




Extract text from PDF files using PDF.js and JavaScript
Table of contents

This tutorial demonstrates two approaches for extracting text from PDFs using JavaScript: PDF.js (open source) and Nutrient SDK (commercial). With PDF.js, you’ll implement text extraction using getTextContent() and promises to process multiple pages. While PDF.js works well for basic extraction, Nutrient offers better handling of complex layouts, a simpler API with textLinesForPageIndex(), and additional features like annotations and multi-format support.
In this post, you’ll learn how to extract text from PDF documents using JavaScript. It’ll cover open source solutions for extracting text, as well as how to extract text with Nutrient’s JavaScript PDF library. By the end, you’ll have a complete client-side JavaScript-based solution for extracting text from PDF documents.
It’s important to note that there are two different types of text extraction:
- Extracting text that’s already selectable in a PDF viewer. PDFs are usually made up of text authored in a Word processing program.
- Extracting text from an image-based PDF document. PDFs are typically made up of images from documents that are scanned.
This post will focus on extracting text that’s already selectable.
Requirements
PDF.js(opens in a new tab) will be the only dependency in this project, and it’ll provide you with all the necessary tools to load a PDF and extract the text from within it.
You can either download the library or you can use this content delivery network (CDN) link:
<script type="module"> import * as pdfjsLib from 'https://mozilla.github.io/pdf.js/build/pdf.mjs';</script>PDF.js makes use of web workers to do PDF processing. This helps ensure the main thread doesn’t get blocked. You also need to load the web worker code, which can be done by assigning the worker URL to pdfjsLib.GlobalWorkerOptions.workerSrc:
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://mozilla.github.io/pdf.mjs/build/pdf.worker.mjs';Move the code into an index.html HTML file and add the appropriate HTML tags. You’ll end up with something like this:
<!DOCTYPE html><html> <head></head>
<body> <!-- Load the pdf.js library as a module --> <script type="module"> import * as pdfjsLib from 'https://mozilla.github.io/pdf.js/build/pdf.mjs';
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://mozilla.github.io/pdf.js/build/pdf.worker.mjs'; </script> </body></html>Loading the PDF file
Now that you have the main imports set up, you can continue writing code for loading a PDF file. Create a new function called extractText that will load the PDF and return the extracted text from within it:
function extractText(pdfUrl) { var pdf = pdfjsLib.getDocument(pdfUrl);
return pdf.promise.then(function (pdf) { var maxPages = pdf.numPages; console.log(maxPages); });}
// Example PDF file.const url = 'https://raw.githubusercontent.com/mozilla/pdf.js/ba2edeae/web/compressed.tracemonkey-pldi-09.pdf';
extractText(url).then( function (text) { console.log('parse ' + text); }, function (reason) { console.error(reason); },);PDF.js relies heavily on promises, and you can see the first example of that in the extractText function. So far, it does nothing more than printing the total page count of the PDF file. The PDF file you’re using is a research paper with a decent amount of text, and it’s provided for free by Mozilla.
Extracting text from a PDF file using JavaScript
Now, update the extractText function to do the actual text extraction. You’ll be primarily relying on the getTextContent(opens in a new tab) method to do the heavy lifting:
function extractText(pdfUrl) { var pdf = pdfjsLib.getDocument(pdfUrl); return pdf.promise.then(function (pdf) { var totalPageCount = pdf.numPages; var countPromises = []; for ( var currentPage = 1; currentPage <= totalPageCount; currentPage++ ) { var page = pdf.getPage(currentPage); countPromises.push( page.then(function (page) { var textContent = page.getTextContent(); return textContent.then(function (text) { return text.items .map(function (s) { return s.str; }) .join(''); }); }), ); }
return Promise.all(countPromises).then(function (texts) { return texts.join(''); }); });}The code is asking PDF.js to return each page one by one, and then it’s using the getTextContent method to extract text from the page. getTextContent returns a promise and adds the promise to the countPromises array. It does this to make sure all the promises have returned before returning from the extractText function.
The getTextContent promise eventually resolves to an object containing an items array, with each element in the array containing an str attribute. The image below from developer tools illustrates it better.
