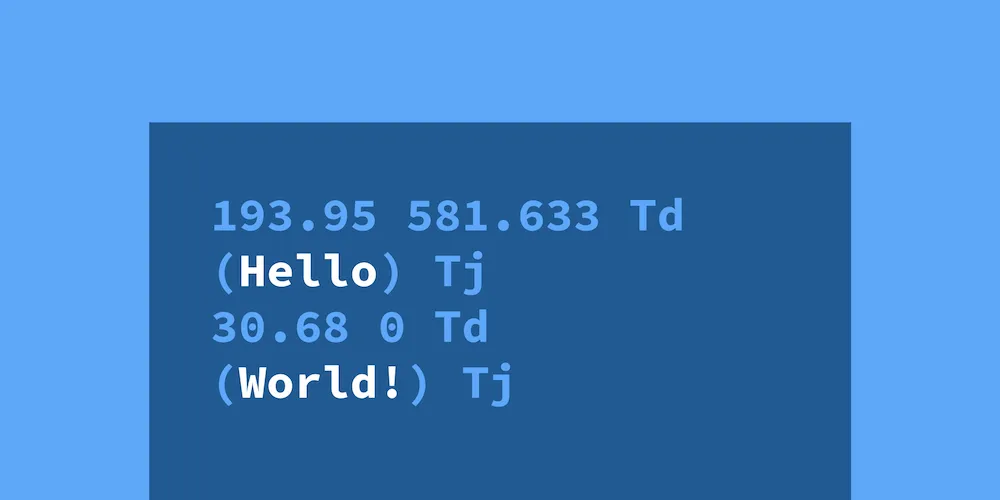
Each page in a PDF has one or more content streams that tell the PDF viewer application how to render a page. A very simple one might look like this:
193.95 581.633 Td(Hello) Tj30.68 0 Td(World!) TjThese content streams can be represented differently while accomplishing the same goal, like this:
193.95 581.633 Td<00290046004d004d00500001003800500053004d0045> TjTd instructs the PDF viewer where to draw the next string. Tj specifies which string to draw.
Extracting Text from a Content Stream
The only way to extract text from a PDF is by looking at the rendering commands and having a good heuristic try at making sense of it. In the example above, we know we’re supposed to render Hello, reposition the text cursor, and then output World!.
You might have noticed there’s no whitespace in the first example above. Because the content stream only instructs the rendering engine what to draw on the screen, and because whitespace is blank, we have to infer the spaces and newlines ourselves most of the time.
Doing this reliably across all the different PDF documents out there is difficult, and it’s not uncommon to encounter problems where tweaking the heuristic breaks one document but fixes another.
PSPDFKit for Modern Text Extraction
PSPDFKit offers APIs to retrieve text from a document. All of our platforms use the same underlying heuristic to determine the layout of the text on the page and how to extract blocks out of it.
iOS
On iOS, you can use PSPDFTextParser to retrieve the text, text blocks, words, or glyphs from a page:
guard let textParser = documentProvider.textParserForPage(at: 0) else { // Handle failure. abort()}print("Text of page 0: \(textParser.text)")
for textBlock in textParser.textBlocks { print("TextBlock at \(textBlock.frame): \(textBlock.content)")}Android
On Android, there’s no dedicated text parser class; instead, you retrieve your page text using PdfDocument:
val pageText = document.getPageText(0)print("Text of page 0: $pageText")
for (textRect in document.getPageTextRects(0, 0, pageText.length)) { val blockText = document.getPageText(0, textRect) print("TextBlock at $textRect: $blockText")}Web
PSPDFKit for Web can extract the text from a page using textLinesForPageIndex, but there isn’t yet an API for extracting text blocks:
const textLines = await instance.textLinesForPageIndex(0);textLines.forEach((textLine) => console.log(textLine.contents));instance.textLinesForPageIndex(0).then(function (textLines) { textLines.forEach(function (textLine) { console.log(textLine.contents); });});Conclusion
Learning how to extract text from a PDF involves understanding the complexities of PDF design and using the right tools. PSPDFKit offers modern solutions to make this process as seamless as possible, helping you focus on your core tasks. This text extraction capability also powers our PDF text comparison feature for identifying differences between document versions.
FAQ
Why is extracting text from PDFs so difficult?
PDFs are designed for visual consistency rather than text extraction. The text is often encoded in ways that can make it challenging to extract accurately.
How does PSPDFKit handle text extraction?
PSPDFKit uses advanced algorithms to interpret the rendering commands in PDFs and retrieve text with high accuracy across different platforms.
Can PSPDFKit handle all PDFs for text extraction?
While PSPDFKit is highly effective, text extraction can vary depending on the complexity and encoding of a PDF. Our tools continuously improve to handle a wide range of documents.