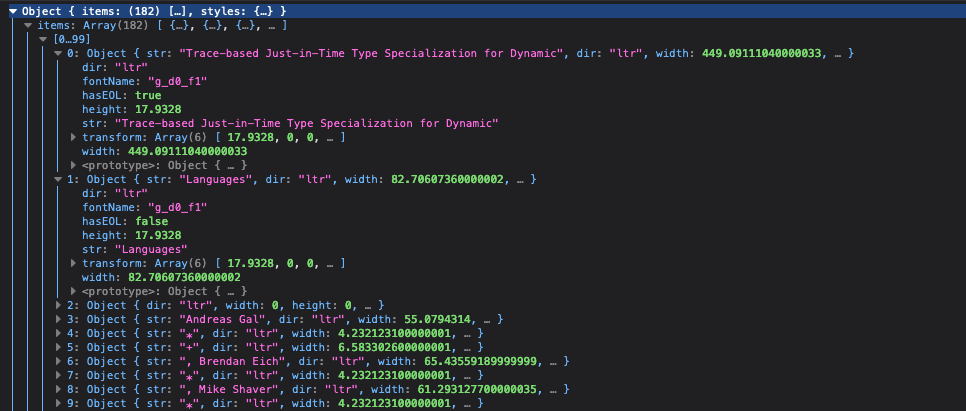
The code ensures that when the getTextContent promise returns, it merges all the str attributes in a single string. This way, all the text from a page is one really long string.
Finally, the following piece of code makes sure that, when all the promises have returned, even the individual page strings are merged into a single, longer string containing text from all the pages:
Promise.all(countPromises).then(function (texts) { return texts.join('');});Complete code
You have all the bits and pieces now. The complete code looks something like this:
<!DOCTYPE html><html> <head></head>
<body> <!-- Load the pdf.js library as a module --> <script type="module"> import * as pdfjsLib from 'https://mozilla.github.io/pdf.js/build/pdf.mjs';
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://mozilla.github.io/pdf.js/build/pdf.worker.mjs';
function extractText(pdfUrl) { var pdf = pdfjsLib.getDocument(pdfUrl); return pdf.promise.then(function (pdf) { var totalPageCount = pdf.numPages; var countPromises = []; for ( var currentPage = 1; currentPage <= totalPageCount; currentPage++ ) { var page = pdf.getPage(currentPage); countPromises.push( page.then(function (page) { var textContent = page.getTextContent(); return textContent.then(function (text) { return text.items .map(function (s) { return s.str; }) .join(''); }); }), ); }
return Promise.all(countPromises).then(function (texts) { return texts.join(''); }); }); }
const url = 'https://raw.githubusercontent.com/mozilla/pdf.js/ba2edeae/web/compressed.tracemonkey-pldi-09.pdf';
extractText(url).then( function (text) { console.log('parse ' + text); }, function (reason) { console.error(reason); }, ); </script> </body></html>Save this code in an HTML file and open it in the browser. If it runs successfully, you’ll see something like this in the console.

PDF.js vs. Nutrient
PDF.js deployment is a cost-effective solution for displaying PDF files. Once deployed, you’ll be able to:
- View PDF files
- Zoom in and out
- Add pagination
- Search words and move through searches
- Rotate pages
- Resize pages
- See fullscreen pages
- Open a new PDF file
- Download and print files
- Scroll vertically
- Scroll horizontally
However, in some situations, a commercial JavaScript PDF viewer might make better sense. The most common use cases we see are from developers who need to add features or file types that aren’t supported by PDF.js. Here are some of the top reasons our customers migrate from PDF.js to our JavaScript PDF viewer:
- Prebuilt UI — A clean and polished UI that’s easily integrated into any JavaScript application. This includes an extensive and well-documented list of APIs that can save time when customizing the UI to meet your exact requirements.
- Document annotation — 15+ prebuilt annotation tools so users can draw, circle, highlight, comment, and add notes to documents.
- Image file support — Users can view PNG, JPG, and TIFF files on the client side. With server deployment, users can view MS Office documents.
- Dedicated support — When working under tight timelines, having dedicated support from one of our developers often helps resolve integration issues faster.
- Scalable solutions —When the time is right, easily add features like PDF editing, digital signatures, form filling, real-time document collaboration, and more.
Adding Nutrient to your project
In this section, you’ll learn how to add Nutrient to your project.
- Install the
pspdfkitpackage fromnpm. If you prefer, you can also download Nutrient Web SDK manually:
npm install pspdfkit- For Nutrient Web SDK to work, it’s necessary to copy the directory containing all the required library files (artifacts) to the
assetsfolder. Use the following command to do this:
cp -R ./node_modules/pspdfkit/dist/ ./assets/Make sure your assets directory contains the pspdfkit.js file and a pspdfkit-lib directory with the library assets.
Integrating into your project
- Add the PDF document you want to display to your project’s directory. You can use our demo document as an example.
- Add an empty
<div>element with a defined height to where Nutrient will be mounted:
<div id="pspdfkit" style="height: 100vh;"></div>- Include
pspdfkit.jsin your HTML page:
<script src="assets/pspdfkit.js"></script>Extracting text from a PDF using Nutrient
Extracting text from PDF files can be a challenging task due to the complexity of the file format. Fortunately, Nutrient provides several abstractions to make this process simpler.
In a PDF, text usually consists of glyphs that are absolutely positioned. Nutrient heuristically splits these glyphs up into words and blocks of text, which makes it easier to extract meaningful text. The Nutrient user interface (UI) leverages this information to allow users to select and annotate text in a PDF file.
Follow the steps below to extract text from a PDF using Nutrient.
- Load the PDF file
The first step in extracting text from a PDF using Nutrient is to load the PDF file into your web application. You can do this using the PSPDFKit.load method, which loads the PDF and renders it in a specified container on your web page:
const instance = await PSPDFKit.load({ container: '#pspdfkit', document: 'document.pdf',});Here, you’re loading a PDF file named document.pdf and rendering it in the #pspdfkit element on your web page.
- Extract text from a specific page
Once the PDF file has been loaded, you can extract text from a specific page using the textLinesForPageIndex method. This method returns an array of text lines for a given page index, with each text line being represented as a separate string. Here’s an example:
const pageIdx = 0;const textLines = await instance.textLinesForPageIndex(pageIdx);In this example, you’re extracting text from the first page of the PDF file, which has a page index of 0. The textLines variable contains an array of text lines, which can be further processed as needed.
- Process the extracted text
Once you’ve extracted text from a PDF page using Nutrient, you can process it as needed. For example, you can concatenate the text lines into a single string, split the text into words or sentences, or use a natural language processing (NLP) library to extract named entities like people, places, and organizations.
Here’s an example of concatenating the text lines into a single string:
const text = textLines.join('\n');console.log(text);In this example, you’re joining the text lines together using a newline character as the separator. The resulting text variable contains all the text from the PDF page as a single string.
Full code example:
<!DOCTYPE html><html> <head> <title>My App</title> </head> <body> <!-- Element where PSPDFKit will be mounted. --> <div id="pspdfkit" style="height: 100vh"></div>
<script src="assets/pspdfkit.js"></script> <script> async function extractText() { try { const instance = await PSPDFKit.load({ container: '#pspdfkit', document: 'document.pdf', }); console.log('PSPDFKit loaded', instance);
const pageIdx = 0; const textLines = await instance.textLinesForPageIndex( pageIdx, ); const text = textLines.join('\n'); console.log(text); } catch (error) { console.error(error.message); } }
extractText(); </script> </body></html>And that’s it! With these simple steps, you can quickly and easily extract text from a PDF file using Nutrient.
Serving your website
You’ll use the npm serve(opens in a new tab) package to serve your project.
- Install the
servepackage:
npm install --global serve- Serve the contents of the current directory:
serve -l 8080 .- Navigate to http://localhost:8080 to view the website. It’ll look like the image below.
Conclusion
In conclusion, extracting text from PDF files can be a challenging task, but Nutrient provides several abstractions to make this process simpler. The textLinesForPageIndex method is a powerful tool for extracting text from a specific PDF page, and the /pages/:page_index/text endpoint is useful for server-based deployment. By using these tools, you can quickly and easily extract meaningful text from PDF files.
FAQ
The easiest way to extract text from a PDF using JavaScript is by using libraries like PDF.js or Nutrient. These libraries provide APIs to parse and extract text content from PDF files programmatically. Once extracted, you can leverage features like PDF text comparison to identify differences between document versions.
To set up PDF.js, you need to include the library in your project, either by downloading it or using a CDN link. Then, set workerSrc to the correct path for the PDF.js worker script. This setup is essential for handling PDF files without blocking the main thread.
You can extract text from all pages or specific pages of a PDF. By iterating through each page using the PDF.js API and calling the getTextContent method, you can retrieve the text from selected pages.
Common challenges include handling complex document layouts, non-standard fonts, and PDFs that contain images instead of selectable text. These factors can affect the accuracy of text extraction.
While PDF.js is a cost-effective solution for basic PDF viewing and text extraction, Nutrient offers additional features like a prebuilt UI, annotations, and support for various document formats. It also provides dedicated support and scalable solutions, which can be beneficial for complex use cases.
PDF.js is an open source library that provides basic PDF text extraction capabilities. In contrast, Nutrient is a commercial library that offers a more comprehensive suite of features, including text extraction, annotations, form filling, and more. It also provides better support for complex layouts and additional document types.


